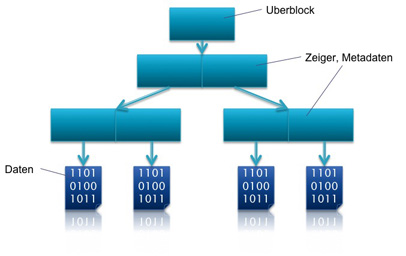
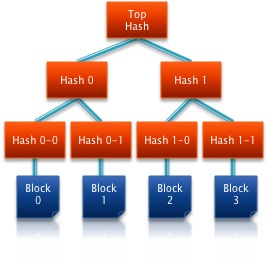
Ausgangszustand
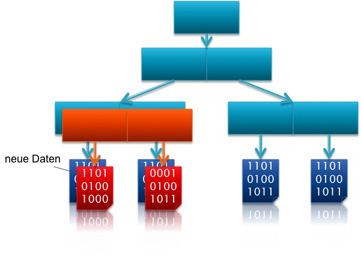
Daten werden neu erstellt
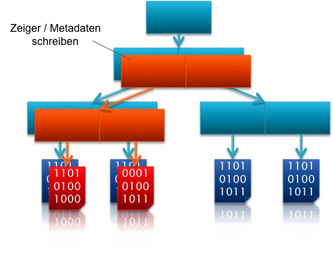
Zeiger werden geschrieben
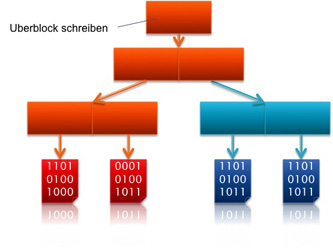
Uberblock wird aktualisiert
Bei herkömmlichen Dateisystemen kann "Silent Data Corruption" (unbemerkter Datenverlust) auftreten. Dies kann sehr viele verschiedene Gründe haben. Defekte an Datenträgern, Kabeln, Treibern usw. können dazu führen, dass unbemerkt Daten verloren gehen. Für Arbeitsspeicher gibt es zur Vermeidung des Problems spezielle ECC Memory Speicher, die anhand zusätzlich hinzugefügter Informationen Fehler in den Daten erkennen können.
Die Administration solcher Dateisysteme ist meistens sehr aufwendig, da Partitionen, Volumes und Berechtigungen verwaltet werden müssen. Zusätzlich können die Dateisysteme nur kompliziert vergrößert oder verkleinert werden.
In den Anfängen der Dateisysteme entsprach eine physikalische Festplatte immer genau einem Dateisystem. Da sich recht schnell zeigte, dass ein physikalischer Datenträger nicht ausreicht, wurden Volumes entwickelt, die die Möglichkeit boten mehrere Datenträger zu kombinieren und als ein Dateisystem auszugeben. Hierbei ist es jedoch problematisch, verschiedene Dateisysteme zu vergrößern bzw. zu verkleinern, da jedes Volume und somit auch jedes Dateisystem seine eigenen physikalischen Festplatten besitzt. So kann es vorkommen, dass ein Dateisystem viel zu viel Speicherplatz hat und andere wiederum zu wenig.
Bei konventionellen Dateisystemen werden die Daten immer blockweise geschrieben. Dies führt bei einem Stromausfall oder Systemabsturz jedoch zu inkonsistenten Daten. Das Problem wurde behoben indem die Systeme um Jornaling Funktionalitäten erweitert wurden. Dabei werden die Instruktionen zur Änderung im Dateisystem im Voraus in einem speziellen Speicherbereich geschrieben. Der Prozess kann dann im Falle eines Systemabbruchs erneut angestoßen werden. Die Verwaltung des Jornals ist jedoch relativ komplex und aufwändig. Beispiele für Jornaling-Dateisysteme sind u.a. NTFS, ext3/ext, ReiserFS, HFSJ.
Im Gegensatz dazu arbeitet ZFS ähnlich wie ein Datenbanksystem nach einem transaktionsbasierten Konzept mit dem Prinzip "ändere dies an folgenden Dateien oder mache nichts". Da alle kritischen Schreibvorgänge atomar sind, ist das Filesystem immer konsistent. Sollte es zu einem schwerwiegenden Fehler beim Schreiben kommen, bleibt der letzte gültige Stand aktuell. Sobald das Problem behoben wurde, wird erneut versucht die Operation durchzuführen.
Das Transaktionsbasierte ZFS Modell arbeitet nach der Copy On Write Methode. Hierbei handelt es sich um eine Optimierung, die das unnötige Kopieren von Dateien vermeiden soll. Wenn mehrere Prozesse einen Block lesen, ist es möglich das alle auf diesen per Pointer zugreifen. Erst wenn ein Prozess den Block ändern möchte, wird eine Kopie erstellt und geändert.
Änderungen an den Daten führen somit nicht zu einem Überschreiben der bestehenden Daten, sondern zu einer Neuerstellung des Blockes. Snapshots können so auf sehr einfache Weise in konstanter Zeit erstellt werden.
Aufgrund von Copy On Write Semantik, müssen die Schreibköpfe nicht mehr die alten zu überschreibenden Daten auf der Festplatte finden, sondern können die neuen Daten einfach auf einen freien Teil der Festplatte schreiben. Hierbei versucht ZFS die Daten sequentiell hintereinander in einen freien Bereich zu schreiben. Herkömmliche Dateisysteme müssen jeden einzelnen Block erst anfahren und dann jeweils überschreiben. Durch die beiden Optimierungen können Daten bei ZFS sehr schnell geschrieben werden.
Die folgende Grafik verdeutlicht die Copy On Write Methode:
Ausgangszustand |
Daten werden neu erstellt |
Zeiger werden geschrieben |
Uberblock wird aktualisiert |
Die Uberblöcke werden eine bestimmte Zeit lang nicht gelöscht, so dass auf diese bei Problemen zurück gegriffen werden kann. Der aktuelle Uberblock kann an seiner Seriennummer erkannt werden.
Beim Schreiben der Dateien wird nach folgenden drei Kriterien die zu benutzende physikalische Platte gewählt:
Kapazität: Auf der Platte muss entsprechend viel Speicherplatz frei sein
Perfomance: Hierbei spielen vor allem die Brandbreite und die Latenz eine große Rolle, mit der auf die physische Platte geschrieben werden kann
Health: Datenträger mit Problemen, wie z.B. Mirror, die momentan einen Plattenausfall haben, werden nach Möglichkeit nicht genutzt.
ZFS ist ein 128 Bit Dateisystem. Nach dem Mooreschen Gesetz werden 65 Bit Dateisysteme in den nächsten 10 bis 15 Jahren benötigt.
Von Jeff Bonwick, stammt das Zitat: "Populating 128-bit file systems would exceed the quantum limits of earth-based storage. You couldn't fill a 128-bit storage pool without boiling the oceans. ". Er möchte damit sagen, dass das Füllen eines kompletten 128 Bit Dateisystems mehr Energie verbrauchen würde, als das komplette verdampfen sämtlicher Ozeane benötigen würde.
Die mögliche Größe des Dateisystems soll bei ZFS jedoch nicht im Vordergrund stehen. Vielmehr sind es viele andere Eigenschaften, die Vorteile gegenüber herkömmlichen Dateisystemen bieten.
Neben der absoluten Größe gibt es quasi keine Beschränkung für die Anzahl der Dateien bzw. der Verzeichnisse.
Alle physikalischen Datenträger werden zu einem Storage Pool zusammenfasst. Sämtliche ZFS Dateisysteme greifen, statt jeweils auf ein eigenes Volume, auf den gemeinsamen Storage Pool zu. Die ZFS Dateisysteme teilen sich den zur Verfügung gestellten Speicherplatz. Zusätzlich besitzen sämtliche Dateisysteme die volle Bandbreite des Storage Pools.
Auf diese Weise können die physikalischen Datenträger optimal ausgenutzt werden und es kann nicht mehr zu Problemen wegen schlecht geplanter Partitionierung der Festplatten kommen. Über Beschränkungen und Reservierungen von Speicherplatz im ZFS Pool kann bei Bedarf weiterhin sehr genau gesteuert werden, wie viele Daten jeweils abgelegt werden dürfen.
Ein Vorteil der Copy On Write Methode ist die Möglichkeit der Erstellung von Snapshots in konstanter Zeit. Bei der Erstellung merkt sich das Filesystem von welchen Blöcken der Snapshot erstellt wurde. Das aktive Dateisystem und der Snapshot teilen sich die selben Blöcke. Erst wenn Daten verändert werden, werden diese neu erstellt.
Da bei der Erstellung von Snapshots und dem nachfolgenden Kopieren bei Änderung das Löschen der alten Blöcke entfällt, ist die Erstellung von Snapshots sogar schneller als eine normale Transaktion.
Zusätzlich zu den normalen schreibgeschützten Snapshots gibt es die Möglichkeit Clones zu erstellen. Hierbei handelt es sich um beschreibbare Snapshots. Mehrere Dateisysteme greifen hierbei auf die selben Blöcke zu, bis eine Änderung stattfindet.
Neben der Möglichkeit die Snapshots bzw. Clones im ZFS Pool zu erstellen, kann man diese auch an andere Systeme oder externe Datenträger senden. Neben einem vollständigen Backup können auch auf Snapshots basierende inkrementelle Backups durchgeführt werden, die dann nur die Änderungen übertragen.
Im Gegensatz zu herkömmlichen Dateisystemen ist in ZFS die Größe der Blöcke variabel, da es keine optimale Blockgröße gibt. Kleine Blöcke eignen sich vor allem für die Speicherung von vielen kleinen Daten, wohingegen große Blöcke weniger zusätzliche Meta Informationen benötigen und eine höhere Bandbreite ermöglichen. Der Administrator kann default Werte für jedes Dateisystem festlegen.
Es gibt die Option die Kompression der Daten für ein Dateisystem zu aktivieren. Dabei kann zwischen verschiedenen Algorithmen gewählt werden. Zur Zeit stehen nur lzjb oder gzip zur Auswahl. In kommenden Versionen soll die Anzahl der Algorithmen noch erweitert werden. Die Kompression nutzt dabei die variablen Blockgrößen aus. Aufgrund der kleineren Blöcke wird weniger Platz im Pool benötigt und zusätzlich erhöht sich der Datendurchsatz. Allerdings wird für die Ver-/Entschlüsselung Bearbeitungszeit benötigt.
|
Für jeden Block im ZFS Dateisystem wird eine Checksumme erzeugt. Die Checksumme wird dabei nach dem Verfahren der Hash Trees (auch Merkle Trees bezeichnet) erzeugt. Das Verfahren wurde 1979 von Ralph Merkle für Lamport Signaturen entwickelt, um die nur einmal nutzbaren Signaturen auch auf mehrere Dokumente anwenden zu können. Heute wird dieses Verfahren neben ZFS hauptsächlich im P2P Bereich eingesetzt, da es die Integrität der Daten schon während des Herunterladens prüfen kann. Für jeden Block wird eine Checksumme erstellt und in einem darüberliegenden Block gespeichert. Daraufhin wird für diese und eine benachbarte Checksumme erneut ein Hash berechnet usw. Ein binärer Baum mit Daten an den Blättern und einem Root Element wird mit dem Verfahren erzeugt. Durch die Nutzung des Hash Tree Verfahrens können sehr viel mehr Fehler gefunden werden als mit den herkömmlichen Checksummenverfahren, die nur defekte Blöcke erkennen können. So können z.B. auch versehentlich überschriebene Blöcke erkannt werden, da die weiter oben liegenden Checksummen nicht mehr stimmen würden. Des Weiteren können auch "Phantom writes", DMA Parity Fehler und Fehler in den Treibern auf erkannt werden. Das Verfahren zur Erzeugung der Checksummen kann variiert werden. Standardmäßig wird das recht einfache und schnelle fletcher2 Verfahren verwendet. Es kann jedoch bei Bedarf auch problemlos auf den sicheren SHA256 oder einen anderen 256 Bit Algorithmus gewechselt werden. |
Die Erweiterung eines Pools gestaltet sich bei ZFS sehr einfach. Sobald eine neue Platte, ein Mirror oder RAID Verbund hinzugefügt wurde, werden sämtliche Daten auf allen nun vorhandenen Platten abgelegt. Die alten Daten bleiben jedoch auf den bisherigen Datenträgern. Durch die Copy on write Methode verteilen sich die Daten mit der Zeit über alle Platten, da Änderungen an den Daten stets zu einer Neuallokierung der Daten führen.
Neben der Administration auf der Kommandozeile bietet ZFS auch die Möglichkeit der Wartung über eine Web GUI. Diese soll die Storage Pools visualisieren und die Administration vereinfachen. Zur Zeit ist die GUI noch kein fester Bestandteil von Solaris bzw. OpenSolaris und muss nachinstalliert werden.
ZFS bietet verschiedene Verfahren, um die Ausfallsicherheit zu erhöhen. Es gibt Pendants zu RAID 1, 5 und 6. Wie auch bei den herkömmlichen Systemen sollte darauf geachtet werden, dass alle Datenträger gleich groß sind. Bei unterschiedlichen Größen, kann man die Erstellung per Parameter erzwingen. DDaraufhin werden alle größeren Datenträger nur mit der Kapazität des kleinsten eingesetzten Datenträgers genutzt. Zusätzlich kann ZFS die Ausfallsicherheit auch bei nur einem einzelnen physikalischen Datenträger zu erhöhen.
Die im Folgenden erwähnten Verfahren lassen sich alle untereinander kombinieren, so dass beispielsweise ein RAID Verbund aus Mirror Verbünden besteht.
Die einfachste Methode Sicherheit bei Ausfall eines Datenträgers zu erreichen, ist die Spiegelung, die auch als RAID 1 bei herkömmlichen Dateisystemen bekannt ist. Ein solcher Datenträger lässt sich mit nur einem Befehl realisieren.
Durch die Art der Speicherung kann zwar die Ausfallsicherheit erhöht werden, jedoch ist es nicht ohne weiteres möglich, die Kapazität zu erhöhen. Dies gelingt durch den Einsatz von RAID-Z.
RAID-Z gibt es in zwei verschiedenen Ausführungen. RAID-Z1 entspricht in den Grundzügen dem herkömmlichen RAID 5. RAID-Z2 entspricht RAID 6.
Im ersten Fall wird die Paritätsinformation so verteilt, dass maximal ein Datenträger ausfallen darf. Im zweiten Fall dürfen zwei Datenträger ausfallen ohne dass es zu Datenverlust kommt.
Ein solcher RAID-Z1 Verbund lässt sich sehr einfach mit nur einem Befehl erstellen.
Auf den ersten Blick könnte man meinen, dass es sich bei den RAID-Z Systemen einfach um eine auf ZFS angepasste Umbenennung von RAID 5 bzw. RAID 6 handelt. Jedoch hat RAID-Z gegenüber den herkömmlichen Systemen einen entscheidenden Vorteil, da hier durch die ZFS Architektur bedingt keine write holes entstehen können.
Write holes treten auf, wenn beim Schreiben von Daten auf einem RAID 5 oder RAID 6 ein schwerer Systemfehler auftritt. In diesem Fall kann es vorkommen, dass zwar die Daten schon geschrieben sind, jedoch die Paritätsinformationen noch fehlen. Sollte der Fehler unentdeckt bleiben und eine der Platten im Verbund ausfallen, werden nun aufgrund der falschen Paritätsinformationen, fehlerhafte Daten wiederhergestellt. Es kommt somit zu einem partiellen Datenverlust.
Um dem Problem bei RAID 5, bzw RAID 6 entgegenzuwirken, wird ein spezieller batteriegepufferter NVRAM eingesetzt.
Bei ZFS sind teuere Hardwareanschaffungen jedoch nicht nötig, da sämtliche Daten als full stripe Schreibvorgang ablegt werden. Dabei werden die Stripes samt Paritätsinformation immer komplett neu geschrieben und mit einem atomaren Vorgang eingehängt.
Ein weiterer Vorteil ist das Entfallen von "read-modify-write" Abläufen. Bei herkömmlichen RAID Systemen werden diese für Parity Updates benötigt. Hierbei werden zuerst die alten Daten und die dazu gehörige Paritätsinformation gelesen und dann mit den Änderungen kombiniert. Anschließend wird die der neue Stripe geschrieben. Aufgrund der erwähnten "full stripe" Schreibweise, kann der Vorgang bei ZFS entfallen. Dadurch sind Schreibzugriffe schneller als auf einem vergleichbaren RAID 5 bzw. 6 System.
Neben dem Spiegeln der Platten und dem RAID Verbund bietet ZFS noch eine weitere Möglichkeit die Datensicherheit zu erhöhen.
Ditto Blöcke bieten die Option, dass jeder logische Block bis zu 3 physische Repräsentationen hat. Diese werden auf verschiedene Datenträger gelegt. Sollte wie zum Beispiel bei Notebooks nur eine Festplatte vorhanden sein, werden die Datenblöcke an verschiedenen Stellen auf dem Datenträger abgelegt. Da die Aktivierung jedoch Bandbreite kostet, lässt sich die Funktion auch nur für spezielle Verzeichnisse aktivieren. Hierfür bieten sich beispielsweise die Userverzeichnisse an.
Laut den ZFS Entwicklern soll die Ditto Block Methode die Daten noch bis zu einem Ausfall von einem Achtel der Platte sichern. Sollten die Daten über mehrere Datenträger verteilt sein, kann auch eine Platte komplett ausfallen.
Die Metadaten und der Uberblock werden automatisch mehrfach als Dittoblöcke gesichert, um bei Hardwaredefekten einen zusätzlichen Schutz zu bieten.
Das Kopieren von Daten von einem Teil des Mirrors auf den Anderen oder das Befüllen einer Platte in einem RAID Verbund nennt sich resilvering. Dies wird angewendet, wenn ein Teil eines redundanten Systems ausgefallen ist und ersetzt werden muss. Bei RAID 5 Systemen wird in die gesammte Platte kopiert. Dabei spielt es keine Rolle, ob es sich um tatsächliche Daten oder nur um leeren Speicherplatz handelt. Aus diesem Grund dauert der Vorgang, auch wenn die Datenträger fast leer sind, sehr lange.
Erst nach kompletter Fertigstellung kann sichergestellt werden, dass die Kopie korrekt abgelaufen ist. Vorher ist eine Überprüfung nicht möglich, da das Root Verzeichnis evtl. als aller letztes kopiert wird und somit erst am Ende des Resilverings verfügbar ist. Zusätzlich existieren keine Checksummen, die die Validität der Daten prüfen könnten.
ZFS verfolgt beim resilvering einer Platte ein Top-Down Prinzip. Dies bedeutet, dass ausgehend vom root Verzeichnis die Daten geschrieben werden. Die wichtigsten Blöcke werden zu erst geschrieben und es wird keine Zeit für das Kopieren von unnötigen Blöcken verschwendet. Spiegel von leeren Platten können somit in konstanter Zeit erstellt werden.
Zusätzlich bietet ZFS die Möglichkeit bei einem vorübergehenden Ausfall einer Mirror Platte sämtliche Transaktionen auf einer noch funktionierenden aufzuzeichnen. Diese werden bei wieder korrekt funktionierender Hardware nachgeholt. Ein Ausfall von 10 Sekunden kann so problemlos in 10 Sekunden repariert werden. Der Vorgang ist bei herkömmlichen RAID Systemen sehr viel aufwendiger, da es diese Art der Zwischenspeicherung für den kurzfristigen Ausfall nicht gibt.
Bei herkömmlichen gespiegelten Dateisystemen kann nicht erkannt werden, ob ein Block korrekt gelesen wurde. Wird solch ein fehlerhafter Block gelesen, wird er einfach vom Dateisystem an die Anwendung weiter gereicht.
Da ZFS anhand seiner Checksumme erkennen kann, ob es einen defekten Block gelesen hat, kann das System im Fehlerfall die Daten vom Mirror lesen. Sollten diese Informationen korrekt sein ersetzt ZFS automatisch den defekten Block auf der fehlerhaften Platte und reicht den reparierten an die Anwendung weiter.
Um die Datensicherheit weiter zu erhöhen ist es möglich "Hot Spare" Datenträger in solche Verbunde einzubinden. Diese werden im Normalfall nicht genutzt und automatisch aktiviert, wenn eine der Festplatten im Verbund ausfallen sollte.
Durch das Disk scrubbing werden Fehler auf den Datenträgern gesucht, solange sie noch korrigierbar sind. Dabei werden sämtliche aktiven Blöcke des Dateisystems gegen die 256 Bit Checkumme geprüft. Dies betrifft alle Mirrors, RAID-Z Platten und auch Ditto Blöcke. Wird ein Fehler gefunden, wird er sofern es möglich ist behoben. Um das Scrubben auch im laufenden Betrieb störungsfrei durchführen zu können, wird der Prozess mit einer geringen I/O Priorität ausgeführt.
In kommenden Versionen von ZFS soll es zudem eine Einstellung geben mit der automatische Intervalle zum Ausführen des Diskscrubbings festgelegt werden.
Wie auch viele andere Administrationsaufgaben, ist auch der Umzug auf ein neues System bzw. auf eine neue Architektur mit ZFS relativ einfach. Konfigurationseinstellungen müssen nicht wie bei herkömmlichen Systemen extra gespeichert und verwaltet werden. Sämtliche Freigaben, Mountpunkte usw. werden bei einem Export automatisch mitgesichert und können mit einem einzelnen Befehl wieder eingebunden werden.
Für sehr große Pools ist es schwierig sämtliche Administrationsaufgaben vom root Nutzer durchführen zu lassen. ZFS bietet die Möglichkeit Rechte an bestimmte User oder Gruppen weiterzureichen. Es können einzelne Rechte und Gruppen von Rechten (permission sets) verteilt werden. Diese bleiben bei einer Migration der Daten erhalten.
Einige der häufigsten Berechtigungen sind:
clone: Umwandlung eines Snapshots in einen beschreibbaren Clone.
create: Der User kann weitere Kind Dateisysteme erstellen.
destroy: Löschen von bestimmten Dateisystemen.
mount: Mounten und Unmounten von Dateisystemen.
rollback: Zurückspielen eines Snapshots.
share: Der Benutzer kann das Sharing eines Dateisystems beeinflussen.
snapshot: Erstellen von Snapshots.
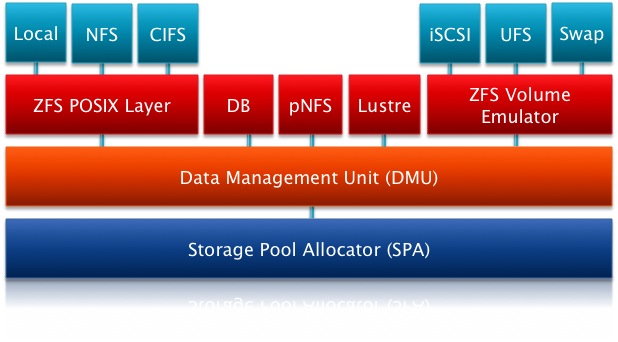
Sämtliche ZFS Funktionalitäten sind in Schichten angeordnet. Der Storage Pool Allocator (SPA) sorgt für die hardwarenahe Kommunikation mit den Devices. Die Devices können aus ganzen Festplatten, Partitionen oder auch nur einzelnen Dateien bestehen. Es wird jedoch nicht empfohlen Dateien als Grundlage für ein ZFS Filesystem zu nutzen. Ebenfalls ist auf dieser Ebene der Datenfluss inklusive der Checksummenüberprüfung und Kompression implementiert.
Die darüber liegende Ebene ist die Data Management Unit. Sie wandelt den hardwarenahen Adressraum in eine objektbasierte Speicherinfrastruktur um. Zudem werden hier einige Optimierungen durchgeführt, um auch auf große Datenmengen zügig zugreifen zu können.
Die nächst höhere Schicht ist normalerweise der ZFS POSIX Layer. Er sorgt für eine POSIX-konforme Dateisemantik, sowie für die Behandlung von ACLs nach dem NFSv4 Standard. Es gibt jedoch auch die Möglichkeit, andere Dateisysteme auf Basis von ZFS mit dem ZFS Volume Emulator zu nutzen. Diese Volumes haben eine feste Größe und können wie ein normales Volume behandelt werden. Für einige weitere Dateisysteme gibt es direkte Anbindungen an die Data Management Unit. So können beispielsweise Datenbanken direkt zugreifen und die Vorteile von ZFS nutzen.
Wie jedes andere Dateisystem auch, benötigt ZFS eine Methode zur Verwaltung von freiem und belegtem Speicherplatz. Wäre es nicht möglich würde aufgrund des Copy On Write Verfahrens der Pool-Speicher sehr schnell voll sein, da jede einzelne Änderung zu einer Neuallokierung führt.
ZFS teilt jedes virtuelle Device (vdef) in mehrere hundert Regionen ein. Diese werden Metaslab genannt. Jede Metaslab hat eine eigene Space Map, in der sämtliche Allokierungen und Freigaben von Speicher in zeitlicher Reihenfolge (wie in einer Log Datei) gespeichert sind. Dies gewährleistet auch bei nicht sequentiellem Löschen eine sehr schnelle Bearbeitung.
Sollte ZFS freien Speicherplatz zum Schreiben benötigen, wird die spacemap einer Metaslap gelesen. Die Auswahl der Metaslab geschieht nach verschiedenen Kriterien. Ein Hauptkriterium ist die größe des freien Speicherplatzes. Zusätzlich beachtet ZFS die Position der Blöcke auf der Festplatte, da weiter außen liegenden Blöcke eine höhere Bandbreite haben. Die gewählte Spacemap wird dann in einen binären Suchbaum (AVL Baum) umgewandelt und im Speicher abgelegt. Anhand dieses Suchbaumes kann nun sehr einfach aneinander hängender Speicher in dieser Region der Festplatte gefunden werden. Zusätzlich wird die existierende Spacemap für spätere Zugriffe optimiert.
Die Spacemaps müssen bei Erstellung eines Pools nicht initialisiert werden, da eine leere Spacemap einem Bereich ohne Allokierungen und Freigaben entspricht. Da wie in einer Logdatei immer nur am Ende der Map angehängt wird, lassen sich Änderungen sehr schnell durchführen.
Sollte eine Spacemap komplett gefüllt werden, wird dies durch einen einzelnen Eintrag festgehalten. Hierdurch schrumpft die Größe der Spacemap sehr stark, so dass mehr Speicher für Nutzdaten zur Verfügung steht.
ZFS beinhaltet das Tool "ztest". Es Ermöglicht verschieden Testfälle auf dem eigenen System durchzuführen. Dabei werden folgende Fälle parallel gestartet:
- Lesen, Schreiben , Erstellen und Löschen von Dateien
- Erstellung und Löschung von Dateisystemen und storage pools
- Wechsel der Checksummen Algorithmen
- Wechsel der Kompressionseinstellungen
- Hinzufügen und Löschen von Devices
- Testen der Selbstheilungsfähigkeiten
Diese Testfälle werden ständig erweitert. Bisher ist es laut den Entwicklern noch nie zum Verlust eines einzigen Blocks gekommen.
Neben den ganzen Vorteilen die ZFS zu bieten hat, gibt es natürlich auch einige Nachteile.
Ein Nachteil ist die momentan noch fehlende Möglichkeit einen Datenträger zu entfernen. Zwar ist ein Austausch problemlos machbar, jedoch kann der Pool nicht verkleinert werden. Dies soll jedoch in kommenden Versionen implementirt werden. Im produktiven Einsatz ist eine Verkleinerung des vorhandenen storage pool eher unüblich.
Des Weiteren bezeichnete Andrew Morton ZFS als "rampant layering violation". Hiermit kritisiert der populäre Linux Kernel Entwickler das Zusammenfassen der bisher selbstständigen Schichten (Dateisystem, Volume Manager und RAID Controller). Die ZFS Entwickler hingegen behaupten, dass die bewährten Strukturen aus einer Zeit stammen, in der es noch andere Anforderungen an Speicherplatz gab. Durch den Wegfall können Prozesse besser optimiert werden.