Wenn Teile des Dokuments neu organisiert werden sollen oder ein neues Dokument erstellt werden soll, dann hilft eine lineare Struktur nicht weiter !!!
Durch die Baumstruktur ist es einfach ein Dokument auf Gültigkeit und Aufbau zu überprüfen. Auch ein eventuell referenziertes DTD kann durch eine Baumstruktur abgebildet werden, -> aufstellen von Regeln. DTD-Baum und Dokumentbaum können dann eine weiterverarbeitende Anwendung gesendet werden.
Bei der Überführung des Dokuments in einen XML-Baum können Fehler detektiert werden, dies führt dazu, dass auf eine Weiterverarbeitung verzichtet werden kann. Fehler können vor der Verarbeitung erkannt und gemeldet werden.
XML basiert auf der Standard Generalized Markup Language (SGML). SGML bietet als Metasprache die Möglichkeit zur Festlegung von Auszeichnungssprachen. XML schränkt die Möglichkeiten der sehr komplexen und mächtigen Metasprache SGML ein. Die abstrakte Definition des SGML Dokument Modells wird als GROVE bezeichnet.
GROVE = Graph Representation Of property ValueEs.
Ein GROVE ist ein gerichtet Graph aus Knoten.
Jeder Knoten wird als Objekt eines speziellen Typs betrachtet, eine Anordung von Informationen, die einem vordefinierten Template entsprechen.
Jeder dieser Elemente besitzt eine Liste von Eigenschaften, welche sich aus einem Namen und einem Wert zusammensetzen. Man bezeichnet diese Eigenschaften als Attribute, die sich aus einem Attributnamen und einem Attributwert zusammensetzen. Besitzt ein Element keine weiteren Eigenschaften, dann ist die Liste leer.
Ein Knoten (Element) wird durch einen Typ (spezifiziert in einem DTD) und einem Namen beschrieben. Auf diese Weise kann er referenziert und identifiziert werden.
- 1. subnodes/child nodes
- 2. irefnode; interne Referenzen innerhalb eines Dokuments
- 3. urefnode; unrestricted externe Referenzen, die auf Knoten innerhalb eines weiteren Dokuments verweisen
3.2. XML-Datenstruktur
Bäume sind verallgemeinerte Listenstrukturen, welche eine geeignet Möglichkeit zur internen Repräsentation grosser Datenmengen darstellen.Ein XML-Baum besitzt mindestens ein Wurzel-Element (Root). Das Wurzel-Element ist das einzige Element, welches keinen Vorgänger hat.
Dieses Wurzel-Element hat eine endliche, durch ein DTD definierte Anzahl von Nachfolgern. Da die Struktur und Anordnung der Elemente des Baumes durch ein DTD definiert ist kann man auch von einem geordneten Baum sprechen, dies ist wichtig um eine Strukturgültigkeit zu gewährleisten und gegebenenfalls zu prüfen.
Bei den XML-Bäumen handelt es sich um Bäume ohne feste Stelligkeit (ohne Ordnung), die Anzahl der Söhne eines Knotens ist nicht festgelegt und variiert von Knoten zu Knoten. Die Söhne eines Knotens sind eine Folge von beliebig vielen Bäumen.
Die Blätter eines XML-Baumes können selbst keine Elemente mehr sein, das Ende eines Pfades endet folglich in reinem Text, Kommentar oder Processing Instructions.
Eine minimale Anzahl oder maximale Anzahl von Nachfolgern eines Elements kann nicht spezifiziert werden.
XML-Bäume sind weder vollständig noch balanciert.
Operationen auf XML-Bäume sind:
- Suchen
- Einfügen
- Manipulieren
- Löschen
- Sortieren
3.3. Der XML Prozessor
Programme, welche XML Dokumente einlesen wollen brauchen ein Verarbeitungsmodul, auch XML Processor genannt. Der XML Processor ist dafür verantwortlich, dass der Inhalt des XML-Dokuments in einer geeigneten Datenstruktur einer Verarbeitenden Anwendung zur Verfügung gestellt wird. Des weiteren werden Probleme, ungültige Formate und ungültige Strukturen vom Processor detektiert, so dass der verarbeitenden Anwendung immer nur dann der Inhalt des Dokuments zur Verfügung gestellt wird, wenn der auch verarbeitet werden kann.Ein XML-Processor besteht aus:
- entity manager;
er ist dafür verantwortlich Fragmente eines Dokuments zu lokalisieren, welche in Entity Deklarationen oder anderen Dateien enthalten/beschrieben sind. Diese Referenzen müssen gehandhabt und ersetzt werden. - parser (Integritätsprüfer);
prüft, ob der Inhalt der Daten den vordefinierten XML-Strukturregeln genügt.
Überführt das XML-Dokument in eine Baumstruktur.
Mit Hilfe der Baumstruktur wird das gesamte Dokument einer verarbeitenden Anwendung zur Verfügung gestellt. Software, welche das gesamte Dokument in Hauptspeicher hält, muss die Daten so organisieren, das ein einfacher und schneller Zugriff für Suchfunktionen und Manipulationsfunkionen möglich wird. Wenn das gesamte Dokument für eine Verarbeitung im Zugriff ist, dann ist es nicht erforderlich 'mehrfach Parsefunktionen' (multi-pass) zur Verfügung zu stellen.
3.4. Anforderung an die Verarbeitung der Baumstruktur
Da es sich bei einem Baum um eine rekursive Datenstruktur handelt sollten Transformationen auf XML Dokumenten rekursiv ausgedrückt werden.Transformation, die auf jeder Ebene des Baumes aus aufgerufen werden können, und von dieser Ebene aus Unterbäume verarbeiten. Eine wichtige Gruppe solcher Ausdrücke sind in erster Linie die, welche einen Teilbaum von einem beliebigen Knoten aus auslesen (selecting), bearbeiten (editing) oder beliebige Werte herausfiltern (filtering). Um Filter auf jeden beliebigen Knoten aufsetzen zu lassen und ihn von da aus startend rekursiv auf den Teilbaum anzuwenden, werden Funktionen (Kombinatoren) benötigt, die diesen Filter nehmen und ihn rekursiv auf den Teilbaum anwenden. Es müssen folglich Kombinatoren zur Verfügung gestellt werden, die den Baum von einem beliebigen Knoten aus top-down durchlaufen, die den Baum von einem beliebigen Knoten aus bottom-up durchlaufen. Kombinatoren, die unter Umständen nach einem gültigen Ergebnis suchen und auf eine fortgesetzte Suche verzichten, sowie Kombinatoren die eine vollständige Ergebnismenge zurückliefern. Wie bereits erwähnt sind Operationen auf Bäume: Suchen, Einfügen, Manipulieren, Löschen und Sortieren. Suchen ist wohl die Hauptfunktion einer Verarbeitung, denn Einfügen, Manipulieren und Löschen bestimmten Inhaltes setzt das Suchen und korrekte Aufsetzen auf einen Knoten voraus.
Folgende Transformationen müssen daher umgesetzt werden:
- alle Kindknoten eines bestimmten Elements zur Verarbeitung bereitstellen.
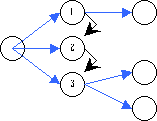
- den gesamten Inhalt eines Elements zu extrahieren. Wenn es sich
bei dem spezifizierten Element um das Wurzel-Element handelt, sollte
das gesamte Dokument sequentiell verarbeitet werden.

Ausdrucksstark wird die Verarbeitung erst, wenn es möglich ist, einen bestimmtn Knoten für eine Analyse oder Extraktion heranzuziehen. Hierfür muss eine Funktionalität zur Verfügung gestellt werden, die zunächst einen Knoten lokalisiert und von da aus die Weiterverarbeitung startet. Beispielsweise könnte auf Knoten '5' aufgesetzt werden und eine weiterführende Analyse die Knoten '6' und '7' verarbeiten. Wichtig bei Suchfunktionen ist es, dass verschiedene Suchkriterien kombiniert werden können. Ein Such-Algorithmus muss effizient sein. Er sollte, mit einer beliebigen Anzahl von einander einschränkenden Suchkriterien den XML-Baum durchsuchen können. Die einzelnen Suchkriterien müssen also verknüpft werden können.
Die Reihenfolge dieses Durchlaufs muss mit der sequentiellen Repräsentation des Dokuments übereinstimmen, die einem Links-Rechts-Tiefendurchlauf entspricht.
Eine solche Anforderung kann durch eine UND-Verknüpfung von Constraints beschrieben werden. (Irish composition)
Ein Such-Algorithmus sollte mit einer beliebigen Anzahl von Filtern losgeschickt werden können und sobald eines der Filter ein gültiges Ergebnis liefert die weitere Suche beenden. Ein solcher Suchvorgang kann durch eine ODER-Verknüpfung von Constraints beschrieben werden. (direct choice)
Ein Such-Algorithmus sollte es auch erlauben einen Suchvorgang mit unterschiedlichen Contraints sequentiell zu starten, wo eine Ergebnismenge zurückgeliefert wird, die sich aus den Ergebnissen der einzelnen Suchläufe ergibt. (append results)
Bei gewisser Kenntnis über ein Dokument kann es zu effizienteren Ergebnissen führen, wenn eine Bottom-Up-Selektion genauso möglich ist wie eine Top-Down-Selektion.
Eine Selektion sollte bei Existenz eines gesuchten Ergebnisses einen gültigen Wert zurückliefern bzw. eine vollständige Ergebnismenge, wenn diese benötigt wird.
Die Anfragesprache sollte neben Konjuktion und Disjunktion auch Negation zulassen.
- das Löschen von Teilen des Dokumentbaums. Soll ein Element
gelöscht werden, bedeutet dies gleichzeitig, das Löschen
aller resultierenden Kindknoten.
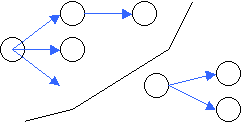
In den meisten Fällen wird, wenn ein oder mehrere Teilbäume gelöscht werden sollen, ein neues Dokument erzeugt. Bei der Erzeugung eines neuen Dokuments wird dann auf die zu löschenden Teilbäume verzichtet. Ob im nachhinein das alte Dokument vorgehalten wird hängt von Speicher und der zu verarbeitenden Anwendung ab. Das Löschen von Attributen wird hingegen dadurch erreicht, indem ein Element gegen ein neues Element ausgetauscht wird. Das neue Element hat dann die gewünschten Attribute.
- das Kopieren oder Verschieben von Teilen des Dokumentbaums.
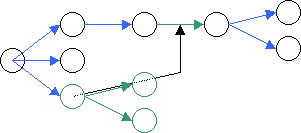
- das Einfügen neuer Dokumentteile.
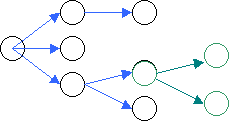
- das Manipulieren von Dokumentfragmenten kann sich auf Elemente,
durch Umbenennung der Elementnamen, Löschen, Einfügen und
Umbennung von Attributen und Inhalten beziehen.
Es sollte auch möglich sein abhängige Elemente in Bezug von
Eigenschaften einzuschränken und sie durch die bisherigen
abhängigen Elemente zu ersetzen.

- anhand von Mustern (patterns) Teilbäume aus einem XML-Baum zu
extrahieren ist wichtig. Es muss folglich möglich sein relevante Pfade
auszuwählen.
Die Auswahl/Einschränkung der Baumpfade erfolgt über
Mustervergleich (pattern matching).
Es scheint also sinnvoll Relationen zu beschreiben, wo zunächst
eine Vorselektion erfolgt um dann auf die Kindelemente der
Ergenismenge eine eingeschränkende Selektion anzuwenden.
Hierbei muss es möglich sein, das Ausgangselement in die
Ergebnismenge mit einzubeziehen, oder dieses zu vernachlässigen.
Es soll also 'Interior Search' und 'Exterior Search' möglich sein. - ein Such-Algorithmus muss effizient sein. Ein Suchalgorithmus sollte, mit einer beliebigen Anzahl von einander einschränkenden Suchkriterien, den XML-Baum durchsuchen können. Die einzelnen Suchkriterien müssen also verknüpft werden können. Die Reihenfolge dieses Durchlaufs muss mit der sequentiellen Repräsentation des Dokuments übereinstimmen, die einem Links-Rechts-Tiefendurchlauf entspricht. Eine solche Anforderung kann durch eine UND-Verknüpfung von Constraints beschrieben werden.
- ein Such-Algorithmus sollte mit einer beliebigen Anzahl von Filtern losgeschickt werden können und sobald eines der Filter ein gültiges Ergebnis liefert die weitere Suche beenden. Ein solcher Suchvorgang kann durch eine ODER-Verknüpfung von Constraints beschrieben werden.
- ein Such-Algorithmus sollte es auch erlauben einen Suchvorgang mit unterschiedlichen Contraints sequentiell zu starten, wo eine Ergebnismenge zurückgeliefert wird, die sich aus den Ergebnissen der einzelnen Suchläufe ergibt.
- bei gewisser Kenntnis über ein Dokument kann es zu effizienteren Ergebnissen führen, wenn eine Bottom-Up-Selektion genauso möglich ist wie eine Top-Down-Selektion. Eine Selektion sollte bei Existenz eines gesuchten Ergebnisses einen gültigen Wert zurückliefern bzw. eine vollständige Ergebnismenge, wenn diese benötigt wird.
- die Anfragesprache sollte neben Konjuktion und Disjunktion auch Negation zulassen.
[ XML und Haskell Seminar ] ... [ Thema XML Verarbeitung mit Haskell ] ... [ 4. Der funktionale Ansatz ]