|
Woher stammen die Daten?
|
Die benötigten Daten sind die versagensfreie Laufzeiten des
Programmes. Sie können in der Installations- und Abnahmephase
oder der Nutzungsphase gesammelt werden und - sofern dafür
Black-Box-Tests verwendet werden - auch aus Systemtest, Abnahmetest
oder Validation stammen.
Man stellt sich hierzu folgendes Vorgehen vor: Eine lauffähige
Fassung des Programms wurde kompiliert und gebunden. Jetzt wird das
Programm mit zufällig gewählten Eingabedaten
(Testoperationsprofil) so oft gestartet, bis ein Fehler auftritt. Die
dabei angefallene Laufzeit des Programms ergibt insgesamt die Zeit bis
zum Versagen, also eine versagensfreie Laufzeit. Danach wird der
Fehler korrigiert, das Programm erneut kompiliert und gebunden, und
durch Laufenlassen mit dem Testoperationsprofil die nächste
versagensfreie Laufzeit ermittelt. Dieser Ablauf wiederholt sich.
In einem realen Eintwicklungs- bzw. Testprozeß kann es schwierig
sein, diese versagensfreien Laufzeiten zu ermitteln, z.B. wenn mehrere
Leute testen oder wenn es sich um einen Rechner handelt, der die
Laufzeiten des Programms nicht automatisch
erfaßt. Organisatorische Lösungen hierfür hängen
stark vom jeweils verfolgten Entwicklungskonzept ab; es wird of ein
Kompromiß zwischen optimalen und möglichen Genauigkeiten
erforderlich sein. Vorallem wenn kleinere Einheiten als ein ganzes
Programm betrachtet werden, wird eine Instrumentierung zur
Laufzeiterfassung erforderlich sein.
Ferner ist folgendes zu beachten:
- Das Testoperationsprofil muß repräsentativ für
den zukünftigen Betrieb sein, wenn die gewonnenen
Zuverlässigkeitsdaten darauf übertragen werden sollen. Ist
dies nicht erreichbar, soll man das Testoperationsprofil so
wählen, daß im Testbetrieb eine stärkere
Beanspruchung erwartet wird als im zukünftigen Betrieb, um
konservative Ergebnisse zu erhalten.
Je besser diese Voraussetzungen für die erfaßten Daten
zutreffen, desto verwertbarer werden sie für die Wachstumsmodelle
sein.
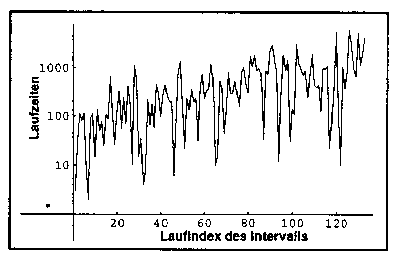
Versagensverhalten eines Programmes, Zeit
zwischen
Fehlern über der Anzahl gefundener Fehler
Das Bild zeigt einen Datensatz aus der Literatur. Auf der Abszisse ist
die laufende Nummer der gefundenen und beseitigten Fehler aufgetragen,
auf der Ordinate der Logarithmus der Laufzeit seit dem jeweils
vorhergehenden Fehler. Meist zeigt eine Darstellung nach diesem Bild
einen annähernd linearen Trend. Es empfiehlt sich jedoch, dies
für die eigenen Daten zu verifizieren, indem man einen
entsprechenden Plot herstellt.
Die Laufzeiten werden nicht in Kalenderzeit, sondern in Laufzeit des
Programms benötigt, entweder gemessen als Betriebszeit des
Rechners oder als CPU-Zeit.
Werden die Daten ausschließlich aus Black-Box-Tests genommen, so
kann auch die Arbeitszeit der Testenden Rechner benutzt werden. Die
Zeitbestimmung sollte auf die fehlerfreien Laufzeiten bezogen
sein. Bei Versagen im Tagesrhythmus sollte auf Stunden genau
erfaßt werden, bei Versagen im Abstand von Wochen reicht die
Erfassung auf Tage. Falls nur die Kalenderzeit erfaßt werden
kann, sollen zumindest offensichtliche ,,Schmutzeffekte'' eliminiert
werden, z.B. Wochenenden oder Betriebsferien.
Wichtig: Die Laufzeiten sind nach klaren, festzuschreibenden
Regeln vollständig und stets auf gleiche Art zu bestimmen. Eine
Mischung z.B. von CPU-Laufzeiten und Teststunden darf nicht
erfolgen. Auch darf kein Versagen unterschlagen weren, weil es
z.B. auf triviale Fehler zurückgeht.
Werden Black-Box-Tests zur Ermittlung versagensfreier Laufzeiten
herangezogen, so ist auf die Unabhängigkeit der Datensätze
des Testoperationsprofils voneinander zu achten. Ist z.B. ein
Testdatengenerator vorhanden, der zyklisch dieselben Testdaten an den
Testling gibt, so zählen nur die Laufzeiten aus einem Zyklus!
Jeder gefundene Fehler soll sofort beseitigt werde. Geschieht dies
nicht, dürfen Versagen, die auf ein und denselben Fehler
zurückgehen, nur einmal gezählt werden.
|