Pipes und Filter
(Pipes and Filters)
von Andreas Krutscher,
WI6443
[ Seminarübersicht] ...
[Architekturmuster] ... [Literatur]
... [ > ]
Name
Pipes und Filter (Pipes and Filter)
Das Pipes und Filter Architekturmuster bietet eine Struktur für
Systeme, die einen Datenstrom verarbeiten. Jeder verarbeitende Schritt
ist in einer Filterkomponente abgebildet. Zwischen benachbarten Filtern
werden Daten mittels Pipes transportiert. Filter lassen sich neu kombinieren
um verwandte Anwendungen zu erzeugen.
Auch bekannt als
(Für dieses Muster gibt es kein Synonym)
Beispiel
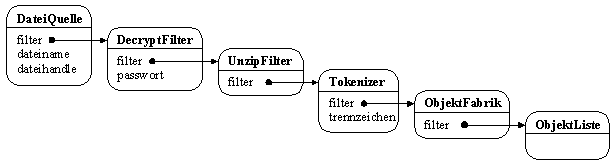
Als Beispiel wir ein System betrachtet, das Objekte aus einer Datei lädt
und in eine Liste speichert. Dabei ist erkennbar, daß die Gesamtaufgabe
in mehrere Phasen aufgeteilt ist. Jede Phase ist in einer Komponente abgebildet.
Jede Komponente nimmt eine definierte Aufgabe wahr: Die erste Komponente
liest Daten aus einer Datei, die zweite nimmt diese Daten her und entschlüsselt
sie. Die dritte Komponente nimmt die entschlüsselten Daten und entkomprimiert
sie. Die darauf folgende erhält nun einen Bytestrom, der ASCII Daten
enthält. Ihre Aufgabe ist, aus diesem Strom Standarddatentypen zu
lesen, also z.B. Integer- oder Float-Werte.
Diese werden von der vorletzten Komponente benötigt, um Objekte
zu erzeugen und zu initialisieren. Die letzte Komponente nimmt nun fertige
Objekte entgegen und ordnet sie in eine Liste ein.
Beispiel für eine Pipeline
Objekte aus einer Datei in eine Liste einlesen
Kontext
Verarbeitung von Datenströmen.
Problemstellung
-
Erweiterbarkeit soll gegeben sein
-
Austausch von verarbeitenden Schritten
-
Neues Aneinanderreihen/Rekombination
-
Kleinere Schritte erleichtern Wiederverwendbarkeit. Sie sind...
-
überschaubarer
-
in verschiedenen Kontexten einsetzbar
-
Kein Information-Sharing: nicht zusammen liegende Komponenten teilen keine
globalen Informationen
-
Verschiedene Quellen
-
Datei
-
Netzwerkverbindung
-
Sensoren für Temperaturmessungen...
-
Verschiedene Senken:
-
Datei
-
Bildschirm
-
Drucker
-
Netzwerkverbindung...
-
Zwischenspeichern ist/wäre
-
unübersichtlich, Unordnung im Dateisystem
-
fehleranfällig
-
gar nicht möglich
-
Parallelverarbeitung soll nicht ausgeschlossen werden
Die alles entscheidende Frage ist jedoch, ob eine Unterteilung in Teilaufgaben
überhaupt machbar ist. Dies hängt im wesentlichen von der zu
entwickelnden Applikation ab.
Lösung
Das Pipes und Filter Architekturmuster unterteilt die Aufgabe des Gesamtsystems
in sequentielle verarbeitende Schritte. Diese Schritte werden durch einen
Datenfluß durch das Gesamtsystem verbunden wobei die Ausgabedaten
des einen Filters die Eingabedaten des nächsten sind.
Jeder verarbeitende Schritt wird implementiert durch eine Filterkomponente.
Eine Filterkomponente verarbeitet seine Eingabedaten kontinuierlich und
stellt Ausgabedaten sofort bereit. Der Gegensatz dazu wäre, alle Eingabedaten
zu lesen bevor irgendein Ausgabedatum erzeugt wird.
Die Eingabe in das System wird durch Datenquellen hergestellt wie zum
Beispiel eine Textdatei (siehe Beispiel). Die Ausgabe
des Systems fließt in eine Datensenke, beispielsweise Bildschirm
oder Datei.
Pipes implementieren den Datenfluß. Dies geschieht entweder durch
eine echte Komponente, die den Datenfluß zwischen zwei benachbarten
Filtern synchronisiert. Pipes können aber auch unscheinbar wirken,
wie es in den Szenarien I-III dargestellt ist.
Zusammengefaßt:
-
Unterteilung des Gesamtproblems in Phasen
-
Jede Phase wird in einem Filter abgebildet, der die spezielle Aufgabe der
Phase implementiert
-
Filter verarbeiten kontinuierlich Eingabedaten zu Ausgabedaten
-
Die Ausgabe eines Filters ist die Eingabe des Nächsten
-
Pipes regeln Datenfluß, synchronisieren Filterkomponenten
-
Datenquellen besorgen die Eingabe in das System
-
Datensenken nehmen Resultate entgegen
Struktur
Filter
Filter bewerkstelligen die eigentliche Datenverarbeitung. Drei wesentliche
Aktivitäten können durch sie ausgeführt werden:
-
Anreichern: Berechnen und hinzufügen neuer Informationen, z.B. Hinzufügen
von
-
Zeitinformation zu Protokolleinträgen oder
-
Zeilennummern bei der Verarbeitung von Textzeilen
-
Verfeinern: Konzentrieren oder extrahieren von Daten, z.B. Konzentration
der Meßergebnisse eines Temperatur-Sensor auf ausschließlich
neue Werte (wenn sich die gemessene Temperatur geändert hat)
-
Umwandeln: Daten in einer anderen Form weiterreichen, z.B. Umwandeln eines
Textes in Großbuchstaben
Es gibt verschiedene Arten, auf die eine Aktivität eines Filters ausgelöst
werden kann. Dazu muß man zwischen passiven und aktiven Filtern unterscheiden:
-
Aktive Filter sind eigenständig laufende Prozesse oder Threads.
Sie werden nach ihrer Instantiierung und Initialisierung von einem übergeordneten
Programmteil aufgerufen und damit gestartet. Von diesem Zeitpunkt an laufen
sie kontinuierlich.
-
Passive Filter werden erst durch einen Aufruf durch ein benachbartes
Filterelement aktiviert. Hierbei sind nochmals zwei Konzepte zu unterscheiden:
-
Beim Push-Mechanismus wird ein Filter dann aktiviert, wenn sein
Vorgänger Ausgabedaten erzeugt hat und diese durch den Aufruf einer
Prozedur des zu aktivierenden Filters weiterreicht. Ein solcher Filter
wird also dann aktiv, wenn ihm Daten zugeschoben werden.
-
Beim Pull-Mechanismus wird ein Filter dann aktiviert, wenn sein
Nachfolger Daten durch den Aufruf einer Funktion beim zu aktivierenden
Filter anfordert. Ein solcher Filter wird dann aktiv, wenn Daten vom nachfolgenden
Filter benötigt werden.
Ein Beispiel für aktive Filter sind z.B. UNIX-Filter. UNIX-Filter
sind Programme, die jeweils in einem eigenständigen Prozeß ablaufen.
Alle Datenströme werden über Pipes abgewickelt, die das UNIX-System
zur Verfügung stellt.
Passive Filter sind eher untypisch, aber sie demonstrieren, daß
das Pipes und Filter-Konzept auch mit geringem Overhead realisierbar ist.
Oben haben Sie ein Beispiel für eine passive
Pipeline gesehen.
| Filter |
Mitarbeiter
Pipe
|
| Verantwortlichkeit
Eingabedaten lesen
Aktion auf Eingabedaten ausführen
Ausgabedaten anbieten
|
Pipe
Pipes sind die Verbindungsglieder zwischen Filtern, der Datenquelle und
dem erstem Filter und zwischen dem letzten Filter und der Datensenke. Verbindet
eine Pipe zwei aktive Filter, so muß sie sie synchronisieren. Dabei
werden schnellere Filter in ihrer Aktivität gebremst. Pipes können
Daten auch nach der FiFo-Strategie puffern, wenn dies die Anwendung erfordern
sollte. Bei direkten Methodenaufrufen - also bei passiven Filtern - ist
die Pipe nicht direkt erkennbar.
| Pipe |
Mitarbeiter
Datenquelle
Datensenke
Filter |
| Verantwortlichkeit
Daten weiterleiten
Daten puffern
Aktive Filter synchronisieren
|
Datenquelle
Eine Datenquelle bewerkstelligt die Eingabe in das System. Sie liefert
eine Sequenz gleichartiger Daten und versorgt damit die Pipeline indem
sie die Daten dem ersten Element der Pipeline zur Verfügung stellt.
Beispiele für konkrete Datenquellen: Datei zeilenweise auslesen (UNIX);
Sensor für bestimmte Messungen.
| Datenquelle |
Mitarbeiter
Pipe
|
| Verantwortlichkeit
Bereitstellen von Eingabedaten
|
Datensenke
Eine Datensenke sammelt die Ergebnisse der Pipeline und verfährt damit
in der zugeteilten Art und Weise. Beispiele: Eine Ausgabedatei oder der
Bildschirm.
| Datensenke |
Mitarbeiter
Pipe
|
| Verantwortlichkeit
Aufnehmen von Resultaten
|
Interaktionen
Folgende Szenarien verdeutlichen verschiedene Konzepte der Flußkontrolle
von Datenströmen zwischen Filtern. In den Szenarien sind jeweils Pipelines
dargestellt, die aus einer Datenquelle, einer Datensenke und zwei Filtern
bestehen. Filter1 und Filter2 arbeiten auf den Daten mit den Funktionen
f1() und f2().
Die Szenarien I-III sind Beispiele für Pipelines mit jeweils nur
einem aktiven Element, das die Kontrolle über die gesamte Pipeline
hält. Sie kommen ohne Pipe-Elemente aus, da Daten mit direkten Methodenaufrufen
aus dem vorigen Filter gelesen bzw. in den nachfolgenden Filter geschrieben
werden. In Szenario IV ist der etwas komplexere jedoch häufiger auftretende
Fall dargestellt, daß mehrere Filter aktiv sind und mit einem Pipe-Element
synchronisiert werden.
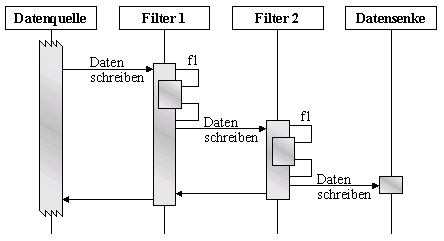
Szenario I zeigt eine Push-Pipeline.
Die Aktivität startet bei der Datenquelle. Die nachfolgenden Filter
werden durch das schreiben von Daten aktiviert.
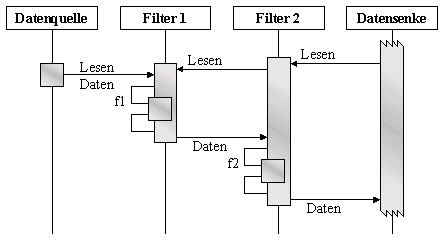
Szenario II zeigt eine Pull-Pipeline.
Hier startet die Abarbeitung bei der Datensenke, die Daten von seinem vorhergehenden
Filterelement anfordert.
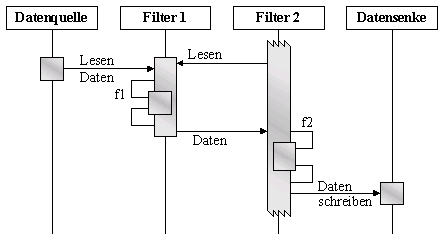
Szenario III zeigt eine gemischte Push-Pull
Pipeline mit einer passiven Datenquelle und einer passiven Datensenke.
Hier ist Filter2 aktiv und startet die Verarbeitung.
Szenario IV zeigt den Fall, der bei Pipelines
am häufigsten verwendet wird. Es gibt zwei oder mehr aktive Filterelemente.
In diesem Beispiel existiert eine Pipe zwischen Filter1 und Filter2. Sie
verfügt über einen Puffer. Aus Vereinfachungsgründen habe
dieser die Puffergröße 0. Beide Filter sind aktiv, d. h. sie
arbeiten unabhängig voneinander quasi parallel.
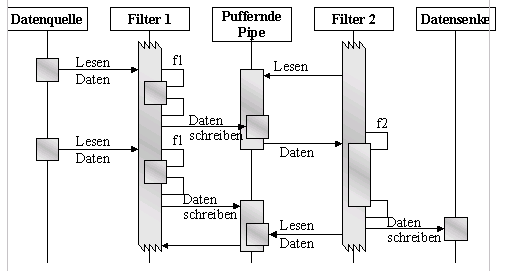
Folgende Schritte sind in diesem Szenario dargestellt:
-
Filter2 versucht Daten von der Pipe zu Lesen, es sind jedoch keine Daten
vorhanden. Infolgedessen wird Filter2 suspendiert - er muß wartet.
-
Filter1 liest einen Wert aus der Datenquelle und berechnet mit der Funktion
f1() einen Resultatwert
-
Filter1 schreibt dieses Resultat in die Pipe
-
Filter2 kann nun fortsetzen, da Daten vorhanden sind
-
Filter2 berechnet mit f2() ein Resultatwert und schreibt diesen in die
Datensenke.
-
Parallel dazu berechnet Filter1 einen neuen Wert und versucht diesen in
die Pipe zu schreiben. In diesem Fall wird Filter1 blockiert, weil Filter2
die Daten nicht aufnehmen kann - der Puffer ist voll.
-
Filter2 liest nun Daten von der Pipe. Dadurch wird das Warten von Filter1
gelöst
Implementierung
Implementierung gestaltet sich als ziemlich einfach: Zum einen kann man
sich der Systemdienste seines Betriebsystemes bedienen (Message queue,
UNIX Pipes, ...). Aber auch das Entwerfen von Komponenten für passiv
gesteuerte Pipelines über Direktaufrufe ist leicht zu implementieren.
Folgende sechs Schritte sind nötig zum Implementieren einer Pipeline:
1. Teile die Aufgabe in eine Sequenz von Unteraufgaben.
Jede Sequenz arbeitet lediglich auf den Ausgabedaten seines Vorgängers.
Alle Sequenzen sind konzeptionell durch einen Datenfluß verbunden.
Bereits hier ist es sinnvoll, alternative Kombinationen seiner Filter zu
betrachten - zum Beispiel dann, wenn die Filter später in einer Toolbox
veröffentlicht werden sollen.
Im Beispiel ist konzeptionell die Trennung zwischen Lesen der Daten
und dem Erzeugen von Objekten vollzogen. Weiterhin sind diese beiden Schritte
nochmals unterteilt. Dies ermöglicht zum Beispiel das einfache Weglassen
der Komprimierung oder der Verschlüsselung beim Lesen und Erstellen
(vorausgesetzt, die Daten wurden beim Schreiben nicht gepackt und verschlüsselt).
2. Definiere die Datenformate
Ein einheitliches Datenformat für alle Filter sichert eine hohe Flexibilität
bei der Rekombination von Filtern. UNIX Pipes z.B. lesen und erzeugen Textzeilen
ASCII-Format. Das macht sie so flexibel verwendbar. Allerdings birgt dies
auch einen Nachteil. Vollführt ein Filter beispielsweise numerische
Berechnungen, so ist eine Konvertierung der Eingabedaten notwendig, sofern
diese im Textformat vorliegen. Bei der Ausgabe im Textformat ist dann nochmals
eine Konvertierung nötig. Hier ist also ein Kompromiß zwischen
Flexibilität und Effizienz zu machen. Entscheidet man sich für
die Effizienz, so kann man Flexibilität wiederum dadurch erreichen,
daß man nur für die Konvertierung der Daten eigene Filter baut.
Als weiterer wichtiger Punkt ist noch zu betrachten, in welcher weise
Filterkomponenten das Ende des Datenstroms erkennen können sollen.
Eine bewährte Methode sind spezielle Ende-Marken im Datenstrom (Null,
-1, $, ctrl-D, ctrl-Z). Falls das System es ermöglicht ist ein End-Of-Input
Fehler, der von der Datenquelle beim Datenende geworfen und die Pipeline
entlang weitergereicht wird jedoch komfortabler.
Im Beispiel ist das Datenformat für die ersten Filter auf einen
Bytestream festgelegt. Der Tokenizer interpretiert seine Eingabedaten als
ASCII-Textdaten und erzeugt daraus Standard Datentypen (Integer, Float,
Boolean, Char, String, ...). Der Objekterzeuger liest als Eingabedaten
diese Datentypen und erzeugt daraus Objekte.
3. Wie sollen Pipes implementiert werden?
Die Art der Pipes hängt direkt davon ab, ob es sich bei den benachbarten
Filtern um aktive oder passive Filter handelt. Bei passiven Filtern
ist zu bestimmen, ob die Datenweitergabe nach dem Push- oder dem Pull-Konzept
geschehen soll. Die Datenweitergabe selbst ist durch Methodenaufrufe zu
implementieren. Eine passive Pipeline wird durch einen übergeordneten
Programmabschnitt aufgebaut und gestartet. Hierbei wird deutlich, daß
die zusammensetzung der Pipeline im Quelltext statisch verankert ist. Verschiedene
Konzepte, passive Pipelines zum Programmlaufzeit dynamisch zu erzeugen
sind allerdings denkbar.
Aktive Filter sind flexibler und leichter neu zu kombinieren. Sie sind
entweder als Prozeß oder als Thread zu implementieren. Bei der Entscheidung,
Filter als Prozesse zu implementieren können die Dienste des Betriebsystem
zur Interprozeß-Kommunikation (Queue, Pipe) als Pipes zwischen den
Filtern genutzt werden. Bei Threads müssen eigens Pipekomponenten
entworfen werden.
4. Entwerfe und implementiere die Filter
Die Implementierung der Filter ist abhängig von der Aufgabe und dem
Konzept, nach dem die Pipes realisiert werden sollen. Soll eine passive
Pipeline realisiert werden, so wird man jeden Filter durch eine Klasse
implementieren und die Filter aufeinander referenzieren, wie es auch im
Beispiel dargestellt ist. Beim Pull Konzept wird man in jeder Klasse zum
Abruf der Daten eine Funktion, z.B.
und für das Holen der Daten vom Vorgänger eine Referenz auf diesen
definieren. Z.B.
AbstractFilterClass filter;
Bei der Instantiierung wird dann jedem Objekt ein Zeiger auf seinen Vorgänger
mitgegeben. Somit kann jedes Filterobjekt durch einen einfachen Funktionsaufruf
seines Vorgängers Daten abrufen und diese bearbeiten.
Beim Push Konzept wird die Implementierung ähnlich aussehen. Die
Unterschiede sind die, daß anstelle von Funktionen Prozeduren
eingesetzt werden und jedes Objekt bei der Instantiierung eine Referenz
auf seinen Nachfolger bekommt. Folgendes Codefragment zeigt genau diese
Veränderungen:
write(Datentyp aVal) {
filter.write(f(aVal)));
};
Denkbar sind demnach auch Filterklassen, die sowohl für die Pull,
als auch für die Push-Methode einsetzbar sind. Bei der Instantiierung
muß man sich dann jedoch für eine der beiden Methode entscheiden.
Aktive Filter werden entweder als Applikation oder als Thread implementiert
werden. Bei der Implementierung als Applikation ist zu beachten, daß
ein zeitlicher Overhead aufgrund des Context-Switching zwischen Prozessen
und des Datentransportes zwischen verschiedenen Adressräumen hinzunehmen
ist. Bei letzterem spielt nicht zuletzt die Puffergröße der
gewählten Pipes eine entscheidende Rolle. Um dem Overhead entgegen
zu treten ist zu überlegen, ob sich die Wiederverwendbarkeit von Filtern
durch Parameterisierung erhöhen (Bsp. UNIX-Filter), und sich somit
die Zahl der Filter reduzieren läßt. Alternativ sind auch globale
Parameter oder Konfigurations-Dateien denkbar, obgleich sie dem Konzept
von Pipes und Filtern - keine globalen Daten - widersprechen. Der Kompromiß
zwischen Effizienz und Wiederverwendbarkeit ist gut zu überlegen und
abzuwägen! Als Regel sollte gelten:
Eine Filterkomponente sollte eine Sache beherrschen!
5. Entwerfe eine Fehlerbehandlung
Die Fehlerbehandlung wird viel zu oft ignoriert. In UNIX-Systemen werden
Fehler über den stderr-Kanal gemeldet. Dies ist eine sehr einfache
Art der Fehlerbehandlung und kann im zweifelsfall recht unübersichtlich
werden, wenn sich mehrere Filter in einer Pipeline befinden. In einem solchen
Fall ist eine Fehlermeldung schwer zuordenbar.
Gut ist, wenn die Verarbeitung nach Auftreten eines Fehlers wiederaufgesetzt
werden kann (z.B. Sprung nächste Zeile bei Verarbeitung von
Textzeilen). Es ist auch möglich, den Datenstrom in regelmäßigen
Abständen zu markieren um ein Wiederaufsetzen nach einem Fehler bei
der nächsten Marke zu ermöglichen.
Das Pipes und Filter Architekturmuster schreibt keine generelle Fehlerbehandlung
vor.
Im Beispiel kann eine Fehlerbehandlung mit dem Exception-Konzept von
Java geschehen.
6. Initialisiere die Pipeline
Im Fall einer passiven Pipeline wird der Zusammenbau in einem übergeordneten
Programmteil geschehen. Hier werden die Filterobjekte nacheinander erzeugt
und initialisiert werden. Den Objekten werden Referenzen auf ihre Vorgänger
(Pull) bzw. Nachfolger (Push) übergeben. Dann wird ein Filter, die
Datenquelle oder -senke gestartet.
Aktive Filter (z.B. UNIX) werden je nach Umgebung z.B. über eine
Shell mit entsprechenden Kommandos erzeugt und mit Pipes verbunden. Eine
Shell bietet Flexibilität beim Zusammenstellen von Pipelines. Denkbar
ist auch eine graphische Oberfläche, in der Pipes visuell mittels
drag & drop erstellt werden.
In unserem Beispiel werden alle Filterobjekte in einem übergeordneten
Programmabschnitt erzeugt und miteinander initialisiert (Entschlüsseler
mit Datei, Entkomprimierer mit Entschlüsseler, etc.).
Anwendung am Beispiel
Eine strenge Anwendung dieses Musters ist manchmal nicht möglich.
Manchmal ist es nötig, daß mehrere Filter gleichzeitig auf globale
Daten zugreifen müssen. Als Lösung wäre denkbar, jene Daten
entlang der Pipeline in Form von Parametern mitzuschicken. Aber auch hier
wäre aufgrund der dann höheren Komplexität ein Performanceverlust
hinzunehmen.
Varianten
Es ist möglich, das Konzept der einfachen Eingabe bzw. Ausgabe in
der Form auszuweiten, daß Filter Daten nicht nur an einen, sondern
an mehrere Nachfolger schicken oder von mehreren Vorgängern zusammen
sammeln. Das kann manchmal sinnvoll und nützlich sein, wirft aber
auch neue Probleme, z.B. Zyklen auf, die zu bedenken sind. In UNIX-Systemen
gibt es hierzu die Filterprogramme tee und comm. Der
Filter tee dupliziert Datenströme; comm konkateniert
zwei Datenströme zu einem.
Bekannte Verwendung
UNIX hat Pipes und Filter populär gemacht. Das System verfügt
über viele Filter-Programme, die ihre Eingabe in Form von Textzeilen
in der Standardeingabe (stdin) erwarten und ihre Ausgabe nach stdout schreiben.
Fehler werden über stderr ausgegeben. Verbunden werden diese Filter
mit Pipes, die das System zur Verfügung stellt.
LASSPTools sind ein Toolset für numerische Analyse und Grafik
Es besteht aus einer Menge von Filterprogrammen, Datenquellen (Grafische
Knöpfe, Schieberegler, ...) und Datensenken (Diagramme, ...). Zur
Anwendung kommen auch hier UNIX-Pipes.
Konsequenzen
Vorteile
-
Zwischenspeicher nicht notwendig, aber möglich
-
Flexibilität durch:
-
Austausch von Filtern
-
Andere Kombinationen von Filtern
-
Wiederverwendung
-
Prototyping
-
Parallelverarbeitung möglich
Verbindlichkeiten
-
Globale Informationen verringern Flexibilität
-
Effizienzgewinn durch Parallelverarbeitung ist oft eine Illusion
-
Overhead durch Datenkonvertierung
-
Fehlerbehandlung
Verwandte Muster
Hier sei nur das Layer Muster genannt. Der wesentliche Unterschied
ist der, daß die Datenverarbeitung nicht sequentiell parallel, sondern
hierarchisch verfeinernd (Beispiel OSI Netzwerk-Modell) abläuft.
[ Seminarübersicht]
... [Architekturmuster] ... [Literatur]
... [ > ]