DOM
... [ Seminar XML ] ... [ XML-Parser ] ... [ Parserübersicht ] ...
DOM
DOM Level 1
Das Document Object Model wird im Gegensatz zu SAX vom W3C definiert. Es stellt die Struktur eines XML-Dokuments in einer Baumstruktur dar, welche sich dann über das DOM-API auslesen oder manipulieren läßt. DOM Level 1 ist 1998 spezifiziert worden, Level 2 ist zur Zeit eine Candidate Recommendation und wird nur vom Xerces-J Parser ansatzweise unterstützt. Aus diesem Grund beschränke ich mich hier auf die Darstellung des DOM Level 1.
Das DOM definiert mehrere Interfaces, mit denen die Daten in einer Baumstruktur beschrieben werden können. Das wichtigste davon ist das Interface Node, von dem alle anderen Interfaces abgeleitet sind. Das folgende Klassendiagramm macht dies deutlich:
DOM Interfaces
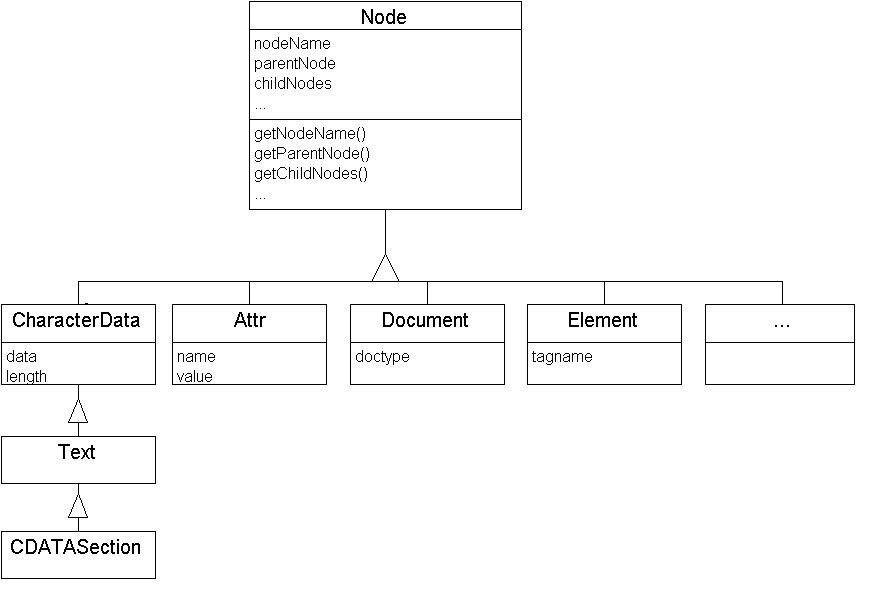
Das Node-Objekt besitzt dabei sämtliche Methoden, die zum Traversieren des Baumes nötig sind, nur noch die spezifischen Eigenschaften abgeleiteter Klassen müssen in den jeweiligen Klassen gespeichert werden(z.B. "tagname" im Interface Element). Selbstverständlich gibt es noch mehr von Node abgeleitete Interfaces als die 4 in der Grafik aufgeführten, dazu gehören noch Notation, Entity, EntityReference und ProcessingInstruction.
Beispiel
Ein kleines Beispiel zum besseren Verständnis: Betrachten wir das folgende einfache XML-Dokument:
<?xml version="1.0"?>
<!--DOM Demo-->
<xdoc>
<Begruessung>Hallo <laut>XML</laut>Parser!</Begruessung>
<Applaus art="anhaltend"/>
</xdoc>
Daraus ergibt sich folgender DOM-Baum:
Einfacher DOM-Baum
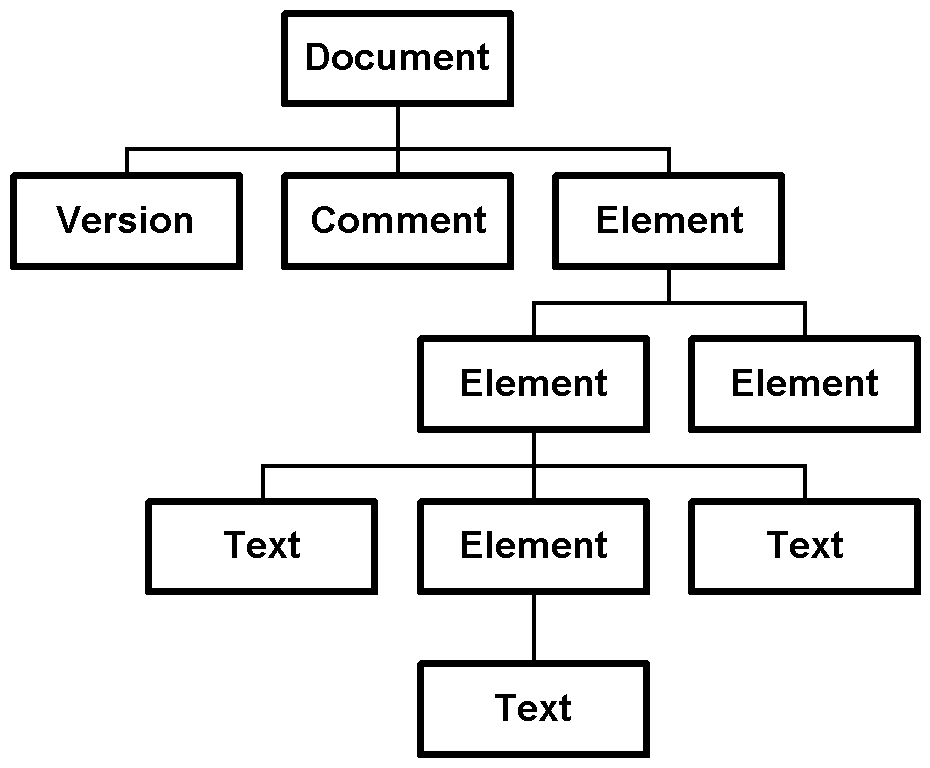
Die Wurzel eines DOM-Baumes ist immer ein Document. Dieses hat in diesem Beispiel drei Kind-Elemente: Version, Comment und Element. Die ersten beiden dürfen selber keine Kind-Elemente haben, aber Element hat wiederum zwei Kind-Elemente und so setzt sich der Baum fort.
Weiter möchte ich an dieser Stelle nicht auf das DOM-Modell an sich eingehen, sondern mehr die Implementierungen in den XML-Parsern vorstellen.
XML-Parser und DOM
Fast alle XML-Parser bieten inzwischen ein DOM-Modul an, mit dem sich ein DOM aus einer XML-Datei erstellen läßt. Leider spezifiziert DOM Level 1 nur, wie man mit dem DOM arbeiten kann, aber nicht, wie es aus einem XML-Dokument erzeugt wird oder wie man aus einem DOM ein XML-Dokument schreibt. Wie wir aber bereits im vorigen Abschnitt gesehen haben, bietet das SAX-API eine hervorragende Schnittstelle zum Parsen vom XML-Dokumenten und so bedienen sich viele DOM-Parser(z.B. Sun's Referenzimplementation für JAXP, Project X) des SAX-API's für diese Aufgabe. Dies bedeutet allerdings auch, daß man sich je nach XML-Parser auf unterschiedliche Initialisierungen und Methodennamen einstellen muß. Doch so schwierig ist es nun auch wieder nicht und ich möchte an dieser Stelle am Beispiel des JAXP Pakets von Sun den Umgang mit dem DOM zeigen.
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
try {
factory.setValidating(true);
DocumentBuilder builder = factory.newDocumentBuilder();
document = builder.parse( new File(argv[0]) );
} catch (SAXParseException spe) {
... Fehlerbehandlung ausgeschnitten ...
}
Wie man sieht ist der Umgang mit dem DOM sehr einfach. Zunächst instanziert man sich eine DocumentBuilderFactory und setzt den gewünschten Validier-Modus. Von der Factory erhält man dann die Instanz eines DocumentBuilders, bei dem man wiederum die Methode parse aufruft. Diese Methode liefert ein Objekt des Typs document zurück und genau das ist ein DOM-Modell. Dies ist hier auch die einzige Klasse, die nach einem Interface des DOM implementiert ist, die anderen Klassen, wie die DocumentBuilderFactory oder der DocumentBuilder sind nach Sun-Interfaces implementiert und heißen bei einem anderen Parser-Paket anders.
Hinweis für die Praxis
Zum Schluß noch ein genereller Hinweis zum Arbeiten mit dem DOM-Modell und mit DOM-Parsern. Der DOM-Baum, der vom Parser erstellt wird, muß immer vollständig im Hauptspeicher gehalten werden. Wenn man also von größeren XML-Dokumenten einen DOM-Baum erstellt, kann dieser ganz schnell den Hauptspeicher belegen und die Performance der Anwendung erheblich beeinträchtigen. Man sollte also immer darauf achten, wie groß die zu verarbeitenden XML-Dokumente werden können und eventuell sogar auf den Einsatz von DOM verzichten um der Geschwindigkeit willen.
... [ Seminar XML ] ... [ XML-Parser ] ... [ Parserübersicht ] ...