 Tuples
Tuples
 Die VDM-Basistypen
Die VDM-Basistypen
 Elementare Datentypen
Elementare Datentypen
Definition Ein Set ist eine endliche, ungeordnete Sammlung von unterschiedlichen, aber dennoch gleichartigen Objekten. Etwas ausführlicher:
Mit diesen Eigenschaften ähnelt ein Set einer mathematischen Menge; diese jedoch kann auch unendlich groß sein (wie z.B. die Zahlenmengen). Die Beschränkung auf endliche Sets ist jedoch im Rahmen der Anwendung in der Programmierung vernünftig. Mathematische Mengen sind grundsätzlich ebenfalls ungeordnet, auch wenn die Zahlenmengen ein Ordnungprinzip aufzuweisen scheinen; dies ist jedoch den Objekten (Zahlen) immanent -- Punktmengen sind zum Beispiel ungeordnet.
DSL Um in der DSL-Spezifikation einen Set Aset
von Objekten eines Domains ![]() zu definieren, schreiben Sie
zu definieren, schreiben Sie
![]()
Anwendung Sie können Sets also einsetzen, wenn Sie Sammlungen von Objekten modellieren möchten, die ungeordnet sind und deren Elemente alle verschieden sind; außerdem sollte die Manipulation eines Sets auf dem Hinzufügen, Entfernen und (zufälligem) Auswählen von Objekten basieren.
Beispiel: Ein kleines Beispiel soll den Einsatz von Sets verdeutlichen: eine Schule besteht aus mehreren verschiedenen Klassen und in jeder Klasse sind verschiedene Schüler. Eine Klasse bildet demzufolge einen Set von Schülern, eine Schule ist ein Set von Klassen. Mehr noch: natürlich bildet auch die Schule einen Set von Schülern, der die gleiche Größe und die gleichen Elemente hat wie die Vereinigung aller Klassen. Die Anzahl der Schüler ist immer endlich und sie unterliegen keinem immanenten Ordnungssystem, also ist die Repräsentation durch Sets gerechtfertigt. Sie können also folgendes modellieren:
School=Class -set
*
Class =Student -set
Die Tatsache, daß auch Schulen Sets von Schülern sind, wird hiermit noch nicht wiedergegeben. Dazu könnten Sie einen weiteren Set Schoolofstudents einführen: um eine Schule als Set von Schülern zu betrachten, benötigen Sie dann eine Funktion, die ein Objekt School in ein äquivalentes Objekt des Typs Schoolofstudents überführt.
Während der Erläuterung der Operationen werden Sie diesen Domains immer wieder begegnen.
Zur Zeit gibt es für Sets nur die Implementation linklist . Sie wird auch für andere VDM-Basistypen verwendet; ihre Charakteristika finden Sie dort oder im Anhang C.
Zur Veranschaulichung der Operationen dienen folgende Variablen:
Schools1, s2;
*
Class c1, c2;
*
Student st1, st2;
VDM bietet Ihnen vier Operationen zur Erzeugung von Set-Objekten:
mk_empty Mitmk_emptyerzeugen
Sie einen neuen, leeren Set.
*
Beispiel -- Gründung einer Schule:
s1 = mk_empty_school();
*[1.5ex]
mk_oneMitmk_oneerzeugen Sie
einen neuen, ein-elementigen Set.
*
Beispiel -- Eröffnung einer Klasse mit folgender Gründung einer Schule, die
diese eine Klasse umfaßt:
c1 = mk_empty_class();
*
s2 = mk_one_school(c1);
*[1.5ex]
copy / copy1 copy und copy1 haben Sie ja bereits kennengelernt -- diese Operationen stehen für alle strukturierten Typen zur Verfügung.
union Die Vereinigung zweier Sets ( s1
![]() s2 ) heißtunionund enthält alle Elemente, die in
einem der beiden Sets enthalten sind. Es gibt häufig den Wunsch, dem Set genau
ein Objekt hinzuzufügen, also einen ein-elementigen Set. Um nun nicht den
Umweg über die Erzeugung eines solchen Set gehen zu müssen, gibt es dafür die
union1 Operation union1.
s2 ) heißtunionund enthält alle Elemente, die in
einem der beiden Sets enthalten sind. Es gibt häufig den Wunsch, dem Set genau
ein Objekt hinzuzufügen, also einen ein-elementigen Set. Um nun nicht den
Umweg über die Erzeugung eines solchen Set gehen zu müssen, gibt es dafür die
union1 Operation union1.
*
Beispiel -- das Hinzufügen einer Klasse zu einer Schule läßt sich auf zwei
Weisen darstellen:
union1_school(s1,c1) ![]() union_school(s1,mk_one_school(c1))
union_school(s1,mk_one_school(c1))
*[1ex]
Zusätzlich gibt es die Versionen uniond und union1d mit implizitem Löschen.
inters Der Durchschnitt zweier Sets ( s1
![]() s2 ) heißtintersund enthält die Elemente, die in
beiden Sets enthalten sind. intersdlöscht implizit.
s2 ) heißtintersund enthält die Elemente, die in
beiden Sets enthalten sind. intersdlöscht implizit.
*
Beispiel -- der Durchschnitt zweier Schulen ist natürlich leer, da keine
Klasse zu zwei Schulen gehören kann:
is_empty_school(inters_school(s1,s2)) == TRUE
*[1.5ex]
diff Die Set-Subtraktion ( s1 \ s2 )
heißtdiffund enthält alle Elemente, die im ersten, aber
nicht im zweiten Set enthalten sind. Auch hier gibt es eine Vereinfachung,
wenn Sie nur ein Element aus einem Set entfernen möchten:
sub1 sub1. Hinzu kommen diffd und
sub1d, die implizit löschen.
Beispiel -- eine Klasse in einer Schule wird geschlossen:
s1 = sub1_school(s1,c1);oder
*
s1 = diff_school(s1,mk_one_school(c1));
*[1.5ex]
is_eq Mitis_eqtesten Sie die
Gleichheit zweier Sets, d.h. ob sie die gleiche Kardinalität (Element-Anzahl)
haben und die gleichen Elemente enthalten.
Beispiel -- zwei Schulen haben nie die gleichen Klassen:
is_eq_school(s1,s2) == FALSE
*[1.5ex]
is_empty Mitis_emptytesten
Sie, ob ein Set gerade keine Elemente enthält.
Beispiel -- eine neugegründete Schule hat zunächst keine Klassen:
is_empty_school(mk_empty_school()) == TRUE
*[1.5ex]
is_in Mitis_in können Sie testen,
ob ein bestimmtes Element in einem Set enthalten ist ( c1 ![]() s1 ).
s1 ).
Beispiel -- ist ein bestimmter Schüler in einer bestimmten Klasse ?
if (is_in_class(st1,c1)) ...
*[1.5ex]
is_subset Mit is_subset können Sie
testen, ob alle Elemente eines Set auch in einem anderen Set des gleichen Typs
enthalten sind (Teilmengen-Beziehung, c1 ![]() c2 ).
c2 ).
Beispiel -- die Schüler einer Klasse sind nie vollständig auch in
einer anderen Klasse:
is_subset_class(c1,c2) == FALSE
*[1ex]
Der leere Set ist in jedem anderen Set enthalten:
is_subset_xxx(mk_empty_xxx(),xxx) == TRUE
*
card Die Kardinalität eines Set, d.h. die
aktuelle Anzahl von Elementen, liefert Ihnencard. Der leere Set
hat die Kardinalität 0.
Beispiel -- Ermittlung der Schülerzahl in einer Klasse:
printf("%d",card_class(c1));
*[1ex]
sel Mitselwählen Sie
zufällig ein Element eines nicht-leeren Set aus.
*
Beispiel -- Auslosung des Klassensprechers in einer Schulklasse:
st1 = sel_class(c1);
*[1.5ex]
Zur Erzeugung neuer, komplexer Funktionen mit Hilfe der vorhandenen gibt es zwei Funktionale , das sind Funktionen, die wieder Funktionen zurückliefern. In der DSL-Spezifikation geben Sie dazu den Namen des Funktionals, gefolgt von einem Punkt und dem Namen der zu erzeugenden Funktion an. Wie üblich folgen dann in Klammern die Parameter des Funktionals.
binary Mitbinarykönnen binäre Funktionen, die aus einem Set und einem Element einen neuen Set erzeugen, verallgemeinert werden zu Funktionen, die aus zwei Sets einen neuen Set erzeugen und dabei ihre Argumente zerstören. Eine mit binary erzeugte Funktion arbeitet wie folgt:
Aset newfct_aset (Aset s1, Aset s2)
*
{
*
Elem e;
*[0.5ex]
if (is_empty_aset(s2))
*
return s1;
*
else {
*
e = sel_aset(s2);
*
return newfct_aset(foldfct_aset(s1,e), sub1_aset(s2,e)) ;
*
}
*
}
*[1.5ex]
foldfct ist die Funktion, die binary als Parameter übergeben wurde. Sie hat zwei Argumente, einen Set und ein Element, und liefert wieder einen Set; Sie legen sie in der DSL-Spezifikation mit dem Parameter Parameter ,,FOLDFCT`` fest. Für die Funktion newfct_aset sieht das so aus:
IMPLEMENTATIONS
*
...+ binary.newfct(FOLDFCT="foldfct")
*[1.5ex]
Nomenklatur Beachten Sie, daß sowohl der Name der erzeugten Funktion (newfct) als auch der Name der Parameterfunktion (foldfct) als generische Namen aufgefaßt werden; sie werden mit dem zugehörigen Set-Namen erweitert. Falls Sie also eine selbstdefinierte Funktion als Parameterfunktion einsetzen möchten, geben Sie ihr den richtigen Namen! Im ADT-Implementations-Modul wird dann eine Funktion ähnlich der obenstehenden erzeugt; damit es auch compiliert werden kann, wird in der Header-Datei für die Parameterfunktion eine Deklaration eingetragen.
Beispiel -- die Operation union kann mit Hilfe von binary und union1 definiert werden:
IMPLEMENTATIONS
*
...+ binary.union(FOLDFCT="union1")
*[4ex]
fold Das Funktionalfoldist wesentlich komplexer: es hat drei Parameter-Funktionen und erzeugt eine Funktion, die einen Set auf einen durch die Parameter-Funktionen festgelegten Resultattyp abbildet. Damit lassen sich sehr gut komplexe Manipulationen aller Elemente einer Menge realisieren. Die Parameter-Funktionen haben folgende Bedeutung:
In Klammern ist der jeweilige Parametername für die DSL-Spezifikation angegeben; hinzu kommt noch der optionale Parameter RESULT,,RESULT``, der den Resultattyp angibt für den Fall, daß es nicht der Elementtyp ist.
Die erzeugte Funktion sieht von der Struktur her wie folgt aus:
Result newfct_aset (Aset s)
*
{
*
Elem e;
*[0.5ex]
if (is_empty_aset(s))
*
return nullfct_result();
*
else {
*
e = sel_aset(s);
*
return foldfct_result(cvfct_elem(e),
*
newfct_aset(sub1_aset(s,e)));
*
}
*
}
Die Verarbeitung ähnelt also strukturell dem Funktional binary, nur die Resultate werden auf komplexere Weise erzeugt.
Nomenklatur Die Namen der drei Parameterfunktionen und der erzeugten Funktion werden erweitert, wie Sie in der obigen Funktion sehen können:
Beispiel 1 Eine häufige Anwendung von fold ist die distributive Vereinigung aller Sets in einem Set von Sets, also z.B. die Zusammenlegung aller Klassen einer Schule zu einer neuen Klasse:
IMPLEMENTATIONS
*
...+ fold.d_union(NULLFCT="mk_empty",
FOLDFCT="union")
*
erzeugt
*
Class d_union_school (School s)
*[1ex]
Da der Resultattyp hier identisch mit dem Elementtyp des Set school ist, braucht keine Konvertierungsfunktion angegeben zu werden, ebensowenig wie der Parameter ,,RESULT``.
Beispiel 2 Gelegentlich möchten Sie testen, ob entweder für alle Elemente eines Set ein bestimmtes Prädikat erfüllt ist oder ob es mindestens ein solches Element gibt. Dafür haben sich die folgenden Schreibweisen eingebürgert:
![]()
*
![]()
*[1.5ex]
Mit fold können Sie beide Tests generieren; Sie benötigen dazu Operationen für den Datentyp Bool. ,,forall`` ist für den leeren Set erfüllt, ansonsten wird das Prädikat für jedes Element geprüft und die Resultate AND-verknüpft. ,,exists`` ist für den leeren Set nicht erfüllt, ansonsten werden die Resultate des Prädikats OR-verknüpft.
fold.forall(RESULT=
"Bool",
*
CVFCT="Predicate",
*
NULLFCT="true",
*
FOLDFCT="and")
[1ex]
fold.exists (RESULT="Bool",
*
CVFCT="Predicate",
*
NULLFCT="false",
*
FOLDFCT="or")
Der VDM-Compiler erkennt übrigens nicht, welche
Standard-Operationen für irgendwelche mit binary oder fold
definierte Funktionen notwendigerweise eingebunden werden müssen! Sie müssen
sie also in Ihrer DSL-Spezifikation explizit anfordern, sonst erhalten Sie
einen Fehler beim Binden, z.B.
*
,,undefined function mk_empty_class``.
Zusätzliche Parameter Manchmal benötigen die Parameterfunktionen ihrerseits noch weitere Argumente; vielleicht ist die Konvertierung eines Elements nur möglich, wenn Zusatzinformationen vorliegen. Die Erzeugung der Deklaration in der Header-Datei ist natürlich nur möglich, wenn der Typ dieser zusätzlichen Argumente bekannt ist; Sie geben dazu dem Funktional fold weitere Parameter:
Beim Aufruf der erzeugten Funktion geben Sie die zusätzlichen Argumente in der entsprechenden Reihenfolge an, zuerst die mit den X..., danach die mit Y... und am Ende die mit Z... vereinbarten Argumente. Die Funktionsdeklaration sieht dann wie folgt aus:
Result newfct_aset (Āset as,
*
X x1,
*
XX x2, ...,
*
Y y1, ...,
*
ZZZ z3)
*
Eine Anwendung dafür finden Sie im Abschnitt 5.6 5.6 über Maps.
forall Mitforallwird für alle
Elemente eines Set eine angegebene Prozedur ausgeführt, die das aktuelle
Element als Argument erhält.
*
Beispiel -- die klassenweise Ausgabe aller Schüler einer Schule mit der
Ausgabe-Operation pr:
forall_school(s1,pr_class);
*[1.5ex]
forsome Mitforsomewird mit
allen Elementen eines Set, die ein angegebenes Prädikat erfüllen (in Form
einer Funktion mit bool-Resultat), eine Prozedur ausgeführt.
Beispiel -- die klassenweise Ausgabe aller Schüler einer Schule, wobei leere
Klasssen automatisch unterdrückt werden:
forsome_school(s1,not_empty_class,pr_class);
*[0.5ex]
Definition von not_empty_class:
*[0.5ex]
Bool not_empty_class (class c)
*
{ return !is_empty_class(c) }
*[1.5ex]
Wir haben beliebige, nicht-leere Sets gegeben, die nicht überschneidungsfrei sind. Daraus soll nun die ,,coarsest partitioning`` erzeugt werden -- die ,,gröbste Zerlegung`` dieser Sets, die aus nicht-leeren, aber überschneidungsfreien Sets besteht, bei minimaler Anzahl an Element-Sets. Sie sehen: die ,,coarsest partitioning`` ist kein selbständig definierter Begriff, sondern nur relativ zu einem Ausgangszustand definiert. Graphisch veranschaulicht diesen Vorgang Abb. 5.2.
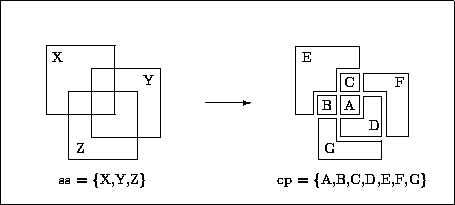
Abbildung: Beispiel für Sets: das ,,coarsest partitioning``-Problem
DSL Wir können bereits die DSL-Spezifikation für dieses Problem festlegen: ein Domain Aset mit beliebigen Elementen (in unserem Beispiel natürliche Zahlen), ein Domain Sset mit Elementen vom Typ Aset, also ein Set von Sets. In der Abbildung sind die Sets ss und cp vom Typ Sset, alle übrigen vom Typ Aset.
DOMAINS
*[0.5ex]
Aset=Nat0 -set
*
Sset = Aset -set
*[0.5ex]
IMPLEMENTATIONS
*
Aset = linklist + ...
*
Sset = linklist + ...
*
Der Ablauf einer Zerlegung sieht folgendermaßen aus: solange noch Sets im
Gesamt-Set vorhanden sind, deren Durchschnitt nicht-leer ist, wählen wir ein
Paar solcher Sets (x,y) aus, entfernen sie aus dem Gesamt-Set
(s\{ x,y }) und fügen diesem dann drei neue, nicht-leere Sets hinzu:
(x \ y), (y \ x) und (x ![]() y) -- falls einer dieser Sets
leer ist, wird er ignoriert. Mit diesem neukonstruierten Gesamt-Set verfahren
wir ebenso, bis er schließlich kein Paar sich überschneidender Sets mehr
enthält. Der dabei entstehende Gesamt-Set ist die ,,coarsest partitioning``
des Ausgangszustands.
y) -- falls einer dieser Sets
leer ist, wird er ignoriert. Mit diesem neukonstruierten Gesamt-Set verfahren
wir ebenso, bis er schließlich kein Paar sich überschneidender Sets mehr
enthält. Der dabei entstehende Gesamt-Set ist die ,,coarsest partitioning``
des Ausgangszustands.
Spezifikation mit VDM Hier sehen Sie die VDM-Funktions-Spezifikation für eine semantische Funktion decompose zur Ermittlung der ,,coarsest partitioning`` unter Verwendung der VDM-Notation.
TYPE decompose (Ss):Sset ![]() Sset
Sset
*
decompose =
*
if ( ![]() x,y
x,y ![]() Ss) ((x
Ss) ((x ![]() y)
y) ![]() (x
(x ![]() y)
y)
![]() {}))
{}))
*
then (let {x,y} ![]() Ss be s.t. ((x
Ss be s.t. ((x
![]() y)
y) ![]() (x
(x ![]() y)
y) ![]() {})) in
{})) in
*
decompose(({x\y , y\x , x ![]() y}
y} ![]() Ss
Ss
\ {x,y}) \ {})
*
else Ss
*[1.5ex]
Sie lesen die VDM-Spezifikation folgendermaßen: ,,Für den Fall, daß es noch irgend zwei verschiedene Sets im Gesamt-Set gibt, die sich überschneiden, so wähle x und y so, daß sie zwei sich überschneidende Sets im Gesamt-Set darstellen und führe damit den Aufruf von decompose aus; sonst liefere den Gesamt-Set zurück``. Das Argument des rekursiven decompose-Aufrufs wird wie oben angegeben ermittelt -- beachten Sie: eine der beiden Set-Differenzen könnte leer sein, daher wird vom neukonstruierten Set Ss sicherheitshalber der leere Set subtrahiert.
Die semantische Funktion decompose_sset, die ein wohlgeformtes Objekt vom Typ Sset (das nicht-leer ist und nur nicht-leere Element-Sets enthält) in ihre ,,coarsest partitioning`` umwandelt, codieren wir nun in C:
#define TRUE 1
*
#define FALSE 0
*
Sset decompose_sset (Sset ss)
*
{
*
Aset a1,a2,sav1,sav2;
*
Sset ss1,ss2;
*
Bool found = FALSE;
ss1 = copy1_sset(ss);
*
while (!found && !is_empty_sset(ss1)) {
*
a1 = sel_sset(ss1);
*
ss1 = sub1_sset(ss1,a1);
*
ss2 = copy1_sset(ss1);
*
a2 = find_partner(ss2,a1);
*
found = !is_empty_aset(a2);
*
}
del1_sset(ss1);
*
if (!found)
*
return(ss);
else {
*
ss = sub1_sset(ss,a1);
*
ss = sub1_sset(ss,a2);
*
sav1 = copy1_aset(a1);
*
sav2 = copy1_aset(a2);
*
ss = union1_sset(ss,inters_aset(sav1,sav2));
*
sav1 = copy1_aset(a1);
*
a1 = diff_aset(a1,a2);
*
a2 = diff_aset(a2,sav1);
*
del1_aset(sav1);
*[0.5ex]
if (!is_empty_aset(a1))
*
ss = union1_sset(ss,a1);
*
if (!is_empty_aset(a2))
*
ss = union1_sset(ss,a2);
*
return(decompose_sset(ss));
*
}
*
}
*[1.5ex]
decompose_sset Zunächst müssen zwei Sets gesucht werden, die sich überschneiden. Dazu wird zunächst eine Kopie des Gesamt-Set angelegt (copy1_sset), danach solange ein Set dem Gesamt-Set entnommen (sel_sset und sub1_sset), bis mit Hilfe der Funktion find_partner (die ihr Argument zerstört, daher die Kopie in ss2), ein solches Paar gefunden wurde (found = TRUE) oder der Gesamt-Set leer ist (is_empty_sset). Im letzteren Fall ist man fertig.
Nachdem die while-Schleife verlassen wurde, ist ss2 zerstört, ss1 aber nicht. Der Aufruf von del1_sset sorgt dafür, daß kein Speicherplatz vergeudet wird. Wie Sie sehen, reicht die Kopie der Haupt-Struktur (mit copy1) aus, da die Sub-Strukturen nicht verändert werden.
Für den Fall, daß ein Paar sich überschneidender Sets existiert, ist es in den Variablen a1 und a2 gespeichert. Nun werden diese beiden Sets -- entsprechend dem oben geschilderten Ablauf -- aus dem Gesamt-Set entfernt (mit sub1_sset). Danach wird der garantiert nicht-leere Durchschnitt der beiden Sets, der mit inters_aset ermittelt wurde, eingefügt (mit union1_sset). Die beiden Differenz-Sets werden mit Hilfe von diff_aset erzeugt und in denselben Variablen abgelegt. Weil dabei der leere Set entstehen kann, wird mit is_empty_aset überprüft, ob eine Aufnahme in den Gesamt-Set erforderlich ist. Schließlich wird decompose_sset mit diesem veränderten Gesamt-Set rekursiv aufgerufen.
find_partner Die Hilfsfunktion find_partner erledigt die Suche nach einem Set, der mit dem Argument einen nicht-leeren Durchschnitt hat. Sie liefert bei Mißerfolg den leeren Set zurück; das ist sinnvoll, weil die Element-Sets per Definition nicht-leer sind!
Aset find_partner (Sset ss,Aset as)
*
{
*
Aset sav1,sav2;
*
Aset ret;
*[0.5ex]
if (is_empty_sset(ss))
*
return(mk_empty_aset());
*
else {
*
ret = sel_sset(ss);
*
ss = sub1_sset(ss,ret);
*
sav1 = copy1_aset(as);
*
sav2 = copy1_aset(ret);
*[0.5ex]
if (!is_empty_aset(inters_aset(sav1,sav2))) {
*
del1_sset(ss);
*
return(ret);
*
}
*
else
*
return(find_partner(ss,as));
*
}
*
}
*[1.5ex]
Auch find_partner ist eine rekursive Funktion: mit jedem Aufruf wird die Anzahl der Element-Sets im Gesamt-Set um eins kleiner -- ist kein Set mehr übrig, war die Suche erfolglos.
Bei jedem Aufruf wird dem Gesamt-Set ein Element-Set entnommen (mit sel_sset und sub1_sset) und überprüft, ob der Durchschnitt mit dem Argument-Set leer ist (mit is_empty_aset und inters_aset) -- wenn nicht, ist ein Paar gefunden und der Gesamt-Set muß ,,per Hand`` zerstört werden (explizit mit del1); wenn doch, wird find_partner rekursiv aufgerufen.
VDM Class Library