 Maps
Maps
 Die VDM-Basistypen
Die VDM-Basistypen
 Sets
Sets
Definition Ein Tuple ist eine endliche, geordnete, aber unsortierte Sammlung von gleichartigen Objekten, die auch mehrfach auftreten dürfen. Etwas ausführlicher:
Eine Zweiergruppe von Objekten heißt Paar, eine Dreiergruppe ,,Tripel``, eine Vierergruppe ,,Quadrupel`` und eine Gruppe von n Objekten heißt ,,n-Tupel``; daraus leitet sich der allgemeine Begriff ,,Tuple`` ab. Andere, passende Bezeichnungen sind z.B. ,,Liste``, ,,Sequenz`` oder ,,eindimensionale Matrix``. Die Objekte sind aufsteigend durchnumeriert und jedem Objekt ist seine laufende Nummer als Index zugeordnet -- daraus folgt aber nicht, daß auch die Objekte in irgendeiner Weise sortiert sind!
Sprechweisen Aus der Numerierung ergeben sich ,,Namen`` bzw. Sprechweisen für bestimmte Objekte oder Teile des Tuple: das Objekt an der Position 1 heißt auch head und ist das ,,linke`` Ende des Tuple, der Rest des Tuple (ohne den head) heißt tail, das letzte Objekt heißt dementsprechend last und ist das ,,rechte`` Ende des Tuple. Die Anzahl der Objekte heißt auch ,,Länge`` des Tuple. Die Nomenklatur der Operationen ist diesen Sprechweisen angepaßt.
Tuples erinnern Sie sicherlich an Array ? Arrays (Tabellen) in C; tatsächlich können Sie Tuples auch mit deren Hilfe implementieren. Der Unterschied besteht darin, daß Tuples beliebig viele, beliebig komplexe Objekte enthalten können!
DSL Um in der DSL-Spezifikation ein Tuple
Atuple von Objekten eines Domains ![]() zu definieren, schreiben Sie
zu definieren, schreiben Sie
![]()
Anwendung Wenn Sie Sammlungen von Objekten modellieren, die in einer wohldefinierten Reihenfolge repräsentiert werden sollten, weil sich Bezeichnungen wie das ,,erste`` Objekt, das ,,letzte`` Objekt oder auch das ,,n.te`` Objekt aufdrängen und wenn Sie Manipulationen wie das Aneinanderhängen von solchen Objektsammlungen, den indizierten Zugriff auf ein einzelnes Objekt und Verarbeitung der Objekte in der gegebenen Reihenfolge durchführen möchten, dann ist die Verwendung von Tuples angezeigt.
Beispiel: Dazu ein Beispiel: Um Texte als definierte Folgen von Wörtern und Zwischenräumen, die wiederum definierte Folgen von Zeichen sind, zu modellieren, können Sie Wörter und Zwischenräume als Tuple von Zeichen, Texte als Tuple von Wörtern und Zwischenräumen auffassen. Hier wollen wir Wörter und Zwischenräume nicht trennen, sie werden also beide als Objekte vom Typ ,,Wort`` aufgefaßt.
Text= Word* Word = Char
Natürlich ist ein Text damit selbst eine Sequenz von Zeichen. Sets sind nicht zur Modellierung von Texten geeignet, da Zeichen ja durchaus mehrfach auftreten können und zudem erst ihre Reihenfolge den Wörtern und Texten einen Sinn gibt!
VDM-Strings Dieses Beispiel zeigt Ihnen schon, daß die Verarbeitung von Zeichenketten (Strings) , die in vielen Applikationen benötigt wird, am besten mit Tuples erfolgt. Folgerichtig stellt VDM einen vordefinierten Datentyp Str bereit, der dem Word im obigen Beispiel entspricht. Die für Strings adäquate Implementation ,,array`` kennt einige Operationen, die den Umgang mit diesen VDM-Strings allein und in Verbindung mit normalen C-Strings erleichtern; sie sind das Thema eines gesonderten Abschnitts innerhalb der Darstellung der Operationen.
Für Tuples stehen zwei Implementationen zur Verfügung:
Zur Veranschaulichung der Operationen dienen folgende Variablen:
Textt1, t2;
*
Word w1, w2;
*
Char c1, c2;
mk_empty Mit mk_empty
erzeugen Sie ein leeres Tuple, das also keine Elemente enthält.
*
Beispiel -- ein neuer, noch leerer Text wird erzeugt:
t1 = mk_empty_text();
*[1ex]
mk_one Mitmk_oneerzeugen Sie
ein neues Tuple, das bereits ein Element enthält.
*
Beispiel -- Wörter müssen aus mindestens einem Zeichen bestehen, um in einen
Text aufgenommen zu werden:
c1 = 'A';
*
w1 = mk_one_word(c1);
*[1.5ex]
mk2 Mitmk2können Sie mit einem
Aufruf gleich ein zwei-elementiges Tuple erzeugen.
*
Beispiel -- ein Text besteht zu Beginn mindestens aus einem Wort und einem
Zwischenraum, hier in Form der Klammer hinter dem Buchstaben A:
c2 = ')';
*
w2 = mk_one_word(c2);
*
t1 = mk2_text(w1, w2);
*
![]() t1 enthält den Text ,,A)``
t1 enthält den Text ,,A)``
*[1.5ex]
mk3 Mitmk3können Sie auch drei-elementige Tuples auf einmal initialisieren.
w1 =
mk3_word('V','D','M');
*[1.5ex]
mkn Mitmknwird Ihnen die
Aufgabe erleichtert, ein Tuple mit n-mal dem gleichen Element zu
erzeugen.
*
Beispiel -- Trennlinie aus 80 Bindestrichen:
w1 = mkn_word('-',80);
*[3ex]
copy / copy1 Auch für Tuples gibt es natürlich diese beiden Operationen zum Kopieren eines anderen Tuple.
mkc / mklc VDM-Strings können Sie mit mkcundmklcaus vorhandenen C-Strings erzeugen, die wie üblich durch ihre Startadresse charakterisiert sind; mklc wandelt den String bei der Konvertierung in Kleinbuchstaben um. Näheres über diese beiden Operationen finden Sie im Abschnitt über String-Manipulation auf
Kombination mehrerer Tuples
conc Mitconcverketten Sie
zwei Tuples miteinander (Konkatenation), d.h. das zweite wird an das erste
angehängt.
*
Beispiel -- der Hauptteil t1 und der Anhang t2 bilden zusammen
ein Buch:
t1 = conc_text(t1,t2);
*[1.5ex]
conc_path Mitconc_path
erzeugen Sie einen Pfadnamen aus zwei Verzeichnisnamen, indem bei der
Verkettung ein Pfad-Delimiter des jeweiligen Betriebssystems eingefügt wird.
Dieser Pfad-Delimiter ist unter UNIX der Slash ,,/``, unter
MS-DOS der Backslash ,,\``. Sie merken schon, es handelt
sich um einen Befehl für Strings.
*
Beispiel -- das Include-Verzeichnis mit den Standard-Header-Dateien von
C konstruieren Sie aus den einzelnen Verzeichnisnamen wie folgt:
w1 enthält ,,/usr`` (Wurzel der Benutzer-Verzeichnisse)
*
w2 enthält ,,include``
*[0.5ex]
w1 = conc_path_word(w1,w2);
*[0.5ex]
![]() w1 enthält jetzt ``/usr/include`` !
w1 enthält jetzt ``/usr/include`` !
*[3ex]
Kombination eines Tuples mit einem Element
appl Mitapplhängen Sie am
,,linken`` Ende eines Tuple ein Element an (,,append left``); alle Elemente
werden also um eine Position zum Ende des Tuple geschoben und das neue Element
ist danach das erste Tuple-Element, also der ,,head``. Die Reihenfolge der
Argumente ist übrigens entsprechend: erst das Element, dann das Tuple!
*
Beispiel -- Sie stellen Ihrer Autobiographie das Wort ,,Erinnerungen`` als
Titel voran:
w1 enthält ,,Erinnerungen``
*
t1 enthält Ihre Autobiographie
*
t1 = appl_text(w1,t1);
*[0.5ex]
![]() t1 enthält jetzt das komplette Werk!
t1 enthält jetzt das komplette Werk!
*[1.5ex]
appr Mitapprhängen Sie ein
Element am ,,rechten`` Ende eines Tuple an (,,append right``), wodurch es zum
neuen ``last`` wird. Die Argument-Reihenfolge spiegelt diesen Vorgang wieder:
erst das Tuple, dann das Element!
*
Beispiel -- an einen Geschäftsbrief fügen Sie das Wort ,,Anlagen`` an:
w1 enthält ,,Anlagen``
*
t1 enthält Ihren Brief
*
t1 = appr_text(t1,w1);
*[0.5ex]
![]() t1 enthält jetzt den fertigen Brief!
t1 enthält jetzt den fertigen Brief!
*[1.5ex]
ovwrt1 Mitovwrt1ersetzen Sie
das Element an einer bestimmten Position im Tuple durch ein anderes,
vorausgesetzt, das Tuple ist nicht kürzer. owvrt1d ist die zugehörige
Version mit implizitem Löschen.
*
Beispiel -- Ihre Autobiographie soll ``Lebenserinnerungen`` heißen, den alten
Titel benötigen Sie nicht weiter:
w1 enthält ,,Lebenserinnerungen``
*
t1 enthält Ihre Autobiographie
*
t1 = ovwrt1d_text(t1,1,w1);
*[0.5ex]
![]() t1 enthält jetzt das berichtigte Werk!
t1 enthält jetzt das berichtigte Werk!
*[1.5ex]
is_eq Mitis_eqtesten Sie zwei Tuples auf Gleichheit; sie sind dann und nur dann gleich, wenn sie die gleiche Länge haben und die Elemente in der vorgegebenen Reihenfolge paarweise gleich sind (deren Gleichheit wird mit der entsprechenden Operation für den Elementtyp ermittelt).
is_ge Mitis_getesten Sie, ob ein Tuple größer oder gleich einem anderen ist. Ein Tuple ist größer oder gleich, wenn keines seiner Elemente kleiner als das entsprechende Element des anderen Tuple ist und es bei Gleichheit aller Elementpaare nicht kürzer ist als das andere Tuple. Dazu muß für die Elemente natürlich eine entsprechende Relation existieren; der VDM-Compiler bemerkt einen etwaigen Fehler.
is_gr Mitis_grschließlich testen Sie, ob ein Tuple größer als ein anderes ist. Es ist größer, wenn mindestens eines seiner Elemente größer ist als das entsprechende Element des anderen Tuple oder wenn es, bei Gleichheit aller Elementpaare, mehr Elemente hat.
Die folgende Tabelle veranschaulicht die Zusammenhänge mit Hilfe von VDM-Strings:
| Wort 1 | Wort 2 | is_eq | is_ge | is_gr |
| * Test | Test | J | J | N |
| * Teile | Test | N | N | N |
| * Test | Teile | N | J | J |
| * Teile | Teil | N | J | J |
| * Teil | Teile | N | N | N |
| * |
is_empty Mitis_emptytesten Sie, ob das Tuple gerade leer ist, also keine Elemente enthält und damit die Länge 0 hat.
len Mitlenermitteln Sie die
,,Länge`` eines Tuple, also die Anzahl seiner Elemente.
*
Beispiel -- die Länge eines VDM-Strings ist identisch mit der Länge des
entsprechenden C-Strings, denn dessen Endemarkierung wird von der
Funktion strlen nicht mitgezählt!
w1 enthält ,,Suelldorf``
*
w2 enthält ,,¡`
*
len_word(w1) == 9
*
len_text(mk2_text(w1,w2)) == 2
*[1.5ex]
Die nächsten beiden Attribute haben mehrere Argumente, liefern aber dennoch eine Eigenschaft des Tuple!
search Mitsearchermitteln Sie
das am weitesten ``links`` im Tuple stehende Element, das ein angegebenes
Prädikat (in Form einer Funktion mit einem Bool-Resultat) erfüllt; gibt
es kein solches Element im Tuple, ist das Ergebnis 0.
*
Beispiel -- Suche nach dem ersten Großbuchstaben in einem Wort:
printf("%d",search_word(w1,isupper));
*[1.5ex]
index Mitindexermitteln Sie
die erste Position eines bestimmten Elements im Tuple; ist das Element nicht
enthalten, ist das Ergebnis 0.
*
Beispiel -- Suche nach einem Bindestrich in einem Wort:
printf("%d",index_word(w1,'-'));
*[1.5ex]
Selektion eines Elements
hd Mithdgreifen Sie das erste Element, den head, aus einem Tuple heraus. Die Operation wird häufig zusammen mit tl zur kompletten Bearbeitung eines Tuple mit einer rekursiven Funktion verwendet; ein Beispiel finden Sie etwas weiter unten bei der Darstellung von tl.
last Mitlastgreifen Sie das
letzte Element eines Tuple heraus, also das Element mit dem höchsten Index,
vorausgesetzt, das Tuple ist nicht leer.
*
Beispiel -- bevor Sie das Wort ,,Anlagen`` an Ihren Geschäftsbrief anfügen,
möchten Sie prüfen, ob es bereits dort steht:
w1 enthält ,,Anlagen``
*
t1 enthält Ihren Brief
*[0.5ex]
if (!is_eq_word(last_text(t1),w1))
*
t1 = appr_text(t1,w1);
*[0.5ex]
![]() t1 enthält den Brief, ,,Anlagen`` ist genau
einmal vorhanden!
t1 enthält den Brief, ,,Anlagen`` ist genau
einmal vorhanden!
*[1.5ex]
sel Mitselgreifen Sie ein beliebiges Element über dessen Index aus dem Tuple heraus -- wenn es soviele Elemente enthält. sel ist damit eine allgemeine Operation, mit deren Hilfe hd und last realisiert werden können:
hd_xxx(obj) == sel_xxx(obj,1);
*
last_xxx(obj) == sel_xxx(obj,len_xxx(obj));
*[2ex]
Selektion eines Teil-Tuple
tl Mittlselektieren Sie den
tail eines Tuple, entfernen also das erste Element, den head.
Zusätzlich existiert die Version tld mit implizitem Löschen. Diese
Operation wird häufig benutzt, um rekursiv ein komplettes Tuple abzuarbeiten,
indem der head verarbeitet wird und die Funktion mit dem tail
erneut aufgerufen wird.
*
Beispiel -- Ermittlung der Zeichen-Summe (Summe der Zeichen-Codes) eines
Wortes:
Nat0 charsum (Word w)
*
{
*
if (is_empty_word(w))
*
return 0;
*
else
*
return hd_word(w) + charsum(tl_word(w));
*
}
*[1.5ex]
sub_tup Mitsub_tup
selektieren Sie einen zusammenhängenden Teil des Tuple durch Angabe des
unteren und oberen Index; ist der obere Index kleiner als der untere, wird das
leere Tuple geliefert, ebenso, wenn der untere Index größer ist als die Länge
des Tuple. Ist hingegen der obere Index größer als die Länge des Tuple,
erhalten Sie das Ende des Tuple ab dem unteren Index.
*
Beispiel -- Sie wollen den Anhang Ihrer Autobiographie herausgreifen, von dem
Sie zufällig wissen, daß er beim 14965. Wort beginnt:
t1 enthält Ihr Buch
*
t2 = copy1_text(t1);
*
t2 = sub_tup_text(t2,14965,len_text(t2));
*
t1 enthält immer noch das gesamte Buch; die Operation sub_tup zerstört ihr Argument, daher wurde vorher mit copy1 eine Kopie des Buches erzeugt. Beide Texte verwenden aber die gleichen Wörter, da die Sub-Strukturen nicht mitkopiert wurden!
rmv1 Mitrmv1entfernen Sie ein Element aus einem Tuple, indem Sie dessen Position angeben. Sie erhalten also ein Tuple, in dem alle Elemente an höheren Positionen um eine Position nach ,,links`` geschoben wurden -- vorausgesetzt, das Tuple enthielt ein Element an der gewünschten Position. Zusätzlich gibt es die Version rmv1d mit implizitem Löschen des entfernten Elements. rmv1 ist die allgemeine Form des Entfernens von Elementen aus einem Tuple; tl und sub_tup können damit realisiert werden:
tl_xxx(obj) == rmv1_xxx(obj,1)
*[1ex]
Xxx sub_tup_xxx (Xxx obj,Nat1 lb,Nat0 ub)
*
{
*
int i;
*[0.5ex]
for (i = 1; i < lb-1 && len_xxx(obj) > 0; i++)
*
obj = rmv1_xxx(obj,1);
*
ub -= lb-1;
*
while (ub < len_xxx(obj))
*
obj = rmv1_xxx(obj,ub+1);
*
return obj;
*
}
*[1.5ex]
Sie können mit Tuples sequentielle Datei-Operationen durchführen, denn ein Tuple kann als das Speicher-Abbild einer sequentiellen Datei (also eine Sequenz von Datensätzen) angesehen werden. Die üblichen Operationen sind das Einlesen der Datei, das Schreiben aller Datensätze im Tuple in eine Datei und das Anhängen der Datensätze im Tuple an eine bestehende Datei. Mit den drei Operationen fread, fwrite und fapp können Sie diese Aktionen durchführen, ohne sich um die Dateiverwaltung (Öffnen, Schließen usw.) kümmern zu müssen. Allerdings wird angenommen, daß die Elemente des Tuple einfache, unstrukturierte Objekte sind.
Die Dateinamen werden übrigens bei allen drei Operationen in Form von VDM-Strings erwartet.
fread Mitfreadlesen Sie die
angegebene Datei vollständig in ein Tuple ein. Tritt in einer
Datei-Operation ein Fehler auf, wird das leere Tuple geliefert.
*
Beispiel -- Sie können eine Textdatei in ein Tuple vom Typ word
einlesen:
w2 enthält den Dateinamen ,,/usr/include/stdio.h``
*
w1 = fread_word(w2);
*
if (is_empty_word(w1))
*
fileerror();
*
fileerror ist eine selbstdefinierte Fehlerroutine!
*[1.5ex]
fwrite Mitfwriteschreiben Sie
ein Tuple vollständig in die angegebene Datei, deren vorheriger Inhalt (wenn
sie schon existierte) gelöscht wird. Tritt bei einer Datei-Operation ein
Fehler auf, wird FALSE geliefert.
*
Beispiel -- Sie schreiben das soeben gelesene Tuple nach einigen
Manipulationen wieder zurück:
w1 enthält die Datensätze
*
w2 enthält den Dateinamen ,,/usr/include/stdio.h``
*
if (!fwrite_word(w1,w2))
*
fileerror();
*[1.5ex]
fapp Mitfapphängen Sie ein
Tuple an eine existierende Datei an (wenn sie noch nicht existiert, wird sie
erzeugt, die Wirkung entspricht dann fwrite). Tritt bei einer
Datei-Operation ein Fehler auf, wird FALSE geliefert.
*
Beispiel -- Sie haben einige zusätzliche Zeilen für Ihre persönliche
C-Header-Datei in Form eines Wortes in einem Tuple vom Typ word
gespeichert und hängen sie nun an diese Textdatei an:
w1 enthält die neuen Datensätze
*
w2 enthält den Dateinamen ,,/usr/mydir/my_decl.h``
*
if (!fapp_word(w1,w2))
*
fileerror();
*[1.5ex]
Wie schon kurz angedeutet, gibt es den vordefinierten Typ ,,Str`` als Tuple von Zeichen, damit bei der Verwendung von VDM auch Zeichenketten bequem gehandhabt werden können; Sie haben bei den Datei-Operationen auch schon Einsatzmöglichkeiten kennengelernt. Außerdem waren alle bisherigen Operationen mit Hilfe von VDM-Strings illustriert. Es gibt auch einige spezielle VDM-String-Operationen, die allerdings nur in der Implementation ,,array`` existieren, da eine Repräsentation von Strings nur in dieser Implementation sinnvoll ist. Diese Implementation hat zwei Parameter, die für VDM-Strings definiert sein sollten, nämlich ,,SIMPLEELEMS`` (einfache Elemente ohne dynamische Speicheroperationen) und ,,ISCHAR``, der anzeigt, daß es sich um Elemente vom Typ Char handelt.
Vorteil Der größte Vorteil von VDM-Strings: Da die Größe eines Tuple an die Anforderungen angepaßt wird, sind Fehler wegen Überschreitung des Speicherplatzes nicht möglich -- bei C-Strings kommen sie gelegentlich vor und haben meist schwerwiegende Folgen (und sind zudem sehr schwer zu finden).
Die ersten drei Operationen sorgen für die Konvertierung zwischen VDM-Strings und normalen C-Strings.
cpc Mitcpckonvertieren Sie
einen VDM-String in einen C-String, der wie üblich durch seine
Anfangsadresse definiert wird. Sie müssen allerdings selbst dafür sorgen, daß
der Speicherplatz für den String ausreicht. Die übliche Ende-Kennung für
C-Strings, das Null-Zeichen, wird automatisch angefügt.
*
Beispiel -- eine Konvertierungsfunktion, die den verfügbaren Speicher für den
C-String als weiteres Argument erhält und bei zuwenig Speicher
FALSE zurückliefert:
Bool to_c_str (Str s,char ![]() c,Nat0 l)
c,Nat0 l)
*
{
*
if (len_str(s) >= l)
*
return FALSE;
*
else {
*
cpc_str(s,c);
*
return TRUE;
*
}
*
}
*
Da zusätzlich eine Endekennung angehängt wird, darf die Länge des Strings nicht genauso groß sein wie der verfügbare Speicherplatz!
mkc Mitmkckonvertieren Sie einen C-String, den Sie mit seiner Anfangsadresse definieren, in einen VDM-String; das abschließende Null-Zeichen wird nicht mitkopiert.
char ![]() c;
c;
*
![]()
*
c = "Suelldorf !";
*
w1 = mkc_str(c);
*[1.5ex]
mklc mklcmacht dasselbe wie mkc, wandelt dabei aber alle Großbuchstaben in Kleinbuchstaben um.
Damit nicht alle weiteren Dinge, die man mit Strings machen kann, nur mit C-Strings möglich sind und eine Konvertierung nötig machen, bietet VDM eine Operation zur Ausgabe eines VDM-Strings in eine angegebene Datei; das kann natürlich auch stdout sein, so daß eine Bildschirmausgabe direkt möglich ist!
puts Mitputsschreiben Sie
einen VDM-String zeichenweise mit Hilfe der C-Standardfunktion
fputc in eine durch einen File-Pointer definierte C-Datei; die
Hauptanwendung ist die Bildschirmausgabe in die Systemdateien stdout
bzw. stderr. So ersparen Sie sich die vorherige Konvertierung in einen
C-String.
*
Beispiel -- Ausgabe einer Fehlermeldung, die im Tuple w1 steht:
puts_word(w1,stderr);
*[1.5ex]
Zur Erzeugung neuer, komplexer Funktionen mit Hilfe der vorhandenen gibt es drei Funktionale. Da Funktionale bereits bei den Sets ausführlich behandelt werden, ist die Beschreibung hier etwas kürzer; wenn Sie damit Schwierigkeiten haben, sollten Sie die entsprechenden Passagen ab lesen.
binary Mitbinarykönnen binäre Funktionen die aus einem Tuple und einem Element ein neue Tuple erzeugen, verallgemeinert werden zu Funktionen, die aus zwei Tuples ein neues Tuple erzeugen und dabei ihre Argumente zerstören. Eine mit binary erzeugte Funktion arbeitet wie folgt:
Atup newfct_atup (Atup t1, Atup t2)
*
{
*
Elem e;
*[0.5ex]
if (is_empty_atup(t2))
*
return t1;
*
else {
*
e = hd_atup(t2);
*
return newfct_atup(foldfct_atup(t1,e), tl_atup(t2,e)) ;
*
}
*
}
*[1.5ex]
foldfct hat zwei Argumente, ein Tuple und ein Element, und liefert wieder ein Tuple; Sie legen sie in der DSL-Spezifikation mit dem Parameter ,,FOLDFCT`` fest.
Ein Anwendungsbeispiel: die Operation conc kann mit Hilfe von binary und appr definiert werden.
IMPLEMENTATIONS
*
...+ binary.conc(FOLDFCT="appr")
*[3ex]
fold Das Funktionalfoldhat drei Parameter-Funktionen und erzeugt eine Funktion, die ein Tuple auf einen durch die Parameter-Funktionen festgelegten Resultattyp abbildet. Damit lassen sich sehr gut komplexe Manipulationen aller Elemente eines Tuple realisieren. Die Parameter-Funktionen haben die gleiche Bedeutung wie bei Sets (hier natürlich auf Tuples bezogen). Die erzeugte Funktion sieht von der Struktur her wie folgt aus:
Retult newfct_atup (Atup t)
*
{
*
Elem e;
*[0.5ex]
if (is_empty_atup(t))
*
return nullfct_result();
*
else {
*
e = hd_atup(t);
*
return foldfct_result(cvfct_elem(e),
*
newfct_atup(tl_atup(t,e)));
*
}
*
}
Nomenklatur Die Namen der drei Parameterfunktionen und der erzeugten Funktion werden erweitert: die Konvertierungsfunktion mit dem Namen des Elementtyps, die Nullfunktion mit dem Namen des Resultattyps, die Fold-Funktion mit dem Namen des Resultattyps und die erzeugte Funktion mit dem Namen des Tuple.
Beispiel: Eine häufige Anwendung von fold ist die distributive Konkatenation aller Tuples in einem Tuple von Tuples, also z.B. die Erzeugung eines Wortes, in dem alle Worte eines Textes aneinandergehängt sind:
IMPLEMENTATIONS
*
...+ fold.d_conc(NULLFCT="mk_empty",
FOLDFCT="conc")
*
erzeugt
*
Word d_conc_text (Text t)
*[1ex]
Weitere Informationen (z.B. über zusätzliche Parameter) und Beispiele über fold finden Sie im entsprechenden Abschnitt über fold für Sets bzw. Maps.
foldix foldixist ein weiteres Funktional, das allerdings fold sehr ähnelt. Der einzige Unterschied betrifft die Konvertierungsfunktion eines Elements in den Resultattyp, die ein weiteres Argument erhält (an zweiter Stelle, direkt nach dem Element und noch vor den zusätzlich vereinbarten Argumenten): den Index des aktuellen Elements im Tuple. Damit ist eine index-abhängige Konvertierung der Elemente möglich.
Beispiel: Sie möchten die distributive Konkatenation (wie oben erläutert) nur für jedes zweite Wort des Textes durchführen.
IMPLEMENTATIONS
*
...+ foldix.d2_conc(CVFCT=
erzeugt "second",
*
NULLFCT="mk_empty",
*
FOLDFCT="conc")
*
*
Word d2_conc_text (Text t)
*[1ex]
Konvertierungsfunktion:
*
Word second_word (Word w, Nat0 i)
*
{ return (i & 1) ? mk_empty_word() : w ; }
*[2ex]
forall Mitforallführen Sie
für alle Elemente eines Tuple (in aufsteigender Reihenfolge) eine angegebene
Prozedur aus, die ein Argument des Elementtyps erwartet.
Beispiel -- die Ausgabe aller Worte eines Textes auf dem Bildschirm:
void disp_word (Word w)
*
{ puts_word(w, stdout); }
*
![]()
*
forall_text(t1, disp_word);
*[1.5ex]
forindex Mitforindexführen
Sie für alle Elemente eines Tuple (in aufsteigender Reihenfolge) eine
angegebene Prozedur aus, die als Argumente ein Element UND eine natürliche
Zahl erwartet; diese Prozedur erhält zu jedem Element auch dessen Index im
Tuple.
Beispiel -- zeilenweise Ausgabe aller Worte eines Textes mit ihrer
Ordnungszahl auf dem Bildschirm:
void disp2_word (Word w, Nat1 n)
*
{
*
printf("\n%d", n);
*
puts_word(w, stdout);
*
}
*
![]()
*
forindex_text(t1, disp2_word);
*[1.5ex]
forrange Mitforrangeführen
Sie für die Elemente eines Tuple, die innerhalb eines angegebenen
Index-Bereichs liegen, eine Prozedur mit einem Argument vom Elementtyp aus.
Beispiel (nicht sehr sinnvoll) -- Ausgabe eines bestimmten Ausschnitts eines
Textes, dessen Grenzen vielleicht vom Benutzer eingegeben werden können:
void disp_word (Word w)
*
{ puts_word(w, stdout); }
*
![]()
*
forrange_text(t1, disp_word, firstword, lastword);
*[1.5ex]
forsome Mitforsomeführen Sie
für einige Elemente eines Tuple, die ein angegebenes Prädikat erfüllen, eine
Prozedur mit einem Argument vom Elementtyp aus.
Beispiel -- Ausgabe aller Wörter eines Textes, die mit einem Großbuchstaben
anfangen und mehr als vier Zeichen haben:
void disp_word (Word w)
*
{ puts_word(w, stdout); }
*[0.5ex]
Bool main_word (Word w)
*
{ return isupper(hd_word(w)) && len_word(w) > 4; }
*
![]()
*
forsome_text(t1, main_word, disp_word);
*[1.5ex]
Wir wollen das berühmte Pascal-Dreieck bis zu einer beliebigen Ordnung berechnen. Zur Erinnerung: das Pascal-Dreieck stellt in der n. Zeile der Reihe nach folgende Werte dar (wobei die oberste Zeile als ,,nullte`` Zeile nur die eins enthält):
![]()
Das Pascal-Dreieck beginnt also wie in Abb. 5.3 dargestellt.
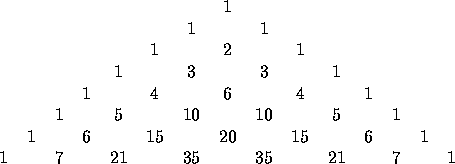
Abbildung 5.3: Beispiel für Tuples: das Pascal-Dreieck
Wie wir dieser Abbildung entnehmen können, gibt es einen weiteren, einfacheren Algorithmus zur Erzeugung des Dreiecks: ein Element ergibt sich (von den Rand-Elementen einmal abgesehen, die immer 1 sind) aus der Summe der beiden Elemente, die diagonal rechts und links über ihm stehen! Diesen Algorithmus wollen wir nun umsetzen.
Zur Erzeugung der n.ten Zeile benötigen wir auch alle vorherigen Zeilen. Wir wollen uns auf die Fälle mit n > 1 beschränken, weil die ersten beiden Zeilen (Ordnungen 0 und 1) trivial sind.
Jede Zeile modellieren wir als Tuple von Zahlen, das ganze Dreieck als Tuple von Zeilen. Die DSL-Spezifikation muß also folgendermaßen aussehen:
DOMAINS
*[0.5ex]
Tri=Row
![]() *
Row = Nat1
*
Row = Nat1 ![]() [1ex]
IMPLEMENTATIONS
*[0.5ex]
Tri = array + ...
*
Row = array + ...
*
[1ex]
IMPLEMENTATIONS
*[0.5ex]
Tri = array + ...
*
Row = array + ...
*
Zunächst entwerfen wir das Hauptprogramm, das die trivialen ersten beiden Zeilen im Dreieck abspeichert (und damit ein ,,wohlgeformtes Dreieck`` für die Berechnung größerer Dreiecke erzeugt) und danach, abhängig von der gewünschten Ordnung, die semantische Funktion mk_pascal aufruft.
void main (int argc,char ![]() argv[])
argv[])
*
{
*
Tri tri;
*
Row row;
*
Nat0 n = atoi(argv[1]);
row = mk_one_row(1);
*
tri = mk_one_tri(row);
*
if (n == 0) {
*
pr_tri(tri);
*
return;
*
}
row = mk2_row(1, 1);
*
tri = appr_tri(tri, row);
*
if (n == 1) {
*
pr_tri(tri);
*
return;
*
}
tri = mk_pascal(tri,n);
*
pr_tri(tri);
*
}
*[1.5ex]
Hauptprogramm Zunächst wird die gewünschte Zeilenzahl aus der Kommandozeile gelesen; die erste Zeile wird mit dem Element 1 erzeugt (mit mk_one_row) und in das Dreieck übertragen (mit mk_one_tri). War die gewünschte Ordnung 0, so ist man bereits fertig. Sonst wird die nächste Zeile erzeugt (mit mk2_row) und an das Dreieck angehängt (mit appr_tri). War die gewünschte Ordnung 1, so ist man jetzt fertig. Für höhere Ordnungen wird die Funktion mk_pascal zur Erzeugung des gewünschten Dreiecks aufgerufen. Die Ausgabe des fertigen Dreiecks erfolgt in allen drei Fällen mit der Operation pr_tri, die natürlich nicht sehr schön ist; hier sollte man eine bessere Funktion schreiben.
Eine Falle bezüglich der Speicherverwaltung wurde hier umgangen: man könnte ja denken, daß es für die Erzeugung der Zeile mit der Ordnung 1 (also der zweiten Zeile) ausreicht, an die existierende Variable row eine weitere 1 anzuhängen -- das wäre aber verhängnisvoll, da durch das Eintragen von row in tri ein Verweis auf den aktuellen Zustand von row entstanden ist. Hängen wir nun ein weiteres Element an, taucht es wie von Geisterhand auch in der ersten Zeile des Dreiecks auf, wo es fehl am Platze ist! Aus diesem Grunde müssen wir den bisherigen Inhalt von row aufgeben und die zweite Zeile neu aufbauen; dies hätten wir z.B. auch durch einen Aufruf von copy1_row und Anfügen des zweiten Elements mit appr_row erreichen können.
Es fehlt nun noch die semantische Funktion mk_pascal, die ein wohlgeformtes Pascal-Dreieck (mit der Ordnung 1) und die gewünschte Ordnung als Argumente erwartet und daraus das gewünschte Pascal-Dreieck erzeugt.
Tri mk_pascal (Tri tri, Nat1 n)
*
{
*
Row row, last;
*
int i, len;
*[0.5ex]
if (n < 2)
*
return tri;
*
else {
*
row = mk_one_row(1);
*
len = len_tri(tri);
*
last = last_tri(tri);
*
for (i = 1; i < len; i++)
*
row = appr_row(row, sel_row(last,i) +
sel_row(last,i+1));
*
row = appr_row(row, 1);
*
tri = appr_tri(tri, row);
*
return mk_pascal(tri, n-1);
*
}
*
}
*[1.5ex]
mk_pascal Die Funktion prüft zunächst, ob das Dreieck bereits fertig ist -- dazu muß die Ordnung kleiner als zwei sein. Wenn ja, wird das bisher erstellte Dreieck zurückgeliefert. Im anderen Fall wird nun das erste Element der neuen Zeile (das ja immer 1 ist) eingetragen (mit mk_one_row). Die Zeilenzahl des bisherigen Dreiecks (also seine Ordnung plus eins) wird ermittelt (mit len_tri), um die Anzahl der Additionen, die für die neue Zeile erforderlich sind, zu bestimmen. Schließlich wird die Zeile, aus der die Elemente für die Addition entnommen werden (die bisher letzte Zeile des Dreiecks) mit last_tri herausgegriffen.
In der for-Schleife werden für die Zeile der Ordnung n, die ja n+1 Elemente enthält, n-1 Additionen durchgeführt, denn die beiden äußeren Elemente sind immer gleich 1. Das i.te Element der neuen Zeile (das wegen des bereits vorhandenen ersten Elements innerhalb der Zeile die Position i+1 einnimmt) ergibt sich als Summe der Elemente i und i+1 der vorigen Zeile, die jeweils mit sel_row ermittelt werden. Nach Verlassen der for-Schleife wird das letzte Element der Zeile, die rechte 1, angehängt und die fertige Zeile in das Dreieck eingetragen; danach wird mk_pascal mit um 1 verringerter Ordnung rekursiv aufgerufen.
VDM Class Library