In diesem Abschnitt werden die Grundlagen von JDOM behandelt.
Was ist JDOM ?
Was bietet JDOM ?
Das Datenmodell
Die wichtigsten Klassen
Wie bereits erwähnt ist einer der Vorteile von DOM seine Plattform- und Sprachneutralität. Dieser Vorteil kann sich aber auch als Nachteil auswirken, wenn man als Programmierer auf diese Sprachneutralität verzichten kann. In diesen Fällen würde man sich ein Werkzeug wünschen, dass die Möglichkeiten der Zielsprache konsequent nutzt, um die Arbeit noch leichter zu gestalten. Ein solches Werkzeug möchte JDOM für Java sein. JDOM ist eine Schnittstelle für die Arbeit mit XML-Dokumenten und basiert vollständig auf Java. Hierzu nutzt es spezifische Elemente dieser Programmiersprache wie die Standard-Kollektionen, Methodenüberladung und Reflection. Diese Vorgehensweise macht die Benutzung für Java-Programmierer intuitiv und leicht erlernbar.
JDOM ist ein open-source Projekt, welches auf einer Spezifikation von Brett McLaughlin und Jason Hunter basiert. Es befindet sich zur Zeit in einer späten Beta-Testphase, die Änderungen bis zur endgültigen 1.0 Version sollten aber gering ausfallen. Die aktuellen Pakete lassen sich von der Webseite des Projektes herunterladen.
Einer der großen Nachteile von DOM ist sein enormer Speicherbedarf und seine relativ schwache Performanz. Um für JDOM zu einer besseren Lösung zu gelangen, wird zum Beispiel versucht Teile des Dokuments erst bei Bedarf zu interpretieren. Auch im Hinblick auf die Laufzeiteffizienz scheint JDOM im Vergleich zu DOM deutliche Vorteile zu haben.
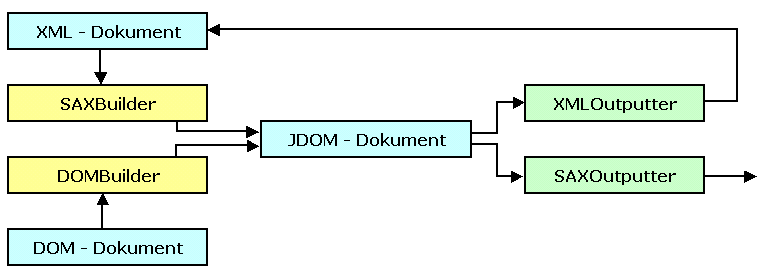
Auch wenn diese Gründe alleine wohl schon ausreichend wären, um die Etablierung eines neuen Werkzeugs zu rechtfertigen, wird nicht die direkte Konkurrenz zu den bestehenden Standards (namentlich DOM und SAX), sondern die optimale Zusammenarbeit mit diesen angestrebt. Hierfür sollen die in den Paketen org.jdom.input und org.jdom.output enthaltenen Klassen sorgen. Sie ermöglichen es ein JDOM-Dokument aus diversen Quellen zu erzeugen und an diverse Empfänger auszugeben.
Betrachten wir zunächst die Erzeugung, dann ist besonders die
Klasse SAXBuilder hervorzuheben, die zur Erzeugung eines
JDOM-Dokuments eine SAX-Implementierung bemüht. Im selben Paket
befindet sich außerdem die Klasse DOMBuilder, die für die
gleiche Aufgabe einen DOM-Parser benutzt. Da alle zur Zeit
existierenden DOM-Parser hinter den Kulissen ebenfalls SAX zum Parsen
nutzen, macht die Verwendung dieser Klasse zum Parsen von XML keinen
Sinn, da dies immer ineffizienter sein muss, als die zuvor besprochene
Alternative. Der einzige Nutzen liegt in der Methode
org.jdom.Document build(org.w3c.dom.Document), die ein
existierendes DOM-Dokument in ein JDOM-Dokument umformt. Damit wird es
möglich JDOM in Verbindung mit einem zweiten Programm zu
benutzen, welches DOM als Ausgabeformat bereitstellt.
Noch interessanter wird der gesamte Ansatz, wenn man die Klassen im zweiten erwähnten Paket org.jdom.output betrachtet. So bietet die Klasse XMLOutputter die Standardmöglichkeit ein JDOM-Dokument als XML in einen beliebigen Ausgabestrom zu pumpen. Besonders interessant ist außerdem die Variante mit Hilfe der Klasse SAXOutputter entsprechend der Struktur des Dokuments SAX-Ereignisse auszulösen, die von einer anderen Komponente interpretiert werden können. Die vorangegangene Beschreibung soll durch die folgende Abbildung noch verdeutlicht werden.
Wichtiger jedoch als die beschriebenen Klassen, ist die durch diesen Ansatz ermöglichte Flexibilität einzuschätzen. Niemand ist gehindert, für sein bestimmtes Problem eigene Ein- bzw. Ausgabeklassen zu entwickeln (obwohl es so nirgendwo zu lesen war, muss dies in abgeschwächter Weise auch für DOM gelten). JDOM stellt in solchen Fällen lediglich ein erprobtes und mächtiges Datenmodell zur Repräsentation von XML-Dokumenten und die Möglichkeiten des Zugriffs auf die enthaltenen Daten zur Verfügung.
Kommen wir nun zum Kern von JDOM, dem Datenmodell. Hierzu zeigt das folgende OMT-Diagramm einige der wichtigsten Klassen des Pakets org.jdom ohne jeglichen Anspruch auf Vollständigkeit.
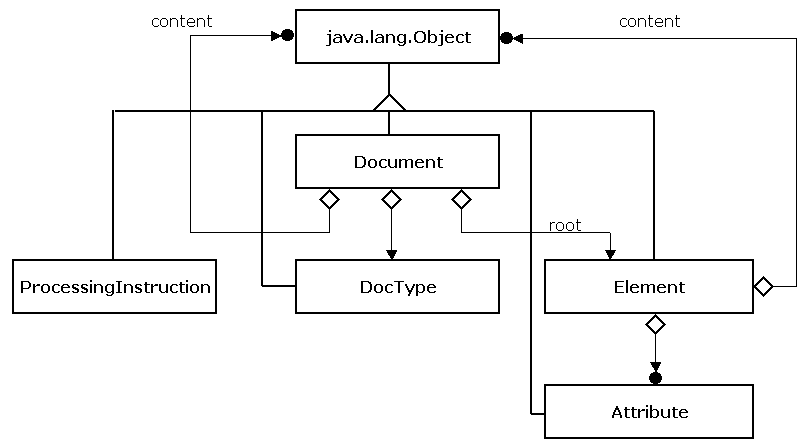
Bereits im Vergleich dieses Diagramms mit dem bereits vorher im DOM-Abschnitt gezeigten, lassen sich einige grundlegende Unterschiede bezüglich der Architektur der beiden Ansätzen ableiten.
// Anstelle von ... können noch weitere
Erweiterungen eingefügt werden. |
Viele dieser Unterschiede wirken sich positiv auf die Benutzbarkeit von JDOM aus, wie auch die Beispiele des nächsten Kapitels zeigen werden.
Element getRootElement();
Liefert eine Referenz auf das Wurzelelement des Dokuments.
List getMixedContent();
Liefert eine Liste mit allen Kindknoten zurück.
String getContent();
Viel einfacher als noch bei DOM, kann mit Hilfe dieser Methode auf den
Textinhalt des Elements zugegriffen werden. Ist keiner vorhanden, wird
eine leere Zeichenkette zurückgeliefert.
List getMixedContent();
Sollte ein Element einen gemischten Inhalt in einer Kombination von
Textdaten, geschachtelten Elementen, Kommentare, etc. besitzen, kann
mit dieser Methode eine Liste all dieser Knoten zurückgeliefert
werden. Mit dem instanceof-Operator kann dann der
ursprüngliche Knotentyp ermittelt werden.
List getChildren(String name);
Element getChild(String name);
Werden nur die direkten Kindelemente eines Elements benötigt, werden diese
Methoden helfen.