*[0.5ex] {
* if (im != 0.0) {
* (
* (
* }
* return (im != 0.0);
* }
*[4ex]
 Das VDM-System unter UNIX
Das VDM-System unter UNIX
 Vienna Development Method
Vienna Development Method
 Vienna Development Method
Vienna Development Method
Eine Modellspezifikation besteht in VDM aus einer Klassen-Definition (der sogenannten Domain-Gleichung), der Bedingung für die Wohlgeformtheit eines Objekts dieser Klasse und der Definition aller Funktionen, die mit diesen Objekten umgehen. Der Begriff Klasse bzw. Domain wird meist synonym mit dem Begriff ,,abstrakter Datentyp`` verwendet, ist aber allgemeiner und umfaßt alle möglichen Datentypen. In diesem Abschnitt werden diese Begriffe zunächst definiert; die konkrete Darstellung in der VDM-Notation folgt im nächsten Abschnitt.
Definition: Eine Domain-Gleichung gibt den Namen und die syntaktische Struktur einer Klasse von Objekten an, d.h. aus welchen Bestandteilen ein Objekt besteht und wie diese Bestandteile strukturiert sind. Sie dient also als ,,Bauplan`` für die Objekte.
Beispiel: Die Definition neuer Datentypen in C mit dem typedef-Befehl ist in diesem Sinne auch eine Domain-Gleichung: Es wird ein Name definiert, der als Strukturbeschreibung einer Klasse von Objekten dient. Um eine Klasse IMAG von imaginären Zahlen zu definieren, dient folgender Befehl:
typedef struct {
*
doublere, im;
*
} IMAG;
*[2ex]
In VDM ist der Begriff ,,Domain-Gleichung`` etwas enger gefaßt, er bezieht sich nur auf die mit Hilfe von VDM definierten abstrakten Datentypen -- wie eine ,,echte`` Domain-Gleichung aussieht, erfahren Sie im Abschnitt 3.1.2. Die Sammlung aller Domain-Gleichungen, Abstrakte Syntax die für eine Applikation benötigt werden, heißt abstrakte Syntax .
Mit Daten repräsentiert ein Programm Objekte der Realität. Selbst wenn Sie die Struktur eines Objekts richtig erkannt und formalisiert haben, ergeben sich daraus viele mögliche Zustände, die ein Objekt in der Realität nie einnehmen wird. Das Programm sollte mit solchen Zuständen nicht umgehen, da die Repräsentation der Realität in diesem Fall nicht korrekt ist. Wohlgeformtheit Die Bedingung für die Wohlgeformtheit ist eine Funktion, die die realen Zustände eines Objekts formalisiert und somit erlaubt, die Korrektheit eines Datums im Programm diesbezüglich zu testen. Ist der Zustand erlaubt, ist das Datum wohlgeformt. Die Domain-Gleichung enthält keine Informationen darüber; daher ist es sinnvoll, ein Kriterium dafür zu definieren. Alle Funktionen, die ein neues Objekt der Klasse erzeugen oder ein existierendes manipulieren, müssen diese Bedingung kennen und einhalten. Eine andere Bezeichnung für diese Bedingung ist Datentyp-Invariante .
Beispiel: Die oben definierte Klasse von imaginären Zahlen erlaubt auch Zahlen, deren Imaginär-Teil gleich Null ist, also reelle Zahlen; in diesem Fall hätte das Objekt einen Zustand, der sinnlos ist, da es ja nur die imaginären Zahlen repräsentieren soll. Abhilfe schafft die Funktion
Bool is_IMAG (IMAG i)
*
{ return i.im != 0.0 }
*[3ex]
Semantische Funktionen Die Funktionen, die mit den Objekten einer Klasse umgehen, diese also manipulieren, werden auch semantische Funktionen genannt. Im Gegensatz zum allgemeinen modellorientierten Ansatz können dies auch komplexe Manipulationen sein, die die Applikation benötigt. Wenn Sie allerdings einen ADT definieren (und das ist fast immer der Sinn einer Modellspezifikation), sollten Sie sich trotzdem die Mühe machen, bestimmte Funktionen zu definieren, die allein den ADT ,,charakterisieren`` (also Operationen im Sinne der ADT-Definition) -- damit erreichen Sie eine gewisse Unabhängigkeit des ADT von dem spezifischen Problem, wodurch die Wiederverwendbarkeit des ADT zunimmt. Die komplexen Funktionen, die die Applikation benötigt, geben dazu Hinweise: sie führen meist mehrere, elementare Manipulationen an den Objekten aus. Diese Hilfsfunktionen ,,Hilfsfunktionen`` sollten Sie in allen komplexen Funktionen identifizieren -- sie bilden in der Regel eine Menge von für den ADT ,,charakteristischen`` Funktionen, passen also in unsere Definition für Operationen!
Beispiel: Für unsere imaginären Zahlen benötigen wir natürlich Funktionen, um mit ihnen zu rechnen, also etwa imaginäre Addition, Subtraktion, Multiplikation usw. Hier sei eine Additionsfunktion definiert:
IMAG add_IMAG (IMAG i, IMAG j)
*[0.5ex]
{
*
i.re+=j.re;
*
i.im+=j.im;
*
return i;
*
}
*[2ex]
Konstruktor Eine Funktion müssen Sie in jedem Fall definieren, den Konstruktor für ein wohlgeformtes Objekt der Klasse. Natürlich kann es mehrere verschiedene Konstruktoren für eine Klasse geben, die sich durch die Parameter unterscheiden. Beispiel für einen sinnvollen Konstruktor einer imaginären Zahl:
IMAG mk_IMAG (double re, double im)
*[0.5ex]
{
*
IMAG new;
*
new.re=re;
*
new.im=im;
*
return new;
*
}
*[2ex]
Ein anderer Konstruktor könnte die neue Imaginärzahl mit dem Inhalt einer bereits existierenden initialisieren.
In den beiden letzten Beispielen wurde übrigens -- Sie haben es vielleicht bemerkt -- die Wohlgeformtheit? Datentyp-Invariante nicht beachtet! Zur Lösung dieses Problems wird jeweils eine zweite Funktion benötigt, die die Imaginärzahl als Referenzparameter (,,Call by Reference``) hat und einen Wahrheitswert zurückliefert. Am Beispiel des Konstruktors:
Bool test_mk_IMAG (IMAG ![]() i, double re, double im)
i, double re, double im)
*[0.5ex]
{
*
if (im != 0.0) {
*
( ![]() i).re = re;
i).re = re;
*
( ![]() i).im = im;
i).im = im;
*
}
*
return (im != 0.0);
*
}
*[4ex]
Nachdem nun die Begriffe bekannt sind, wollen wir sehen, wie solch eine Spezifikation in VDM aussieht. VDM unterstützt die repräsentationale Abstraktion durch die Domain-Gleichungen, die operationale Abstraktion durch die Funktions-Spezifikation.
Mit der Domain-Gleichung wird die innere Struktur modelliert. Dafür stehen eine Reihe von Datenstrukturen zur Verfügung, um eine optimale Anpassung des benötigten ADT an die von der Applikation gestellten Anforderungen zu erreichen: VDM-Basistypen die VDM-Basistypen . Sie können diese Datentypen beliebig schachteln, auch rekursive Strukturen sind möglich. Allerdings ist folgendes zu bedenken:
Der modellorientierte Ansatz fordert bei der Definition der ADT die möglichst frühzeitige Bezugnahme auf die in der Methode vorhandenen ,,Modelle`` von Datenstrukturen (wie im Abschnitt 2.3 dargestellt). Gleichwohl kann die Entwicklerin zunächst eine losgelöste Spezifikation erstellen, wenn die Methode das sprachlich unterstützt. Die FH-Installation von VDM bietet eine solche Unterstützung leider nicht an -- Sie sollten also nur die VDM-Basistypen verwenden, die aber so mächtig sind, daß eine Lösung damit in der Regel leichtfällt.
Notation Für jeden VDM-Basistyp gibt es eine spezielle Notation. Sie lernen jetzt diese Datentypen kennen, allerdings nur in knapper Form, da Kapitel 5 sich ausführlich mit allen VDM-Basistypen befaßt. Die englischen Namen werden verwendet, weil sie üblich sind -- dadurch werden Sie mit der Nomenklatur der FH-Installation vertraut.
Den Set (Menge ) kennen Sie aus dem Bereich der
Mathematik: er enthält eine beliebige Anzahl von Elementen des Elementtyps
ohne festgelegte Reihenfolge. Einen Set ![]() von Elementen des Typs
von Elementen des Typs ![]() definieren Sie mit
definieren Sie mit
Set ![]() -set
-set
*[2ex]
Das Tuple (Liste) ist eine Erweiterung der aus
C bekannten eindimensionalen Tabelle, also einer Sequenz von
gleichartigen Elementen. Allerdings brauchen Sie keine Obergrenze
festzulegen! Einen Tuple ![]() von Elementen des Typs
von Elementen des Typs ![]() definieren
Sie mit
definieren
Sie mit
Tuple ![]()
*[2ex]
Die Map (Abbildung) ist eine Funktion mit
endlicher Argumentmenge, also die Menge aller Paare (a,b), für die gilt:
jedem a ist höchstens ein b zugeordnet. die a heißen
Argumentwerte , die b heißen
Map-Werte (analog zum Begriff ,,Funktionswert``). In der
Terminologie von VDM heißt die Argumentmenge auch
Argument-Domain , die Zielmenge
Co-Domain . Eine Map ![]() von Paaren (a,b) mit
von Paaren (a,b) mit
![]() und
und ![]() definieren Sie mit
definieren Sie mit
Map ![]()
*[2ex]
Der Tree (Verbund) ist eine geordnete
Sammlung von Elementen unterschiedlichen Typs, die einzeln benannt sind,
ähnelt also dem struct in C. Einen Tree ![]() der
Elementtypen
der
Elementtypen ![]() ...
... ![]() definieren Sie mit
definieren Sie mit
Tree ![]() ::
:: ![]()
*[1ex]
Benötigen Sie den Tree nur als Elementtyp innerhalb eines anderen ADT, brauchen Sie ihm keinen Namen geben -- stattdessen wird die Folge der Elementtypen in runde Klammern eingeschlossen. Ein solcher Tree heißt anonym.
![]()
*[2ex]
Die Union (Variante) enthält ein
Datenelement, das aber einer Reihe verschiedener Datentypen angehören kann und
den Elementtyp auch während seiner Existenz wechseln kann, entspricht also der
gleichnamigen union in C. Eine Union ![]() der Elementtypen
der Elementtypen
![]() ...
... ![]() definieren Sie mit
definieren Sie mit
Union ![]()
*[2ex]
Das Optional enthält zu einem bestimmten Zeitpunkt
entweder ein Objekt des Elementtyps oder den Wert nil , der
soviel bedeutet wie ,,gar nichts``. In C gibt es z.B. den speziellen
Wert NULL für Pointer, die gerade auf kein Objekt zeigen. Technisch
wird er bei fast allen C-Compilern durch den long-Wert 0
dargestellt, weil die Speicheradresse 0 für Daten eines Anwenderprogramms
nicht zugänglich ist; könnte auch dort ein Datum gespeichert sein, müßte
NULL auf andere Weise definiert sein, der Zahlentyp long wäre
ungeeignet. In solchen Fällen ist der Typ Optional sehr nützlich. Ein Optional
![]() von Elementen des Typs
von Elementen des Typs ![]() definieren Sie mit
definieren Sie mit
Optional ![]()
*[2ex]
Um eigene Datentypen zu modellieren, können Sie diese VDM-Basistypen beliebig verschachteln!
Die Bedingung für die Wohlgeformtheit eines Objekts ist ein sogenanntes Prädikat : die Beschreibung einer Eigenschaft, die ein Objekt haben kann oder nicht. Sie läßt sich als Funktion auffassen, die einen logischen Wahrheitswert zurückliefert. Zur Beschreibung eignen sich demzufolge die logischen Verknüpfungen, die Vergleichsoperatoren und alle weiteren Operatoren, die true und false als Ergebnis haben (hier eine Auswahl):
Außerdem können Sie die Sprachelemente verwenden, die für die Funktionsspezifikation zur Verfügung stehen, denn die Datentyp-Invariante ist letztlich nur eine spezielle Funktion.
Beispiel: Die allgemeine Darstellung der Datentyp-Invarianten einer imaginären Zahl sieht so aus:
inv-IMAG(re, im)=(im ![]() 0.0)
0.0)
*[2ex]
Sie sollten die Datentyp-Invariante so genau wie möglich definieren; durch die Anwendung in Ihrer Applikation werden undefinierte Zustände vermieden, also wird deren Konsistenz und Korrektheit wahrscheinlicher. Haben Sie die Datentyp-Invariante als Funktion implementiert, sollten Sie sie bei jeder Manipulation eines Objekts aufrufen und eine entsprechende Fehlerbehandlung vorsehen (wie im Beispiel mit den imaginären Zahlen in der Funktion test_mk_IMAG), wenn dadurch die Laufzeit nicht unzumutbar ansteigt -- im Zweifel ist ein sicheres, langsames Programm besser als ein schnelles, aber fehlerhaftes, gerade wenn es mit sensiblen Daten arbeitet, und Probleme bei der Performance lassen sich mit leistungsfähigerer Hardware meist beseitigen. Es ist in jedem Fall guter Programmierstil, daran zu denken.
VDM propagiert die beiden üblichen Möglichkeiten der konstruktiven und der impliziten Spezifikation von semantischen Funktionen . Bei beiden Arten definieren Sie zunächst die Syntax der Funktion und ihre precondition.
Syntaxdefinition Zunächst muß die Syntax der Funktion mit der TYPE-Klausel definiert werden:
TYPE Name (Argumentliste) : Argumenttyp-Liste ![]() Resultattyp
Resultattyp
*[1.5ex]
Die Argumentliste enthält die Namen der Argumente, wie sie in der weiteren Spezifikation verwendet werden; werden sie nicht gebraucht, können Sie sie weglassen. Die Argumenttyp-Liste legt die Definitionsmenge der Funktion fest, der Resultattyp (wie zu erwarten war) die Zielmenge. Handelt es sich um einen Konstruktor ohne Argumente oder um eine Prozedur ohne Resultat, können Sie den entsprechenden Teil ebenfalls weglassen.
Beispiele Die ersten drei Beispiele beziehen sich auf Operationen des VDM-Basistyps Set, das letzte definiert die Syntax der imaginären Addition.
TYPE mk_empty_aset (): ![]() Aset
Aset
*
TYPE is_empty_aset(aset):Aset ![]() Bool
Bool
*
TYPE print_aset (aset):Aset ![]()
*[0.5ex]
TYPE add_IMAG (i,j):IMAGIMAG ![]() IMAG
IMAG
*[2ex]
precondition Die precondition stellt eine Vorbedingung für den Funktionsaufruf dar -- ist sie nicht erfüllt, darf die Funktion nicht aufgerufen werden, da sonst undefinierte Zustände entstehen können. Die precondition kann mit den gleichen Mitteln spezifiziert werden wie die Datentyp-Invariante, da beides Prädikate sind. Die Datentyp-Invariante ist übrigens eine implizite precondition, da die Funktion nur mit sinnvollen Zuständen der Objekte auch sinnvoll umgehen kann. Format der precondition:
pre:Bedingung
*[1ex]
Die Bedingung wird als logischer Ausdruck formuliert, der entweder true oder false ergibt. Ist keine precondition nötig, schreiben Sie pre: true oder Sie lassen sie weg.
Beispiel: Die precondition der Addition zweier Imaginärzahlen muß ausdrücken, daß die Summe wieder eine Imaginärzahl sein wird, mit einen Imaginärteil ungleich 0:
pre: i.im + j.im ![]() 0
0
*[1.5ex]
Die Implizit... implizite Spezifikation fügt nur noch eine postcondition hinzu, ein weiteres Prädikat , das eine Aussage über den Programmzustand nach der Abarbeitung der Funktion macht, vorzugsweise natürlich über das Resultat der Funktion. Wie die Funktion dieses Resultat erreicht, wird nicht angegeben. erstellen, da man den Sinn der Funktion (ihre Semantik ) bei ihrer Spezifikation schon kennt -- sonst bräuchte man sie ja gar nicht. Leider ist diese Form der Spezifikation nicht sehr hilfreich, wenn es an die Implementation geht, daher sollte sie in jedem Falle nur als erster Ansatz gesehen werden; im weiteren Verlauf der Entwicklung muß daraus eine konstruktive Spezifikation entstehen. Format der postcondition:
post:Bedingung
*[1.5ex]
Beispiel: Eine mögliche, nicht sehr geistreiche postcondition der Addition zweier Imaginärzahlen ist
post: sum = Complex-Sum(i,j) ![]() is-IMAG(s)
is-IMAG(s)
*[2ex]
Complex-Sum sei ein informaler Name für die komplexe Addition, die ja für Imaginärzahlen verwendet werden muß, is-IMAG ist ein Prädikat, wie es in einem der ersten Beispiele dieses Kapitels kurz angesprochen wurde.
Die Konstruktiv...konstruktive Spezifikation beschreibt die Arbeitsweise der Funktion möglichst exakt; VDM stellt dafür die Sprache META-IV mit einer Kombination aus funktionalen und prozeduralen Sprachelementen Das Funktionsergebnis wird durch einen Ausdruck definiert, der beliebig tief verschachtelt sein kann; innerhalb der Funktion können lokale Variablen erzeugt werden, mit denen in einer tieferen Stufe gearbeitet wird. Eine Sequenz von Aktionen kann nur durch diese hierarchische Schachtelung ausgedrückt werden. Komplexe Unterfunktionen werden ausgelagert und separat spezifiziert.
Anhand von zwei Beispielen werden die Sprachelemente hier eingeführt und in einer Übersicht vervollständigt.
Beispiel: Sie möchten in einem Tuple ein Element suchen und als Ergebnis dessen Position erhalten; ist es mehrfach vorhanden, soll die erste Position geliefert werden -- eine Anwendung wäre z.B. das Durchsuchen eines Strings (Tuple von Zeichen) nach einem bestimmten Zeichen. Die Operation index löst das Problem:
TYPE index (tup,elem): DomainElement ![]() Nat0
Nat0
*
index =
*[0.5ex]
let eset = { i | i ![]() ind(tup)
ind(tup) ![]() tup(i)
= elem } in
tup(i)
= elem } in
*
if eset = { }
*[1ex]
then 0
*[1ex]
else min(eset)
*[1.5ex]
tup ist (wie man in der TYPE-Klausel sieht), das Tuple von Objekten des Typs Element, zu denen elem gehört. Die Funktion wird wie folgt durchlaufen:
Sprachelemente Nach diesem einführenden Beispiel folgen nun die wichtigsten Konstrukte der Sprache:
Das Konstruktlet Ausdruck inwertet den Ausdruck aus (damit wird häufig ein strukturiertes Objekt in seine Elemente zerlegt oder, im Gegenteil, aus Elementen konstruiert) und übergibt die dabei temporär erzeugten Objekte (im Beispiel eset) dem ,,Unterprogramm``, das aufinfolgt. In C kann man das Konstrukt sehr einfach mit folgenden Makros realisieren:
#define LET
* #define IN ;
*
Nun kann man jede Zuweisung mit,,LET...IN``klammern und darauf eine Anweisungsfolge mit der Auswertung der zugewiesenen Variablen folgen lassen. Strenggenommen ist das natürlich nur eine Hilfstechnik; C ist schließlich keine funktionale Sprache.
Die Auswahl kann durch Angabe einer Bedingung erfolgen, wie die temporären Objekte gewählt werden sollen. Dazu dient die Klausel let... be s.t.... in, das bedeutet ,,wähle xxx so aus, daß folgendes gilt:``.
Sehr oft werden Elemente aus zusammengesetzten Objekten entnommen. Das sieht im einzelnen so aus:
Sets: let ![]() in -- zufällige Auswahl eines
Elements
in -- zufällige Auswahl eines
Elements
Tuples: let
*
elem = hd Tup in -- Auswahl des ersten Elements
*
subtup = tl Tup in -- Auswahl des Tuples ohne ,,head``
*
elem = last Tup in -- Auswahl des letzten Elements
*
elem = Tup(i) in -- Auswahl des i.ten Elements
Maps: let
*
![]() dom Map in -- zufällige Auswahl eines Argumentwertes
dom Map in -- zufällige Auswahl eines Argumentwertes
*
![]() rng Map in -- zufällige Auswahl eines Map-Wertes
rng Map in -- zufällige Auswahl eines Map-Wertes
*
elem2 = Map(elem1) in -- Auswahl eines bestimmten Map-Wertes
Trees: let
*
![]() in -- Konstruktion eines Tree aus
Komponenten
in -- Konstruktion eines Tree aus
Komponenten
*
![]() in -- Zerlegung eines Tree in
Komponenten
in -- Zerlegung eines Tree in
Komponenten
*[1.5ex]
Es gibt die Möglichkeit, globale, statische Variablen zu definieren mit dcl; ihnen wird mit dem Zuweisungsoperator:=ein Wert zugewiesen, auf ihren Inhalt wird mit c (Contents-Operator) zugegriffen. Beispiel:
Erzeugung mit Initialisierung und Datentyp:
*
dcl var := init-value type Typname
*
Zuweisung:
*
var := new-value
*
Zugriff auf den Inhalt:
*
var := func(cvar)
*[1.5ex]
if Ausdruck then Klausel else Klausel entspricht der aus C bekannten if-Struktur.
Der switch-Struktur entspricht folgendes Konstrukt:
(cases Ausdruck0:
*
Ausdruck1 ![]() Klausel1,
Klausel1,
*
Ausdruck2 ![]() Klausel2, ...
Klausel2, ...
*
Ausdruck-n ![]() Klausel-n,
Klausel-n,
*
T ![]() Default-Klausel)
Default-Klausel)
*[1.5ex]
Für verschachtelteif...then...else if...gibt es die case-ähnliche Struktur
(Ausdruck1 ![]() Klausel1,
Klausel1,
*
Ausdruck2 ![]() Klausel2, ...
Klausel2, ...
*
Ausdruck-n ![]() Klausel-n,
Klausel-n,
*
T ![]() Default-Klausel)
Default-Klausel)
*[1.5ex]
Der for-Struktur in C ähneln die folgenden Konstrukte:
Die while-Struktur ist ebenfalls vorhanden:
while Ausdruck do (Klausel)
*[1.5ex]
Für Tuples, Sets und Maps stehen Konstruktoren zur Verfügung, die die Elemente durch ein Prädikat beschreiben (im obigen Beispiel wurde ein solcher für eset verwendet):
Sets: ¯{ a | Ausdruck(a) }
*
Tuples: < a | Ausdruck(a) >
*
Maps: [ a 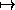 b | Ausdruck(a,b) ]
*
b | Ausdruck(a,b) ]
*
Die üblichen arithmetischen und logischen Verknüpfungen stehen zur Verfügung:
![]() sowie
sowie
![]()
Test, ob alle Elemente einer Menge eine bestimmte Eigenschaft haben:
![]()
*[1.5ex]
Test, ob mindestens ein Element einer Menge eine bestimmte Eigenschaft hat:
![]()
*[1.5ex]
Undefinierte Zustände (in denen irgendeine Fehlerbehandlung nötig wird), werden einfach mit undefined gekennzeichnet.
Beispiel: Das abschließende Beispiel verlangt eine kleine Einleitung:
Alle Operationen müssen in jeder Implementation definiert sein. Wenn eine neue Implementation geschaffen wird, geht also die Anpassung aller Operationen an deren spezifische Eigenschaften los...
Tuples können z.B. als Tabelle oder als verkettete Liste definiert werden. Die Operation tl (Tail), die ein Tuple ohne das erste Element liefert, muß im ersten Fall (Tabelle) eine neue, kleinere Tabelle erzeugen, das Ende der alten Tabelle umkopieren und diese dann löschen; im zweiten Fall (verkettete Liste) wird der Zeiger auf den Kopf des Tuple einfach auf den Nachfolger ,,verbogen`` und das erste Element gelöscht. Die Operation len ermittelt die Länge eines Tuple; bei der Tabelle wird einfach die Gesamtgröße durch die Elementgröße dividiert, die verkettete Liste jedoch muß einmal bis zum Ende durchlaufen werden. Man sieht: die Algorithmen sind für die beiden Implementationen völlig unterschiedlich -- beide Operationen müssen neu codiert werden.
Es gibt eine Möglichkeit, unnötige Neu-Codierungen (z.B. von len) zu umgehen: man kann len und auch einige andere Operationen nämlich mit einem Funktional so programmieren, daß sie nicht von der Implementation abhängen, sondern nur von anderen Operationen -- hat man diese codiert, ist len also ebenfalls vorhanden. Aber was ist ein Funktional ?
Funktional Ein Funktional ist eine Funktion, die als Ergebnis wieder eine Funktion liefert. Um möglichst vielseitig einsetzbar zu sein, hat es als Parameter meist andere Funktionen; durch die Auswahl dieser Funktionen ist das Funktional steuerbar.
Das folgende Funktional für Tuples ist in ähnlicher Form im VDM-System vorhanden. Es hat drei Parameterfunktionen; sind sie determiniert, erhält man eine Funktion, die ein Tuple-Objekt auf ein Resultat abbildet -- der Resultattyp ergibt sich allerdings erst durch die Festlegung der drei Parameterfunktionen, so daß beliebige Funktionen realisiert werden können!
TYPE fold (cvfct,nullfct,foldfct) (arg):
*
( (Element ![]() Result) (
Result) ( ![]() Result) (Result Result
Result) (Result Result
![]() Result) )
Result) )
*[0.5ex]
![]() (Domain
(Domain ![]() Result)
Result)
fold =
*
let userfct(tup) =
*
if tup ![]()
*
then nullfct
*
else let head = hd(tup), tup2 = tl(tup)
in
*
foldfct(cvfct(head), userfct(tup2))
*
in userfct(arg)
Realisierung von len:
*[0.5ex]
TYPE len (tup): Domain ![]() Nat0
Nat0
*[0.5ex]
len = fold(one, zero, plus) (tup)
*[1ex]
Parameterfunktionen:
*[0.5ex]
TYPE one (elem): Element ![]() Result
Result
*
one = 1
*[1ex]
TYPE zero (): ![]() Nat0
Nat0
*
zero = 0
*[1ex]
TYPE plus (e1,e2): Nat0Nat0 ![]() Nat0
Nat0
*
plus = e1 + e2
*[2ex]
Diese Spezifikation ist etwas schwerer zu entschlüsseln: Das Funktional fold liefert eine Funktion, die ein Objekt des Datentyps ,,Tuple`` auf ein Objekt des Datentyps ,,Result`` (der durch einen Implementationsparameter festgelegt wird) abbildet. Das Argument wird zunächst geprüft, ob es leer ist (die spitzen Klammern bezeichnen ein leeres Tuple); wenn ja, ist das Resultat das Ergebnis der konstanten Funktion nullfct. Wenn nicht, wird die Funktion foldfct auf die beiden Argumente vom Typ ,,Result`` angewendet -- das erste ergibt sich aus der Anwendung der Funktion cvfct auf das erste Element des Tuple, das zweite wird durch einen rekursiven Aufruf der mit fold generierten Funktion mit dem Rest des Tuple als Argument erzeugt.
Die drei Parameterfunktionen sind sehr einfach und entsprechen ihrem Namen:
zero liefert konstant den Wert 0 zurück, one liefert konstant den
Wert 1. plus addiert zwei Zahlen. len ergibt also für das leere
Tuple den Wert 0, bei einem Tuple mit einem Element wird plus mit den
Argumenten 1 und len( ![]() ) aufgerufen -- das Prinzip dürfte
erkennbar sein.
) aufgerufen -- das Prinzip dürfte
erkennbar sein.
Die verschiedenen existierenden Funktionale eignen sich für solche Vorgänge,
die mit den Worten ,,für alle`` zu beschreiben sind, denn diese lassen sich
durch rekursive Funktionen sehr gut abbilden. Ebenso können die Quantoren der
Mengentheorie ( ![]() und
und ![]() ) mit Funktionalen erzeugt werden. Ihr
Nachteil ist natürlich die schlechte Performance -- eine Funktion wie
len sollte nicht unbedingt mit fold realisiert werden, denn eine
iterative Lösung ist wesentlich schneller. len diente hier nur zur
Verdeutlichung des Konzepts.
) mit Funktionalen erzeugt werden. Ihr
Nachteil ist natürlich die schlechte Performance -- eine Funktion wie
len sollte nicht unbedingt mit fold realisiert werden, denn eine
iterative Lösung ist wesentlich schneller. len diente hier nur zur
Verdeutlichung des Konzepts.
Wohlgeformtheit Zur vollständigen Spezifikation einer Funktion gehört der Beweis der Erhaltung der Datentyp-Invariante -- aus wohlgeformten Objekten, die die Funktion als Argumente erhält, müssen wohlgeformte Objekte hervorgehen. Dies ist demzufolge eine implizite postcondition. Der Beweis kann formal oder argumentativ durchgeführt werden; meist ist er offensichtlich.
Wie erstellen Sie nun solch eine Modellspezifikation ?
Die Domain-Gleichungen sollten Sie in der angegebenen Notation schreiben; daraus entsteht ohne große Änderungen die Spezifikation in der Domain Specification Language , die das Thema von Kapitel 4 ist.
Die Datentyp-Invariante wird von der FH-Installation nicht berücksichtigt. Daher könnten Sie sie gleich als C-Funktion schreiben. Die angegebene Notation ist aber meist sehr einfach in eine C-Funktion umzusetzen und hat den Vorteil, auch für C-Laien, die aber mit mathematischen Notationen vertraut sind, verständlich zu sein.
Funktions-Spezifikation Sie haben die grundlegenden Elemente der funktionalen Sprache von VDM kennengelernt und auch zwei Beispiele gesehen; im Kapitel 5 werden Sie weitere Spezifikationen begegnen. Ein praktisches Problem sei nicht verschwiegen: die FH-Installation unterstützt diese Notation nicht, Sie müssen sie von Hand in C-Quelltext umsetzen. Das ist allerdings nicht übermäßig schwierig, und mit den Funktionalen stehen Ihnen Konstruktionsmittel für komplexe Formulierungen zur Verfügung. Die Syntaxdefinition können Sie direkt in C-Funktionsköpfe (sogenannte Prototypen) umsetzen.
Die Bindung an die formale Sprache ist also nicht sehr stark; Sie könnten auch prozedurale Spezifikationen erstellen. Doch die Sprachmittel von META-IV sind so mächtig, daß Sie damit kürzere Entwurfszeiten erreichen; die Umsetzung in C ist eine Sache der Übung und mit zunehmender Erfahrung wird die Entwicklungszeit insgesamt wesentlich kürzer sein.
Wenn Sie Ihr Wissen über META-IV noch vertiefen möchten, beachten Sie die Literaturhinweise.
Das VDM-System unter UNIX
Vienna Development Method
Vienna Development Method