In diesem Kapitel werden die Grundlagen des Document Object Model behandelt.
Was ist das Document Object Model ?
Bäume und Knoten
Die wichtigsten Schnittstellen
Das DOM ist (unter anderem) eine Programmierschnittstelle für wohlgeformte XML-Dokumente. Es definiert die logische Struktur dieser Dokumente und außerdem die Möglichkeiten des Zugriffs und der Manipulation dieser Dokumente. Jegliche Form von Daten, die mit Hilfe von XML strukturiert werden, versteht man hierbei als Dokument.
Das DOM ist eine Spezifikation des W3C, die mehrere plattform- und sprachneutral formulierte Schnittstellen umfasst. Zusätzlich werden für manche Programmiersprachen sogenannte Sprachbindungen zur Verfügung gestellt. Im Falle von Java umfasst diese Sprachbindung einige Java-Schnittstellen, die im Paket org.w3c.dom zusammengefasst sind. Dieses Paket lässt sich von der Internetseite des W3C herunterladen.
Für die Verarbeitung von XML in eigenen Programmen, reichen diese Schnittstellen natürlich nicht aus. Vielmehr benötigt man eine konkrete DOM-Implementierung. Ein solcher Parser umfasst eine Reihe von Klassen, welche wiederum die Schnittstellen aus dem besagtem Paket implementieren.
Aus der hierarchischen Struktur der Elemente des XML-Dokuments baut der Parser einen Baum auf. Die Knoten dieses Baums sind Objekte der erwähnten Klassen. Dieser Baum ist das eigentliche Dokumentenobjekt und wird im Speicher der virtuellen Maschine verwaltet. Möchte man die Informationen des Originaldokuments bearbeiten, arbeitet man nicht direkt auf der XML-Datei, sondern mit dem Dokumentenobjekt im Speicher. Die Möglichkeiten der Bearbeitung sind wiederum durch die DOM-Schnittstellen vorgegeben.
Durch diese Vorgehensweise hat man einen kolossalen Vorteil erreicht. Denn da im Idealfall alle konkreten DOM-Parser dieselben Schnittstellen implementieren, macht man sich als Programmierer nicht von einem bestimmten Parser abhängig und kann diesen im Zweifel mit minimalen Codeänderungen austauschen, falls dies erforderlich wäre. Außerdem ist die Handhabung der Parser unter verschiedenen Programmiersprachen äußerst ähnlich, was die Einarbeitungszeit für ein Projekt sehr verkürzen kann.
Glücklicherweise existieren bereits eine Reihe von DOM-Implementierungen für Java, die von bekannten Firmen wie zum Beispiel Sun oder IBM für die Öffentlichkeit freigegeben sind. Da diese Parser in Java geschrieben sind, können sie ohne größere Probleme in eigenen Java-Programmen verwendet werden. Der zur Zeit wohl beste DOM-Parser wird im Rahmen des "Apache Xerces Projekts" entwickelt und ist samt Quelltext in einer äußerst freizügigen Lizenz für die Öffentlichkeit frei verfügbar. Aus diesem Grund wird im folgenden wenn nötig auf diesen bestimmten DOM-Parser Bezug genommen.
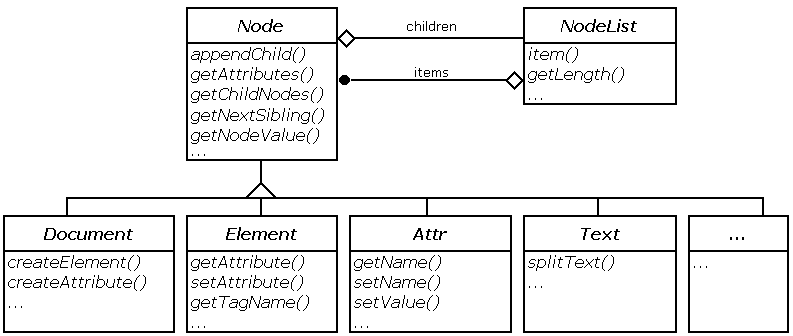
Wie jeder Baum ist auch der Dokumentenbaum aus einer bestimmten Anzahl von Knoten aufgebaut. Da aber in diesem Fall nicht alle Knoten gleichartige Informationen darstellen sollen, muss es zwangsläufig verschiedene Arten von Knoten geben. Das folgende OMT-Diagramm zeigt konzeptionell die wichtigsten dieser Knotentypen, und wie sie durch die DOM-Schnittstellen repräsentiert werden.
Anhand des bereits gezeigten XML-Dokuments (Staatenliste) soll das Zusammenspiel der verschiedenen Knotentypen genauer untersucht werden. Stellen wir uns zu diesem Zweck einmal vor, dass die folgende Abbildung die interne Struktur eines gewissen Ausschnitts des Dokumentenbaums widerspiegelt. Anhand dieser Abbildung sollen die im OMT-Diagramm dargestellten Datentypen näher beschrieben werden.
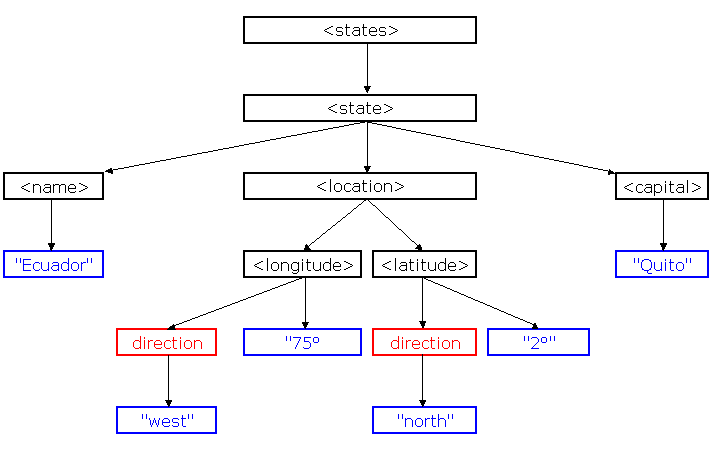
XML erlaubt es prinzipiell, dass ein Element eine beliebige Anzahl von Kindknoten besitzt. Alle diese Kindknoten können in Kollektionen gespeichert werden. Das sprachneutrale DOM definiert zu diesem Zweck eigens zwei Schnittstellen, ohne dass etwas über die konkrete Implementierung ausgesagt wird.
Mit einer NamedNodeMap wird die Menge der Attribute eines bestimmten Elements abgebildet. Auf die Elemente dieser Kollektion kann mit dem Namen des Attributs zugegriffen werden.
Node ist der Basistyp für alle übrigen Knotentypen. Er repräsentiert einen einzelnen Knoten im Dokumentenbaum und ist in einer Implementierung abstrakt. Daraus resultiert, dass jeder Knoten des Baums (jedes Rechteck in der obigen Abbildung) ein Objekt vom Typ Node ist, mindestens jedoch auch Objekt eines spezielleren Datentyps.
Betrachten wir nun zunächst einige der wichtigsten Methoden:
short getNodeType();
Liefert den Typ des Knotens codiert als einfache Zahl.
Node appendChild(Node newChild);
Hängt einen neuen Kindknoten an die bereits existierenden an.
NamedNodeMap getAttributes();
Liefert einen Container mit allen Attributen dieses Knotens. Auf diese
kann mit dem Namen des Attributs zugegriffen werden.
NodeList getChildNodes();
Liefert eine Liste mit allen Kindknoten des Elements zurück.
Node getNextSibling();
Node getPreviousSibling();
Liefert eine Referenz auf den nachfolgenden bzw. vorhergehenden Bruderknoten zurück.
String getNodeValue();
Liefert je nach Knotentyp den Wert eines Attributs, den Inhalt eines Kommentars,
den Inhalt eines Textknotens, oder null (wenn für einen speziellen Knotentyp kein
sinnvoller Wert zurückgegeben werden kann).
Es fällt auf, dass bereits an dieser Stelle Methoden definiert werden, die sich mit der Handhabung von Kindknoten beschäftigen, obwohl nicht alle Knotentypen Kinder haben können. Außerdem werden Methoden definiert, die für unterschiedliche Knotentypen eine unterschiedliche Semantik haben. Diese Vorgehensweise ermöglicht eine sogenannte flache Sicht auf den Dokumentenbaum. Da jeder Knoten des Baums ein Node ist, kann man auf diese Weise fast immer an relevante Informationen gelangen, ohne einen downcast in den speziellen Typ vornehmen zu müssen.
Der Datentyp Document repräsentiert das gesamte XML-Dokument. Es beschreibt konzeptionell die Wurzel des Dokumentenbaums und ermöglicht somit den Zugriff auf die Dokumentendaten.
Da das DOM den Anspruch erhebt, in möglichst vielen Programmiersprachen implementierbar zu sein, muss bei der Erzeugung von Knoten von der Technik der Objekterzeugung abstrahiert werden. Die übliche Vorgehensweise in solchen Fällen besteht in der Verwendung von Fabrikmethoden, die genutzt werden um Instanzen der Klassen zu erzeugen. Da Knoten nur im Kontext eines Dokuments existieren können, definiert die Document Schnittstelle diverse create...(...) Methoden, die genau diesen Zweck erfüllen.
Auf einige der wichtigsten Methoden dieses Datentyps soll im folgenden kurz eingegangen werden.
Element getDocumentElement();
Liefert eine Referenz auf das Wurzelelement des Dokuments.
Element createElement(String tagName);
Erzeugt einen neuen Element-Knoten mit angegebenem Namen.
Text createTextNode(String data);
Erzeugt einen neuen Text-Knoten.
Attr createAttribute(String name);
Erzeugt einen neuen Attribut-Knoten.
Der Datentyp Element beschreibt die Tags der XML-Datei und im obigen Dokumentenbaum stellen die schwarzen Rechtecke Elemente dar. Elemente haben häufig Attribute und natürlich definiert diese Schnittstelle einige Bequemlichkeitsmethoden für die Arbeit mit Attributen. Da jedoch Elemente die am häufigsten verwendeten Knoten sind, ist der Zugriff auf Attribute von Knoten auch schon auf der Knotenebene möglich. Es folgen die wichtigsten Methoden:
NodeList getElementsByTagName(String name);
Erzeugt eine Liste von Kindelementen, die einen bestimmten Namen haben.
String getAttribute(String name);
Gibt den Wert des Attributs mit dem angegeben Namen zurück.
Attr getAttributeNode(String name);
Gibt eine Referenz auf das Attribut mit dem angegeben Namen zurück.
void removeAttribute(String name);
Löscht das Attribut mit einem bestimmten Namen.
void setAttribute(String name, String value);
Ändert entweder den Wert eines bereits existierenden Attributs
mit dem angegebenen Namen oder erzeugt ein neues mit dem entsprechenden Wert.
Die schon häufiger erwähnten Attribute werden durch den Datentyp Attr repräsentiert. Obwohl auch dieser Datentyp von Node erbt, werden Attribute nicht als echte Kindknoten angesehen, sondern als Eigenschaften eines Elements.
Weiterhin ist zu beachten, dass das DOM zumindest im Kernmodul nicht zwischen verschiedenen Datentypen von Attributen unterscheidet, auch wenn die Dokumenttypdefinition etwas anderes aussagen sollte. Auch hier folgt eine Liste der wichtigsten Methoden:
String getName();
Gibt den Namen des Attributs zurück.
String getValue();
Gibt den Wert des Attributs zurcük.
void setValue(String value);
Setzt den Wert des Attributs auf value.
Element getOwnerElement();
Liefert eine Referenz auf das Element, für den dieses Attribut im
Gebrauch ist.
Die Text-Schnittstelle repräsentiert den Inhalt von Elementen oder Attributen. Dies entspricht den blauen Rechtecken in der obigen Abbildung. Es ist wichtig sich zu merken, dass der Textinhalt eines Elements als echter Kindknoten des Elements betrachtet wird. Dadurch kann auch ein gemischter Inhalt, der zum Beispiel zwei Textpassagen getrennt durch ein Kommentar enthält, ohne weiteres modelliert werden. Bezüglich dieses Textinhalts von Elementen gilt es allerdings zu beachten, dass alle Geschwister vom Typ Text, die nicht durch andere Knoten getrennt sind, bei der Serialisierung zusammengefasst werden. Bsp.:
<ABSATZ>
Als Gregor Samsa eines Morgens aus unruhigen Träumen erwachte,
fand er sich in seinem Bett zu einem ungeheuren Ungeziefer verwandelt.
</ABSATZ>
In diesem Beispiel sind die blaue und die rote Zeile zwei direkt
aufeinanderfolgende Textknoten. Nach Speicherung des Dokuments und
erneutem Einlesen werden diese beiden Knoten jedoch zu einem einzelnen
Textknoten zusammengefasst.