 Unions
Unions
 Die VDM-Basistypen
Die VDM-Basistypen
 Optionals
Optionals
Definition Ein Tree ist das kartesische Produkt seiner Komponententypen, d.h. er kann alle möglichen Kombinationen von Werten seiner Komponententypen enthalten. Ein Tree-Objekt ist also eine festgelegte Aggregation mehrerer Komponenten eventuell unterschiedlichen Typs. Etwas ausführlicher:
Kartesisches Produkt Das kartesische Produkt kennen Sie von Funktionen mit mehreren Argumenten; sie bilden das kartesische Produkt der Argumenttypen auf den Resultattyp ab. Üblicherweise schreibt man das kartesische Produkt wie folgt:
![]()
Bei der Beschreibung von Trees werden die Kreuz-Operatoren üblicherweise weggelassen -- die Komponententypen werden einfach aufgezählt:
![]()
struct Natürlich kommt Ihnen das Konzept der Trees bekannt vor: in C gibt es den Typgenerator struct zur Aggregation mehrerer Komponenten unter einem Namen. Tatsächlich entspricht die praktische Konzeption des Tree-Datentyps im VDM-System dem struct, Trees werden mit ihrer Hilfe implementiert. Abstraktion Ein (theoretischer) Unterschied besteht nur darin, daß ein Tree von seiner Repräsentation abstrahiert, während einem struct mit seiner Definition gleichzeitig seine Repräsentation zugeordnet wird. Sie können mit Trees also genauso umgehen wie bisher mit structs, allerdings bringt der Satz an Operationen für Trees eine Einheitlichkeit in die Handhabung von Trees, die bei structs nicht möglich ist, eben weil deren Repräsentation durch die Definition feststeht.
Beispiel Ein Beispiel: Sie bauen einen Binärbaum auf; jeder Knoten hat ein Datenfeld und zwei Nachfolger. In einer Implementation mit structs realisieren Sie die Nachfolger mit Hilfe von Pointern auf gleichartige structs; bei jedem Zugriff auf einen Nachfolger benötigen Sie dieses Wissen, weil Sie den Pointer erst dereferenzieren müssen. Bei einem Tree hingegen kümmern Sie sich nicht um die Implementation, sondern verwenden immer die für jeden Tree vorhandenen Tree-Operationen. Außerdem können Sie zwei beliebig komplexe Binärbäume ohne Wissen über die interne Struktur auf Gleichheit testen -- bei einem struct ist ein selbstgeschriebenes Prädikat erforderlich, das Wissen über die Implementation zwingend erfordert!
Operationen Die Arbeit mit Trees erfordert nur sehr wenige Operationen: Erzeugung eines Tree-Objekts, Selektion einer Komponente, Überschreiben einer Komponente mit einem neuen Wert und Test auf Gleichheit zweier Trees.
Trees in C Aus der Wahl von C als Basissprache für das VDM-System ergeben sich zwei Aspekte, die in der bisher gegebenen Beschreibung von Trees nicht auftraten, da sie eben implementationsabhängig sind:
DSL Um in der DSL-Spezifikation einen Tree
Atree der Komponenten-Datentypen ![]() zu definieren (deren Komponentennamen hier zufällig gewählt wurden,
indem einfach die Sequenz ,,s_`` dem Namen des Komponententyps vorangestellt
wurde), schreiben Sie
zu definieren (deren Komponentennamen hier zufällig gewählt wurden,
indem einfach die Sequenz ,,s_`` dem Namen des Komponententyps vorangestellt
wurde), schreiben Sie
![]()
Beachten Sie, daß hier nicht das Gleichheitszeichen verwendet wird, sondern zwei Doppelpunkte!
Spezifikation mit VDM Für Trees gibt es in der VDM-Spezifikation zwei Vereinfachungen, was die Komponenten-Selektion in der let-Klausel betrifft:
Statt:
*
let b1 = s_B1(tree), b2 = s_B2(tree), ... , bn =
s_bn(tree) in ...
*
schreiben Sie
*
let mk-Tree(b1,b2, ... ,bn) = tree in ...
Wenn Sie nur einige Komponenten benötigen, lassen Sie die übrigen
weg:
*
let mk-Tree(b1,,,b4, ... ,b ![]() ,) = tree in ...
,) = tree in ...
*[4ex]
Anwendung Die übliche Anwendung ist die Modellierung von Datensätzen, also Sammlungen von verschiedenartigen Informationen über ein Objekt, verbunden mit der Möglichkeit, diese Datensätze mit Hilfe von Rekursion in eine bestimmte Struktur zu bringen, die z.B. die Sortierung nach bestimmten Kriterien erlaubt (z.B. Baumstrukturen oder verkettete Listen).
Beispiel: Wir modellieren einen Studenten-Datensatz mit Name, Geburtsdatum und Matrikelnummer:
DOMAINS
*
Student::s_name:Str
*
s_day : Nat1
*
s_month : Nat1
*
s_year : Nat1
*
s_matrno : Nat1
Für Trees stehen zwei Implementationen zur Verfügung:
Zur Veranschaulichung dienen folgende Variablen:
Students1,s2;
*
Str name1,name2;
*
Nat1 day,month,year,matr_no;
mk Mitmkerzeugen Sie einen
Tree aus der vollständigen Liste der Komponenten.
Beispiel -- Erzeugung eines Studenten-Datensatzes:
name1 enthält "Meier Fritz";
*
s1 = mk_student(name1, 7, 12, 1955, 142857);
*[1.5ex]
copy / copy1 Auch für Trees gibt es natürlich die Operationen zum Kopieren eines anderen Tree.
Es gibt zwei Klassen von Kombinatoren; die einen zerstören den vorherigen Zustand des Tree (tragen also die neue Komponente direkt in den gewünschten Tree ein), die anderen kopieren den Tree vorher und erhalten daher den vorherigen Zustand. Nomenklatur Beide Kombinatoren werden mit dem variablen Teil des Komponenten-Namens erweitert.
subst substüberschreibt die
gewünschte Komponente, nachdem der Tree vorher kopiert wurde; es wird also
gleichzeitig ein neuer Tree erzeugt, weshalb subst auch zu den
Konstruktoren gerechnet werden könnte. Vorsicht: Zuweisungen der Form
s1 = subst_xxx(s1, xxx);
*
erzeugen einen nicht-referenzierten Tree, weil der vorherige Inhalt von
s1 ja nicht zerstört wird -- Sie sollten subst also immer mit zwei
verschiedenen Tree-Objekten benutzen.
*
Beispiel -- Aufnahme eines weiteren Fritz Meier, der sogar am gleichen Tag
geboren ist, unter anderer Matrikelnummer:
s2 = subst_matrno(s1, 428571);
*[1.5ex]
chg chgüberschreibt die gewünschte
Komponente bei gleichzeitiger Zerstörung des vorherigen Tree-Zustands. Die
Sub-Strukturen werden allerdings, wie bei subst, nicht gelöscht; das
müßte durch ein explizites del geschehen.
*
Beispiel -- Änderung der Matrikelnummer des ersten Fritz Meier:
s1 = chg_matrno(s1, 857142);
*[1.5ex]
is_eq Mitis_eqtesten Sie,
ob zwei Trees komponentenweise gleich sind.
*
Beispiel -- der Vergleich der beiden Fritz Meier ergibt Unterschiede:
is_eq_student(s1,s2) == FALSE
*[1.5ex]
is_gr Mitis_grtesten Sie
komponentenweise, ob ein Tree größer als ein anderer Tree ist; das ist
allerdings nur möglich, wenn das Prädikat is_gr auch für alle
Komponententypen definiert ist.
*
Beispiel -- der zuerst aufgenommene Fritz Meier hat die höhere Matrikelnummer
(sie wurde ja auf 857142 geändert):
is_gr_student(s1, s2) == TRUE
*[1.5ex]
is_ge Mitis_getesten Sie komponentenweise, ob ein Tree größer oder gleich einem anderen Tree ist, d.h.\ ob eines der beiden obigen Prädikate erfüllt ist. Auch is_gr muß für alle Komponententypen definiert sein.
is_ge_student(s1, s2) == TRUE
*[1.5ex]
s Die Selektion einer Komponente hat den generischen
Namen s und wird mit dem variablen Teil des Komponenten-Namens erweitert
-- es ergibt sich also jeweils der komplette Komponentenname.
Selektion der Komponenten des ersten Fritz Meier:
name1=s_name(s1);
*
day = s_day(s1);
*
month = s_month(s1);
*
year = s_year(s1);
*
matr_no = s_matrno(s1);
*
Ein Binärbaum besteht aus Knoten, die Daten enthalten und eventuell einen oder zwei Nachfolger-Knoten. Hat ein Knoten keine Nachfolger (endet ein ,,Zweig`` des Baumes also bei diesem Knoten), wird er auch Blatt genannt. Der Ausgangsknoten eines Baumes heißt Wurzel. Die Nachfolge-Knoten werden üblicherweise als linker und rechter Nachfolger bezeichnet. Jeder Knoten bildet die Wurzel eines Teilbaumes, der wieder ein Binärbaum ist.
Anwendung Ein Binärbaum dient dazu, die enthaltenen Daten in eine bestimmte Ordnung zu bringen, also muß die Relation ,,größer als`` für den Elementtyp definiert sein. Dazu wird ein neues Element in den Baum derart aufgenommen, daß für jeden Knoten gilt: sein Datenelement ist größer als alle Datenelemente in dem Teilbaum ,,unter`` seinem linken Nachfolger, aber kleiner als alle Datenelemente in dem Teilbaum ,,unter`` seinem rechten Nachfolger. Abb. 5.4 zeigt einen Binärbaum von natürlichen Zahlen, der dieser Ordnung unterliegt.
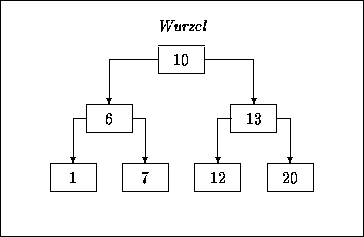
Abbildung 5.4: Beispiel für Trees: der Binärbaum
Der Binärbaum ist balanciert, wenn für jeden Teilbaum gilt: die Anzahl Knoten im linken ,,Sub-Baum`` unterscheidet sich von der Anzahl Knoten im rechten ,,Sub-Baum`` um maximal eins. Unser Beispiels-Baum ist also balanciert.
Aufgabe Wir wollen zunächst einen gegebenen Set von natürlichen Zahlen in einen Binärbaum ,,hineinsortieren``; danach möchten wir weitere Werte einfügen; schließlich soll es möglich sein, zu prüfen, ob ein bestimmtes Element im Baum enthalten ist oder nicht. Dazu benötigen wir drei semantische Funktionen: conv_nset wandelt den Set in einen äquivalenten Binärbaum um, exist prüft, ob ein Wert bereits im Baum enthalten ist, insert fügt einen neuen Wert in den Baum ein. Die Funktion conv_nset kann die Funktion insert verwenden, denn sie fügt alle Set-Elemente in den anfänglich leeren Baum ein.
Domain Zunächst müssen wir für den Binärbaum eine Domain-Gleichung aufstellen. Aus der obigen Definition ersehen wir, daß jeder Knoten einen optionalen linken und einen optionalen rechten Nachfolger hat, der jeweils wieder ein Binärbaum ist; jeder Knoten ,,enthält`` also keinen, einen oder zwei Binärbäume. Es bietet sich daher an, einen Binärbaum als Optional zu modellieren, das den Wert nil hat, wenn er keinen Knoten enthält, sonst aber seinen Wurzelknoten. Ist ein Knoten vorhanden, enthält er einen linken und einen rechten Nachfolge-Baum sowie ein Datenelement (also eine natürliche Zahl), kann daher mit Hilfe eines Tree modelliert werden. Sie erkennen vielleicht, daß die Repräsentation eines Binärbaumes rekursiv ist: ein Baum ist ein Knoten, der eventuell wieder Bäume enthält usw. Die Rekursion bricht auf der Blatt-Ebene ab, weil dort alle ,,Sub-Bäume`` leer sind (durch nil gekennzeichnet). Daraus ergibt sich folgende DSL-Spezifikation für einen Binärbaum (abgekürzt auch ,,Btree`` genannt):
DOMAINS
*
Btree=[ Node ]
*
Node :: s_lt: Btree
*
s_data : Nat0
*
s_rt : Btree
*
Nset = Nat0 -set
[0.5ex]
IMPLEMENTATIONS
*
Btree = ptelem + ...
*
Node = ptstruct + ...
*
Nset = linklist + ...
Initialisierung Ein leerer Binärbaum ist durch den Wert nil gekennzeichnet, also erfolgt die Initialisierung mit Hilfe der Optional-Operation mk_nil.
exist Die Funktion exist, die die Existenz des Wertes e im (Teil-)Baum b ermittelt, ist sehr einfach zu spezifizieren: für den Fall, daß der Teilbaum nicht vorhanden ist (also b = nil), ist das Ergebnis FALSE. Im anderen Fall wird e mit dem Datenelement der Wurzel von b verglichen -- sind die Werte gleich, ist das Ergebnis TRUE; ist e kleiner als das Datenelement, muß im linken ,,Sub-Baum`` weitergesucht werden, sonst im rechten. Die VDM-Spezifikation für exist und die C-Realisierung können wir sofort erstellen:
TYPE exist (b,e):BtreeNat0 ![]() Bool
Bool
*
exist =
*
cases b:
*
nil ![]() false
false
*
mk-node(lt,data,rt) ![]()
*
((e = data) ![]() true,
true,
*
(e < data) ![]() exist(lt,e),
exist(lt,e),
*
T ![]() exist(rt,e) )
exist(rt,e) )
Daraus wird die Funktion:
*[0.5ex]
Bool exist (Btree b, Nat0 e)
*
{
*
Node n;
*
Nat0 data;
*[0.5ex]
if (is_nil_btree(b))
*
return FALSE;
*
else {
*
n = s_node_btree(b);
*
data = s_data(n);
*
if (e == data)
*
return TRUE;
*
else
*
if (e < data)
*
return exist(s_lt(n),e);
*
else
*
return exist(s_rt(n),e);
*
}
*
}
*[2ex]
insert Die Funktion insert zum Einfügen eines neuen Wertes e arbeitet folgendermaßen: ist der (Teil-)Baum b leer, wird ein Baum mit einem Knoten (der das Datenelement e enthält) erzeugt und zurückgeliefert. Andernfalls wird e mit dem Datenelement der Wurzel von b verglichen:
Hier die VDM-Spezifikation von insert:
TYPE insert (b,e):BtreeNat0 ![]() Btree
Btree
*
insert =
*
cases b:
*
nil ![]() mk-node(nil, e,
nil)
mk-node(nil, e,
nil)
*
mk-node(lt,data,rt) ![]()
*
((e = data) ![]() b,
b,
*
(e < data) ![]() subst(lt,insert(lt,e)),
subst(lt,insert(lt,e)),
*
T ![]() subst(rt,insert(rt,e)) )
subst(rt,insert(rt,e)) )
*[2ex]
Auch diese Funktion können wir sofort in C implementieren, denn die Hilfsfunktion subst, die einen Teilbaum durch einen anderen ersetzt, steht uns als Tree-Operation zur Verfügung. Beachten Sie, daß mit subst_node eine Kopie des Teilbaumes erzeugt wird; daher müssen wir das Original nachher mit del löschen.
Btree insert (Btree b,Nat0 e)
*
{
*
Node n,n2;
*
Nat0 data;
*[0.5ex]
if (is_nil_btree(b))
*
return mk_opt_btree(mk_node(mk_nil_btree(), e,
mk_nil_btree()));
*
else {
*
n = s_node_btree(b);
*
data = s_data(n);
*
if (e == data)
*
return b;
*
else {
*
if (e < data)
*
n2 = subst_node(n, insert(s_lt(n),e));
*
else
*
n2 = subst_node(n, insert(s_rt(n),e));
*
del_node(n);
*
return n2;
*
}
*
}
*
}
*[2ex]
conv_nset Die Funktion conv_nset soll aus einem Set von natürlichen Zahlen einen sortierten Binärbaum erzeugen, ist also ein Konstruktor. Dazu erzeugt sie zunächst einen leeren Binärbaum (mit mk_nil); dieser wird nun einer Hilfsfunktion ins_nset übergeben, die einen Set in einen existierenden Binärbaum einfügt. Weil der Set von ins_nset zerstört wird, übergibt conv_nset eine Kopie des Set.
Btree conv_nset (Nset ns)
*
{
*
Btree b = mk_nil_btree();
*[0.5ex]
return ins_nset(b, copy1_nset(ns));
*
}
*[1.5ex]
ins_nset Die Hilfsfunktion ins_nset ist rekursiv. Ist der einzufügende Set leer, wird der aktuelle Binärbaum zurückgeliefert -- sonst wird eine Zahl aus dem Set selektiert, in den Binärbaum eingefügt (mit insert) und aus dem Set entfernt; mit dem kleineren Set und dem größeren Binärbaum wird nun ins_nset erneut aufgerufen. Hier die zugehörige VDM-Spezifikation:
TYPE ins_nset (b, ns):BtreeNset ![]() Btree
Btree
*
ins_nset =
*
if ns = {}
*
then b
*
else let e ![]() ns in
ns in
*
ins_nset(insert(b, e), ns \ {e})
*[1.5ex]
Diese Funktion müssen wir noch in C implementieren:
*
Btree ins_nset (Btree b,Nset ns)
*
{
*
Nat0 e;
*[0.5ex]
if (is_empty_nset(ns))
*
return b;
*
else {
*
e = sel_nset(ns);
*
return ins_nset(insert(b,e),sub1_nset(ns,e));
*
}
*
}
*
Wie bereits erwähnt, zerstört diese Funktion den Set, der ihr als Argument übergeben wird. Beachten Sie: die Struktur dieser Funktion ist identisch mit den mit dem Funktional binary für Sets erzeugten Funktionen, nur der Datentyp des ersten Arguments und des Resultats sind anders -- die ,,Fold-Funktion`` dient zur Verarbeitung des ersten Arguments (hier ein Tree, bei binary ein Set) und einem Element des zweiten Arguments (das sowohl hier als auch bei binary ein Set ist).
VDM Class Library