SAX
... [ Seminar XML ] ... [ XML-Parser ] ... [ DOM ] ...
SAX
SAX 1.0
SAX steht für "Simple API for XML" und definiert Schnittstellen für das Parsen von XML-Dokumenten. Es ist kein W3C-Standard, sondern wurde von der XML-DEV Mailinglist entwickelt und Anfang 1998 in der Version 1.0 herausgebracht. Zur Zeit ist die Version 2.0 aktuell.
Das SAX-API stellt einen Mechanismus zur seriellen Verarbeitung von XML-Dokumenten zur Verfügung. Das heißt, dass ein Dokument Element um Element abgearbeitet wird. Die Kommunikation mit anderen Anwendungen wird dabei über sogenannte Handler abgewickelt, weshalb man auch von einem ereignisgesteuerten Protokoll spricht. Die folgende Grafik illustriert dies:
SAX1.0-API
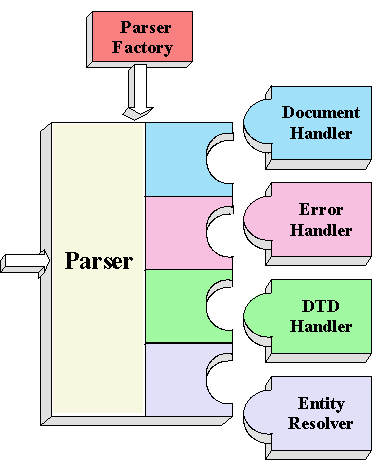
Um ein XML-Dokument zu parsen, erzeugt man sich zunächst eine Instanz eines SAX-Parsers. Dies geschieht über die ParserFactory, die gemäß der Fabrikmethode den Erzeugungsprozeß des Parsers kapselt. Der Parser darf aus einem beliebigen XML-Parser-Paket kommen und muß sich an die SAX-Spezifikation halten.
Danach muß man die jeweiligen Handler(entweder generische von einem XML-Parser, oder Handler, die man selbst gemäß den durch SAX gegebenen Interfaces implementiert hat) erzeugen und beim Parser registrieren.
Zum Schluß ruft man die Methode parse des Parsers mit dem zu parsenden XML-Dokument als Parameter auf. Der Parser wird nun das Dokument sequentiell lesen und je nach Element, das er liest, bestimmte callback-Methoden in den Handlern aufrufen. Über diese und vor allem den DocumentHandler läßt sich die Verarbeitung des XML-Dokuments dann steuern.
SAX Handler
Das SAX-API definiert folgende Handler zur Verarbeitung eines XML-Dokuments:
- DocumentHandler: Dies ist der wichtigste Handler zur Verarbeitung überhaupt. In ihm werden die Methoden startDocument und endDocument implementiert, die jeweils zu Beginn und zum Ende eines Dokuments auftreten. Desweiteren gibt es die Methoden startElement und endElement, die aufgerufen werden, wenn der Parser ein einleitendes Tag bzw. ein schließendes Tag erkennt. Erkennt der Parser z.B. ein einleitendes Tag, wird die Methode startElement mit dem Namen des Tags und sämtlichen Attributwertpaaren als Parameter aufgerufen. In dieser Methode kann der Programmierer nun die Verarbeitung des Tags steuern, z.B. Name und Attribute des Tags ausgeben. Analog dazu wird die Methode endElement aufgerufen, wenn der Parser ein schließendes Tag erkennt. Erkennt der Parser hingegen freien Text, der zwischen Tags steht, wird die Methode characters aufgerufen, findet er eine Processing Instruction die Methode processingInstruction. Außerdem gibt es noch die Methode setDocumentLocator, mit der ein Locator-Objekt an den DocumentHandler übergeben wird. Dieser Locator gibt an, wo der Parser sich gerade im XML-Dokument befindet. Zur Behandlung von Whitespace gibt es die Methode ignorableWhitespace, mehr dazu im Abschnitt Whitespace.
- ErrorHandler: Dieser Handler behandelt alle Fehler, die beim Parsen auftreten. Dafür gibt es die Methoden warning, error und fatalError, die je nach Schwere des Fehlers beim Parsen aufgerufen werden. Als Parameter erhalten diese Methoden eine SAXParseException, in der nähere Angaben zur Art des Fehlers und der Position, an der er aufgetreten ist, gespeichert sind.
Das SAX-API liefert zwar einen Default ErrorHandler in der HandlerBase Klasse, dieser wirft aber nur Exceptions bei fatalErrors, andere Fehler ignoriert er. Um Fehler in XML-Dokumenten zu erkennen, sollte man hier also auf jeden Fall seinen eigenen ErrorHandler mit speziellen Fehlerbehandlungen schreiben und beim Parser registrieren.
- DTDHandler: Dieser Handler kommt zur Anwendung, wenn der Parser in einer DTD auf ein unparsed entity, also Binärdaten mit einer zugehörigen Notation, trifft. Er ruft dann entweder die Methode unparsedEntityDecl oder notationDecl auf, in der der Programmierer seine eigene Behandlung der unparsed entities durchführen kann.
- EntityResolver: Der EntityResolver wird benötigt, wenn der Parser auf Referenzen zu externen Dateien, z.B. DTD's trifft, und diese lesen muß. Der Parser ruft dann die einzige Methode dieses Handlers, resolveEntity auf, die aus einer öffentlichen ID(URN=Universal Resource Name) eine System ID(URL=Universal Resource Locator) macht.
Beispiel
Für eine einfache Implementation eines SAX-Parsers reicht es völlig, nur die ersten beiden Handler zu schreiben. In einem kleinen Beispiel-Programm, SAXBeispiel in Java, das die erkannten Elemente eines XML-Dokuments auf der Konsole ausgibt, wird dies demonstriert.
Beispiel: SAXBeispiel.java
Von SAX 1.0 zu SAX 2.0
Dieses Jahr wurde die Version 2.0 von SAX freigegeben und es haben sich einige Änderungen und Ergänzungen zur 1.0 Spezifikation ergeben:
- XML Namespaces: Größte Neuerung in SAX 2.0 ist wohl die Unterstützung von XML-Namespaces, damit wird es möglich auch Standards wie XML-Schema, XSL und XLink zu verarbeiten.
- Properties und Features: Mit SAX 2.0 gibt es eine einheitliche Schnittstelle, zum Lesen und Schreiben von Properties und Features. Diese Features sind nicht festgelegt, sondern können vom Programmierer dynamisch hinzugefügt werden. Die Namen sind immer voll qualifizierte URI's, z.B. http://xml.org/sax/features/validation für einen validierenden Parser. Dies ist ein Feature, was zu den sog. Core Features von SAX gehört, einer Reihe von Features, die von vielen Anwendungen gebraucht wird. Es ist aber nicht zwingend diese Features zu benutzen.
- Filter: SAX 2.0 besitzt ein neues Interface XMLFilter, mit dem es möglich ist, Filter zu definieren, die zwischen dem SAX-Treiber und der ihn benutzenden Anwendung eingesetzt werden, um die Daten, die ausgetauscht werden, manipulieren zu können.
- Interface-Namen: Leider wurden in SAX 2.0 auch einige Interfaces umbenannt. So heißt das Parser Interface nicht mehr Parser, sondern XMLReader, der DocumentHandler jetzt ContentHandler u. v. m.
Whitespace
Whitespaces sind oft ein Problem beim Parsen von XML, denn es ist für den Parser in manchen Fällen schwierig zu erkennen, ob der Whitespace signifikant ist oder nicht.
Eine Art von Whitespace ist dafür da, ein XML-Dokument lesbarer zu machen, also z.B. das Einrücken von Tags oder Einfügen von Leerzeilen. Dieser Whitespace ist nicht signifikant und die meisten XML-Parser erkennen anhand von DTD's solchen Whitespace. Im DocumentHandler des SAX-API's gibt es die Methode ignorableWhitespace, die dann vom Parser aufgerufen wird. Allerdings ist zu beachten, daß nur validierende Parser diesen ignorable Whitespace erkennen können. Nun könnte man meinen, daß nichtvalidierende Parser den Whitespace dann bei der characters-Methode des DocumentHandlers melden würden, leider ist dies aber nicht immer der Fall. Manche nichtvalidierende Parser lesen nämlich trotzdem eine angegebene DTD ein und können so dann ignorable Whitespace erkennen und in der entsprechenden Methode weitergeben.
Die zweite Art sind Whitespaces, die eine bestimmte Bedeutung haben, z.B. Zeilenenden bei Gedichten, oder mehrere Leerzeichen zwischen Wörtern. Hier sollte man entweder das Attribut xml:space="preserve" im XML-Dokument setzen oder die Daten in einem CDATA-Abschnitt kapseln, damit der Parser diesen Whitespace auf jeden Fall weitergibt.
... [ Seminar XML ] ... [ XML-Parser ] ... [ DOM ] ...