Für die Entwicklung eines Parsers ist zunächst die Definition
einer Grammatik notwendig, damit der Parser den einzulesenden Text erkennen
und strukturieren kann. Eine kontextfreie Grammatik ist ein Quadrupel
![]() wobei gilt:
wobei gilt:
![]()
![]()
![]()
![]()
![]()
![]()
Hier steht ![]() für
für ![]() .
.
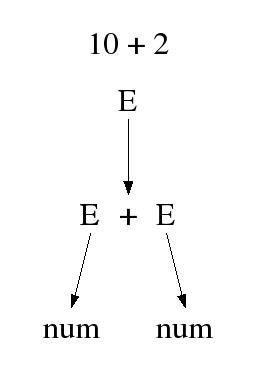
Als Beispiel wird folgender Ausdruck betrachtet 10+2 .
Der Parser wird diesen Ausdruck von links nach rechts
lesen, wobei ausgehend vom Startsymbol, E sich wie folgt ableiten
lässt: ![]() . Anhand dieser Ableitungsfolge lässt sich der zugehörige
Syntaxbaum erstellen und wie folgt darstellen.
. Anhand dieser Ableitungsfolge lässt sich der zugehörige
Syntaxbaum erstellen und wie folgt darstellen.
Der dargestellte Syntaxbaum ist zunächst ausgehend von der Wurzel von oben nach unten aufgebaut. Dieses Prinzip nennt sich Topdown Analyse. Desweiteren lässt sich feststellen, dass sich an den Knoten die nichtterminalen Symbole und an den Blättern die terminalen Symbole befinden.
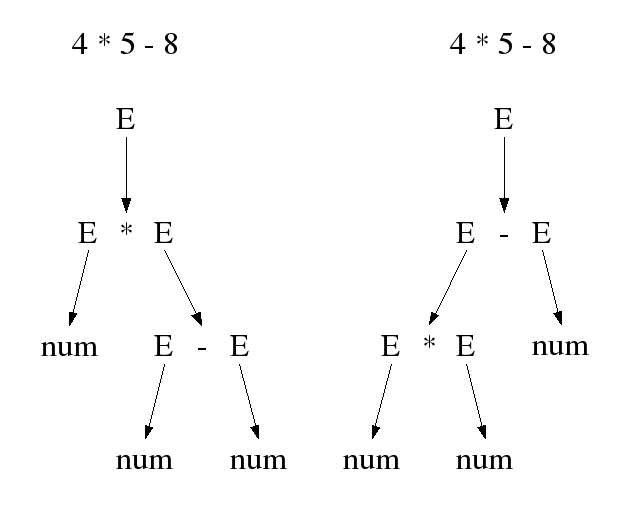
Als weiteres Beispiel betrachtet man das Terminalwort 4*5-8 und erstellt ebenfalls die Ableitungsfolge und den dazugehörigen Syntaxbaum.
![]()
![]()
Hierbei lässt sich feststellen, dass sich für den gleichen Ausdruck mehrere Syntaxbäume erstellen lassen. Diese Syntaxbäume entstehen durch Anwendung unterschiedlicher Produktionsregeln. Das Problem hierbei liegt in der mehrdeutigen Semantik. Es darf nicht sein, dass ein Ausdruck unterschiedliche Bedeutung haben kann. Das Ergebnis muss durch die Grammatik eindeutig definiert sein. Mehrdeutigkeiten sind bei der Entwicklung einer Grammatik zu vermeiden. Ein möglicher Lösungsansatz ist zum Beispiel die Festlegung von Prioritäten, Assoziativitäten oder eine natürlich strukturierte Grammatik zum Beispiel durch Klammerung.
Betrachtet man die gegebene Grammatik ![]() .
.
![]()
![]()
![]()
![]()
![]()
![]() steht für
steht für ![]() . Durch das zusätzliche Symbol
. Durch das zusätzliche Symbol ![]() ist eine links Assoziativität definiert und eine Mehrdeutigkeit
ausgeschlossen.
ist eine links Assoziativität definiert und eine Mehrdeutigkeit
ausgeschlossen.
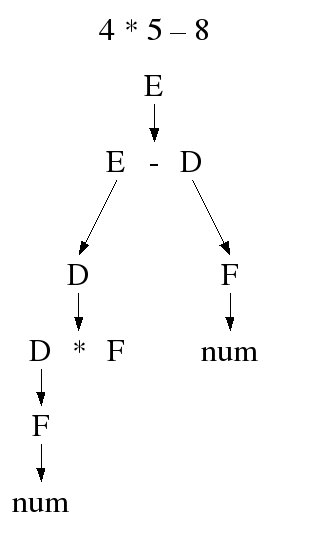
Wird für den gleichen Ausdruck 4*5-8 der dazugehörige Syntaxbaum betrachtet, so ist zu erkennen, dass vor der Berechnung des Ausdrucks E - D der Kindknoten D * F berechnet werden muss. Desweiteren ist festzuhalten, dass für den Ausdruck nur noch ein Syntaxbaum erstellt werden kann.
Durch die Regel ![]() ist die links Assoziativität festgelegt worden. Tauscht man zunächst
den Ausdruck durch folgende Regel aus
ist die links Assoziativität festgelegt worden. Tauscht man zunächst
den Ausdruck durch folgende Regel aus ![]() so lässt sich eine rechts Assoziativität implementieren.
so lässt sich eine rechts Assoziativität implementieren.
Bei der gegebenen Grammatik ![]() aus dem Abschnitt
aus dem Abschnitt ![[*]](crossref.png) kann die Produktion der Form
kann die Produktion der Form ![]() zu Problemen führen. Gemeint ist hierbei, dass das Nichtterminalsymbol
zu Problemen führen. Gemeint ist hierbei, dass das Nichtterminalsymbol
![]() auf der rechten Seite der Produktion wieder ganz links auftritt (Rekursion).
Betrachtet man einen Ausschnitt der bekannten Regeln
auf der rechten Seite der Produktion wieder ganz links auftritt (Rekursion).
Betrachtet man einen Ausschnitt der bekannten Regeln ![]() , und überlegt sich eine mögliche Implementierung, so könnte
diese wie folgt aussehen:
, und überlegt sich eine mögliche Implementierung, so könnte
diese wie folgt aussehen:
void E() {
E();
Symbol(); // Symbol + ueberlesen!
T();
}
Bei der Betrachtung der gegebenen Implementierung wird
sich E() rekursiv aufrufen welches unwiederbringlich zu einem
Stacküberlauf führen wird. Dieser Implementierungsfehler lässt
sich jedoch durch folgende Änderung der Grammatik beheben ![]() . Durch diese Änderung wurde aus einer Linksrekursion eine Rechtsrekursion.
. Durch diese Änderung wurde aus einer Linksrekursion eine Rechtsrekursion.
{kind=link}
{kind=link}
{kind=link}