|
|
[Seminarthemen WS08/09] [ < ] [ > ] [Übersicht]
|
|
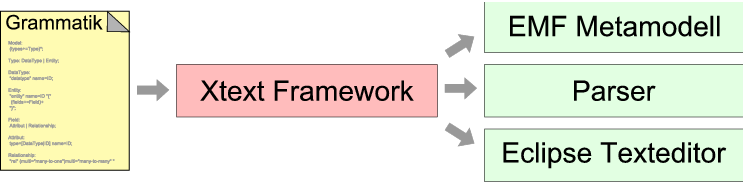
In Abbildung 4 sind die Hauptbestandteile des Frameworks dargestellt. openArchitectureWare besteht aus den drei Sprachen Xpand, Xtend und Check. Die Sprachen basieren alle auf einem gemeinsamen Typ- und Expressions-System, so dass dieses nur einmal gelernt werden muss und dann sofort in den anderen Sprachen angewandt werden kann. Zu openArchitectureWare gehört außerdem das Xtext-Framework, mit dem textuelle DSLs erstellt werden können.
Die Sprachen von openArchitectureWare
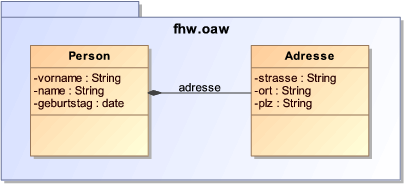
Um in das Thema openArchitectureWare und die damit verbundenen Komponenten besser einsteigen zu können, wird an dieser Stelle ein einführendes Beispiel besprochen. Wie die Komponenten dabei genau funktionieren und zusammenspielen wird in den folgenden Abschnitten besprochen werden. In Abbildung 5 ist ein einfaches Klassendiagramm dargestellt.
Um aus dem dargestellten UML Diagramm Java Quelltext zu generieren sind die folgenden Schritte notwendig:
Die Ausführung und De&64257;nition dieser Schritte erfolgt dabei in einem sogenannten Work&64258;ow. In Listing 2 ist ein Work&64258;ow dargestellt. Über die XmiReader-Komponente wird das Modell eingelesen. Anschließend wird eine Generatorkomponente gestartet, die das Modell anhand eines Templates (mit dem Namen Root) expandiert und in Quelltext umwandelt. Das Ergebnis wird in den Ordner src-gen geschrieben.
| Listing 2: | Erstes Beispiel: Work&64258;ow |
Einen ersten Eindruck darüber, wie diese Regeln formal notiert werden ist in Listing 3 zu sehen. Es werden dort, ähnlich zu XSLT, bestimmte Templates beschrieben, die dem Generator mitteilen, wie mit welchen Elementen zu verfahren ist. Die Kommandos sind dabei in « und » geklammert. Alles was außerhalb steht, wird als Text in die generierten Dateien übernommen. Es ist außerdem zu erkennen, dass aus einem Template weitere Funktionen aufgerufen werden können (z.B. asPackageName() ).
| Listing 3: | Erstes Beispiel: Template |
In Listing 4 ist die Ausgabe zu sehen, die bei der Ausführung des Work&64258;ows entsteht.
| Listing 4: | Erstes Beispiel: Ausgabe |
Dabei werden die beiden Dateien Person.java und Adresse.java erstellt. Die generierte Personen-Klasse ist in Listing 5 zu sehen.
| Listing 5: | Erstes Beispiel: Java Datei |
Die einzelnen Komponenten können über einen gemeinsamen Kontext die Laufzeitumgebung des Work&64258;ows abfragen. Diese Laufzeitumgebung wird Work&64258;owContext genannt und stellt sogenannte Slots bereit. In den Slots können Werte für nachfolgende Komponenten abgelegt werden. In Listing 6 ist ein beispielhafter Work&64258;ow mit Kommunikation über Slots aufgezeigt (vgl. [EFH+08, S. 65]).
| Listing 6: | Beispiel Work&64258;ow |
Zunächst wird eine Variable mit dem Namen target und dem Wert src-gen/ de&64257;niert. Die Generatorkomponente wird später auf den Wert zugreifen und unter dem angegebenen Pfad den generierten Code ablegen. Nachdem der XmiReader ein Modell eingelesen hat, wird dieses im Kontext unter dem Namen "model“ abgelegt. Die nachfolgenden Komponenten Checker und Generator greifen über diesen Namen wieder auf das Modell zu. In dem Beispiel ist gut zu erkennen, dass die Work&64258;ow-Komponenten jeweils einer Java-Klasse entsprechen. Während ein Work&64258;ow ausgeführt wird, müssen die entsprechenden Klassen in der Classpath-Variablen von Java au&64259;ndbar sein. Der Work&64258;ow kann über eine von openArchitectureWare vorgegebene Klasse Work&64258;owRunner gestartet werden. Auch ein indirekter Aufruf über die Eclipse-Plattform oder Apaches Ant ist möglich.
Bei der modellgetriebenen Entwicklung von Software ist darauf zu achten, dass die entwickelten Metamodelle keine Informationen über die Zielplattform enthalten, damit ein genügendes Abstraktionsniveau erhalten bleibt (vgl. [Pee07, S. 26]). Letztendlich muss aber Information für die Zielplattform bereitgestellt werden. Hierfür werden in openArchitectureWare sogenannte Cartridges genutzt. In einer Cartridge können plattformspezi&64257;sche Details getrennt von der fachlichen Seite modelliert werden. Um die Metamodelle der beiden Seiten zu vereinen kann eine M2M-Transformation genutzt werden, um so das fachliche Modell in das implementierungsabhängige Modell zu überführen (vgl. [SVEH07, S. 197]).
Als Beispiel soll hier eine Anwendung dienen, die mit Hilfe von Hibernate Entitäten in einer Datenbank persistent speichert. Für die Integration von Hibernate in die Anwendung ist es notwendig einige plattformspezi&64257;sche Elemente mit in das Metamodell aufzunehmen. Es muss formal festgelegt werden, was z.B. als Primärschlüssel zu verwenden ist, und nach welcher Strategie ein nächster Wert zu ermitteln ist. Diese Angaben haben aber keinen Bezug zur fachlichen Domäne des Metamodells. Durch die Kapselung der Funktionalität für Hibernate in eine Cartridge wird dieses Problem gelöst. Innerhalb der Cartridge wird ein eigenes Metamodell mit plattformspezi&64257;schen Aspekten entwickelt. Soll nun die Beispielanwendung mit Hibernate arbeiten, kann die Methodik der M2M-Transformation angewandt werden, um die DSL der Anwendung um spezi&64257;sche Aspekte der Hibernate-Cartridge zu erweitern und in ein Modell der Cartridge umzuwandeln (vgl. [SVEH07, S. 198]).
Auf der Seite des Fornax-Projektes [3] gibt es frei verfügbare Cartridges, die in das eigene Projekt eingebunden werden können. Hier wird z.B. eine Hibernate-Cartridge bereitgestellt. Somit muss das eigene Entwicklerteam nicht mehr über ein spezialisiertes Wissen über die Zielplattform verfügen.
Es existieren neben Codegeneratoren noch weitere Arten der Metaprogrammierung. In der Programmiersprache C wird ein Präprozessor eingesetzt, über den z.B. Konstanten am Anfang eines Quelltextes gesetzt werden können. Der Präprozessor wird dabei vor dem Aufruf des Compilers gestartet und generiert neue Codefragmente innerhalb des Quelltextes.
Als weiteres Beispiel können die Templates aus C++ und die Generics aus Java herangezogen werden. Der Compiler stellt hierbei die Möglichkeit zur Metaprogrammierung bereit und übersetzt die Schablonen jeweils in ein Konstrukt der jeweiligen Programmiersprache.
Es gibt also verschiedene Arten der Metaprogrammierung. Es kann sich um einen festen Bestandteil der Sprache (Templates) handeln oder um eine davon unabhängige Vorgehensweise (Präprozessoren). Der Codegenerator der openArchitectureWare arbeitet hier wie der Präprozessor und ist dem Compiler vorgeschaltet. Allerdings unterscheiden sich Generator und Präprozessor in einigen entscheidenden Punkten (vgl. [SVEH07, S. 145]):
Für einen Codegenerator muss nicht zwingend notwendig eine neue Sprache wie Xpand entworfen werden. Es ist durchaus denkbar diesen mit etablierten Methoden und Sprachen zu implementieren.
Generator mit XSLT Ein solcher Generator könnte zum Beispiel deklarativ über XML Stylesheet Transformation (XSLT) realisiert werden. XSLT ist Prinzipiell gut geeignet, da es für die Transformation von XML in beliebigen Text genutzt werden kann. Das Modell müsste also als XML-Baum und das Metamodell z.B. als XML Schema vorliegen. Der Vorteil ist hierbei, dass es bereits eine Vielzahl an Editoren und Validierungsmöglichkeiten gibt. Außerdem steht mit XPath ein gutes Werkzeug zur Objektnavigation zur Verfügung (vgl. [Kla07, S. 11]).
XSLT hat allerdings 2 entscheidende Nachteile. Auf der einen Seite werden XSLT Dateien, durch die XML Syntax bedingt, sehr schnell unübersichtlich und unleserlich. Zum Anderen kann während des Übersetzungsprozesses mit XSLT nicht ohne weiteres gegen das Metamodell validiert werden. Es muss also entweder vorher mit einen externen Werkzeug, oder hinterher durch den Compiler die Typsicherheit gewährleistet werden (vgl. [SVEH07, S. 147]).
Generator mit Java Es ist auch denkbar, dass ein Codegenerator in einer imperativen Programmiersprache (z.B. Java) geschrieben wird. Gegenüber XSLT bringt Java den Vorteil der Typisierung mit. Diese Typsicherheit kann allerdings nur innerhalb der Sprache gewährleistet werden. Somit muss das Modell in Form von Java-Objekten vorliegen, bzw. erst umgewandelt werden. Die Navigation auf dem Objektgraphen ist allerdings sehr kompliziert und muss oft über Schleifen umgesetzt werden (vgl. [SVEH07, S. 149]).
Ein weiterer Grund, warum sich imperative Programmiersprachen nur selten für Codegeneratoren eigenen, ist die Art der Textverarbeitung. In Java muss eine Verkettung zweier Strings explizit mit + gekennzeichnet werden und es gibt keine Texte, die über mehrere Zeilen laufen. Hier muss ebenfalls explizit ein Zeilenumbruch (&8726;n)eingefügt werden.
Generator in openArchitectureWare Xpand wurde entwickelt, um die Vorteile beider Ansätze zu vereinen, ohne dabei die Nachteile zu übernehmen. In Xpand kann auf das Typ- und Expressionsystem der openArchitectureWare zurückgegri&64256;en werden. Hiermit kann komfortable auf den Objektgraphen zugegri&64256;en werden (XPath) und das Typsystem ist nicht abhängig von der Hostsprache (Java). Die Syntax ist nicht so ausführlich wie in XML und somit gut zu warten. Es wird genau wie in XSLT deklarativ programmiert, was die Lesbarkeit des Generators weiter steigert. Außerdem ist die Verarbeitung von Texten sehr einfach, da zum einen Einrückungen und Zeilenumbrüche einfach in den generierten Quelltext übernommen werden. Zum anderen werden die Xpand-Kommandos nicht mit Mitteln der möglichen Zielsprachen (XML, Java, C, etc.) gekennzeichnet. Stattdessen werden französische Anführungszeichen « und » genutzt. Somit müssen Anführungszeichen nicht maskiert werden (vgl. [Kla07, S. 2]).
In Listing 7 ist eine Xpand-Datei zu sehen, in der eine Javaklasse mit einer statischen main Methode generiert wird.
| Listing 7: | Beispiel einer Xpand-Datei |
DEFINE Mit De&64257;ne gekennzeichnete Blöcke sind die elementaren Einheiten von Xpand und werden Templates genannt. Ein Template wird durch seinen Namen identi&64257;ziert und kann eine Liste von Parametern erhalten (siehe Listing 8). Nach dem Schlüsselwort FOR folgt der Name des Metatypen, für den das Template de&64257;niert ist. Der Zugri&64256; auf diesen Typen erfolgt innerhalb des DEFINE-Block implizit, oder explizit über this.
| Listing 8: | DEFINE |
EXPAND Mit dem XPAND-Block lassen sich andere Templates aufrufen (siehe Listing 9). definitionName entspricht dem aufzurufenden DEFINE-Namen. Sind in dem DEFINE-Block formale Parameter deklariert, müssen die aktuellen Parameter hier in Klammern übergeben werden. Folgt dem Namen kein FOR oder FOREACH, wird das Template für this aufgerufen. Ansonsten wird mit FOR und FOREACH das zu übergebende Objekt festgelegt (FOREACH ist für eine Liste von Objekten de&64257;niert).
| Listing 9: | XPAND |
IF und FOREACH Mit IF- und FOREACH-Blöcken stehen innerhalb von Templates Kontrollstrukturen bereit, die alternative Pfade oder Iterationen über Listen zulassen.
FILE Über den FILE-Block lassen sich aus Xpand heraus Dateien erstellen. Der Dateiname ergibt sich aus der Auswertung des Ausdrucks (siehe Listing 10). Die Statements innerhalb des FILE-Blocks geben den Inhalt der Datei vor. Die Datei wird in einem Verzeichnis gespeichert, welches über den Work&64258;ow angegeben wird (siehe auch Abschnitt 3.2).
PROTECT Es ist mit Xpand möglich geschützte Bereiche innerhalb des Quelltextes zu de&64257;nieren. Im generierten Quelltext wird dieser Bereich über eine Anfangs- und Endmarke festgelegt. In diesem Bereich können die Entwickler manuell Quelltext einfügen, ohne dass bei einem erneuten Generatoraufruf dieser Bereich überschrieben wird.
Die Verwendung geschützter Bereiche durchbricht allerdings die gewünschte Trennung von manuellem und generiertem Code, da beide in derselben Datei stehen und sollte nur in Situationen genutzt werden, in denen es gar nicht, oder nur mit erheblichem Mehraufwand zu verhindern ist. In den meisten Fällen können solche Situationen durch Mechanismen der Zielsprache (includes, Vererbung oder Entwurfsmuster) behoben werden (vgl. [SVEH07, S. 159f und S. 145]).
In Listing 11 ist ein Beispiel für einen PROTECTED-Block zu sehen. Über CSTART und CEND werden hier Kommentaranfang und -ende festgelegt. Zwischen CSTART und CEND wird ein über ID festgelegter Identi&64257;er geschrieben, der den PROTECTED-Bereich eindeutig kennzeichnet.
| Listing 11: | PROTECTED |
Eine generierte Quelldatei in Java könnte so aussehen, wie in Listing 12.
| Listing 12: | Generierte Datei mit geschütztem Bereich |
AROUND Die AROUND-Anweisung lässt aspektorientierte Programmierung in Xpand zu. Der nach dem Schlüsselwort AROUND stehende Teil de&64257;niert den Join Points des Aspektes. Der Join-Point entspricht einer in einem Template festgelegten Signatur.
Bevor das genannte Template expandiert wird, wird die AROUND-Anweisung ausgewertet. Hier kann über das vorgegebene Objekt targetDef auf das überschriebene Template zugegri&64256;en werden. Über die Methode proceed() kann das eigentliche Template ausgewertet werden (siehe Listing 13).
| Listing 13: | AROUND |
Wird auf den Aufruf von proceed() verzichtet, wird das Template nicht ausgewertet und somit überschrieben. Die AROUND Anweisung macht es also möglich vorhandene Templates mittels Aspektorientierung zu manipulieren, ohne dass der Quellcode geändert werden muss. Gerade in der Benutzung von Cartridges (siehe Abschnitt 3.2.1) kann dies von großer Bedeutung sein, da so leicht Änderungen vorgenommen werden können.
REM Kommentare lassen sich in Xpand mit dem REM Block kennzeichnen.
Ein Typ wird durch seinen Namen und einen Namensraum identi&64257;ziert. Dieser Namespace wird dabei durch :: getrennt. Ein Typ besteht aus Eigenschaften und Operationen und kann von anderen Typen abstammen. Das Typsystem besteht aus vorgefertigten built-in Types, sowie registrierten Metametamodellen. Es ist also möglich, dass System um weitere Typde&64257;nitionen zu erweitern (vgl. [EFH+08, S. 57]).
Built-in Types Einige der vorgegebenen Typen sind in der folgenden Liste aufgezeigt. Es gibt für die meisten dieser Typen mehrere Funktionen. Diese sind in der openArchitectureWare Referenz sehr gut erklärt (siehe [EFH+08]).
Die Syntax der Ausdrücke ist sehr ähnlich zu der in Java gebräuchlichen Notation. Mit myObject.name wird das Feld name der Instanz myObject selektiert. Analog dazu werden Methoden mit der Angabe von (param1,param2,...) aufgerufen (myObject.method()).
Einfache Operationen Da die meisten Typen so, oder so ähnlich auch in anderen Sprachen vorkommen, gibt es viele bekannte Funktionen für die verschiedenen Typen. Zum Beispiel bringt Object die Methode equals() mit. Zu diesen trivialen Operationen zählen auch +,-,<,>,!=,=,&&,||,… der numerischen und logischen Datentypen.
Funktionen höherer Ordnung Für Listen gibt es einige Funktionen (Higher order functions), die den Umgang mit Listen stark vereinfachen und so die geforderte Navigation über den Objektgraphen ermöglichen.
|
Kontrollstrukturen Auch in der Ausdruckssprache von openArchitectureWare gibt es Kontrollstrukturen in Form einer If-Anweisung und eines Switch-Verteilers.
In Listing 14 ist eine Beispiel-Extension dargestellt. Mit der import-Anweisung wird ein Metamodell importiert, das im Klassenpfad liegt, und es werden 3 Xtend Funktionen de&64257;niert. Für die aModelFunction wird der Rückgabetyp auf String festgelegt und 2 Parameter de&64257;niert. Die aModelFunction erwartet also ein Modell und einen String. Im Funktionsrumpf werden die beiden Parameter konkateniert und alle „::“ aus dem Metatypnamen durch einen „.“ ersetzt. Die benutze Syntax entspricht wieder der, aus dem einheitlichen Typ- und Expression-System. Bei der zweiten Funktion wird auf die Angabe des Rückgabetypen verzichtet. Stattdessen wird das Xtend-Framework den Typen selbst ermitteln. Die dritte delegiert die Arbeit an eine externe Java Klasse.
| Listing 14: | Beispiel-Extension |
Java Erweiterungen In dem unten stehenden Listing ist die Java-Klasse zu sehen, die aus der dritten Funktion des Extension Beispiels aufgerufen wurde. Die Funktion muss hierbei immer eine ö&64256;entliche und statische Funktion sein. Außerdem müssen die Rückgabe- und Parametertypen mit denen in der Xtend-Datei übereinstimmen. Zu beachten ist, dass die Angabe der Klasse und der Java-Typen in der Extension immer als full quali&64257;ed class name erfolgen muss.
| Listing 15: | Beispiel Java-Extension |
Zwischenspeichern der Funktionswerte Durch Voranstellen des Schlüsselwortes cached (siehe Listing 16) vor eine Xtend-Funktion, werden die Ergebnisse der Funktion in einem Cache zwischengespeichert. Der Schlüssel für den Cache ist hierbei erster Parameter. Für jeden Parameter wird die Funktion also nur einmal berechnet. Jeder weitere Aufruf erhält seinen Wert aus dem Cache.
| Listing 16: | Cached Extension |
Wie in obigem Listing zu erkennen ist, können Xtend Funktionen auf verschiedene Art und Weise deklariert werden. Zum einen können De&64257;nitionen direkt in der Xtend Datei erfolgen oder aber in externe Java-Klassen ausgelagert werden.
Aufruf in Xpand In Listing 17 ist ein zu dem Beispiel korrespondierender Aufruf innerhalb eines Xpand Templates zu sehen. Nachdem die Extension importiert wurde, können deren Funktionen genutzt werden. Für Modelle wird das Root-Template erweitert und eine Datei mit dem Namen "Model"+aModelFunction(".") erstellt. In dieser Datei werden verschiedene Texte an die eben de&64257;nierten Funktionen übergeben. Die Xtend Funktionen werden jeweils an den ersten Parameter gebunden. Die Aufrufe s.trimToLower() und trimToLower(s) sind also äquivalent (vgl. [EFH+08, S. 71]).
| Listing 17: | Beispiel Aufruf der Extension |
Wird das Xpand-Template innerhalb eines Work&64258;ows aufgerufen, wird eine Datei in das Dateisystem abgelegt. Der Inhalt dieser Datei und damit das Ergebnis des Aufrufs ist in Listing 18 zu sehen.
| Listing 18: | Beispiel Ausgabedatei Model.sddsl.Model |
Aufruf aus einem Work&64258;ow Eine Xtend-Funktion kann auch aus einem Work&64258;ow heraus gestartet werden. In folgendem Listing wird oaw.xtend.XtendComponent genutzt, um eine Xtend-Funktion zu starten. Der Komponente werden drei Informationen bereitgestellt. Es wird de&64257;niert, welche Extension zu laden ist und welche Funktion daraus aufgerufen werden soll. Außerdem wird der zu übergebende Parameter über einen Slotnamen zugewiesen.
| Listing 19: | Aufruf über Work&64258;owComponent |
In unten stehendem Listing wird eine Modell-zu-Modell-Transformation in Xtend formuliert. Das Modell wird dabei auf sich selbst abgebildet. Die create-Anweisung vor den Funktionsde&64257;nitionen erstellt eine Instanz des darauf folgenden Typen. Auf diese Instanz kann innerhalb der Funktion mit this zugegri&64256;en werden. Bei näherer Betrachtung von Listing 20 wird also deutlich, dass die Transformation durch ein Deep-Copy des Modells realisiert ist. Wichtig dabei ist, dass die erstellten Instanzen, wie mit der cached-Direktive, automatisch in einem Cache abgelegt werden. Somit werden gleiche Instanzen nur einmal erstellt. Soll zum Beispiel über eine Referenz eine Instanz erneut erstellt werden, so wird die bereits existierende Instanz zurückgeliefert.
| Listing 20: | M2M-Transformation mit Xtend |
Die Modelltransformation kann dann z.B. über die im vorigen Abschnitt gezeigte XtendComponent umsetzen. Es wird also durch den Work&64258;ow gesteuert, wann eine M2M-Transformation durchgeführt, welches Modell übergeben und was mit dem Ergebnis passieren wird.
| Listing 21: | Check-Constraint Entity |
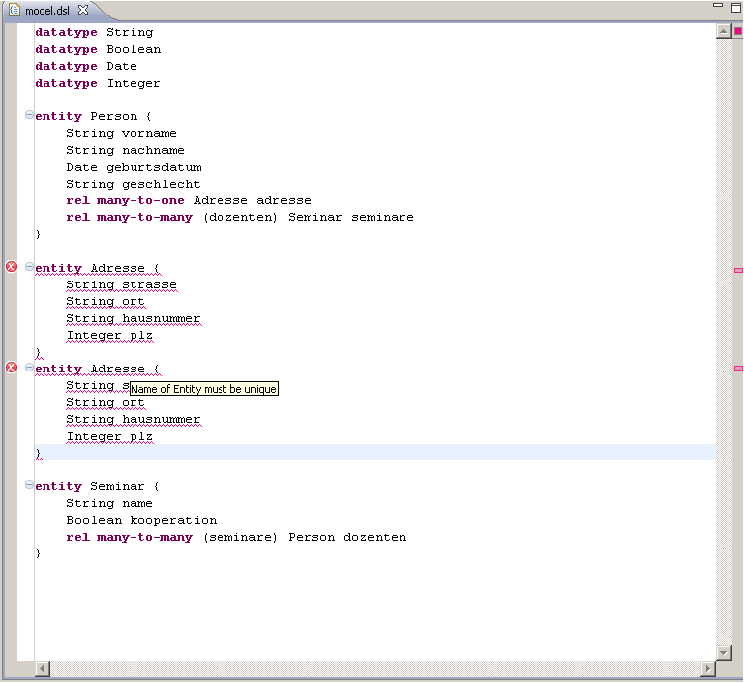
In Listing 21 ist eine vollständige Check Datei zu sehen. Es werden zunächst das Metamodell, sowie eine Extension (siehe Abschnitt 3.5) geladen. Darauf folgen die eigentlichen Constraints. Nach dem Schlüsselwort context steht der Name des Metatypen, für den diese Bedingung gilt. Die Angabe von ERROR oder WARNING signalisiert, um welchen Fehlergrad es sich bei der Bedingung handelt. Die auszugebende Meldung wird danach in Hochkommata notiert. Die eigentliche Check-Bedingung steht jeweils in der zweiten Zeile. Wird dieser boolesche Ausdruck zu Falsch ausgewertet, so wird ein Fehler (respektive Warnung) ausgelöst. Ist der Ausdruck hingegen Wahr, so gilt das Modell im Hinblick auf diese Bedingung als valide (siehe auch zweite Regel). In der ersten Bedingung wird die Eindeutigkeit der Entitynamen überprüft. Es werden aus allen Elementen des Modells, diejenigen herausge&64257;ltert, die den Metatypen Entity haben allElement().typeSelect(Entity). Aus dieser Untermenge von Elementen werden anschließend jene herausge&64257;ltert, die den gleichen Namen haben wie die zu validierende Entity this. Hat diese Menge mehr als ein Element, so wird ein Fehler ausgelöst. Wird während der Validierung ein Fehler oder eine Warnung erkannt, so werden diese über die aus dem Work&64258;ow bekannten Issues weitergeleitet, so dass die folgenden Komponenten Zugri&64256; darauf haben.
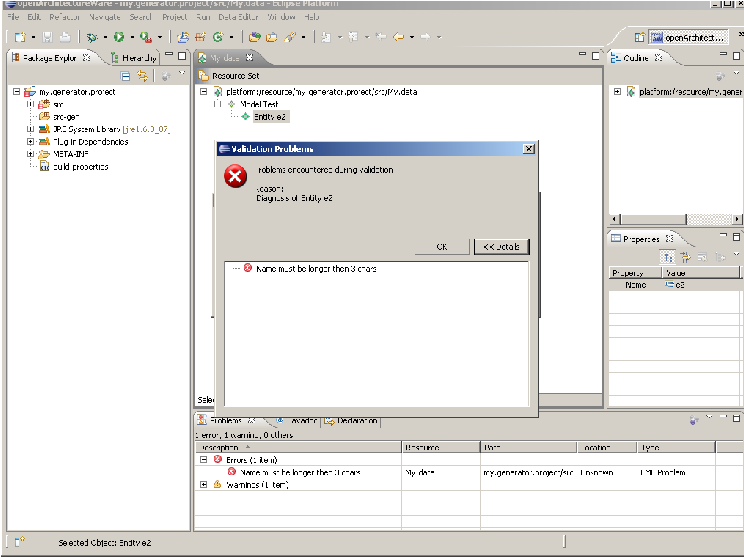
Überprüfung beim Erstellen Die Check-Constraints können zu verschiedenen Zeitpunkten aufgerufen werden. Wenn ein Metamodell z.B. mit Xtext erstellt wurde, kann damit auch ein Eclipse-Texteditor generiert werden. Dieser kann sofort bei der Eingabe solche Constraints auswerten und dem Entwickler die genaue Fehlerstelle im Modell markieren. Existiert das Metamodell z.B. als EMF Ecore, so kann auch hier der generierte Editor (siehe Abbildung 8) die in Check formulierten Bedingungen auswerten und direkt darauf hinweisen (vgl. [SVEH07, S. 61]).
Überprüfung bei der Generierung Da in einem Projekt nicht immer sichergestellt ist, dass die Editoren die Modelle bereits ausreichend validiert haben, sollte die Validierung vor der Generierung wiederholt und abschließend durchgeführt werden. Bevor in einem Work&64258;ow also ein Generator-Aufruf erfolgt, wird eine Validierungs-Komponente eingefügt. Somit ist sichergestellt, dass der Parser immer gültige Modelle erhält (vgl. [SVEH07, S. 61]).
Wie oben gesehen, gibt es verschiedene Zeitpunkte, zu denen ein Modell validiert werden kann und sollte. Um dem Entwicklerteam hier die Arbeit zu erleichtern, ist es sinnvoll die Bedingungen nur an einer Stelle zu formulieren. openArchitectureWare erfüllt mit Check genau diese Vorgabe, da sowohl die generierten Editoren, als auch der Work&64258;ow auf dieselben Constraints zugreifen. Somit ist eine Validierung bei der Eingabe und im Build-Prozess auf einheitlicher Basis möglich (vgl. [SVEH07, S. 61]).
Die Grammatik Wie oben angedeutet wird die Grammatik in einer Backus-Naur-Form beschrieben. Aus diesen Regeln wird aber nicht nur die konkrete Syntax für die Notation des Modells abgeleitet, sondern auch die abstrakte Syntax des Metamodells festgelegt (vgl. [SVEH07, S. 104f]).
| Listing 22: | Beispiel Entität |
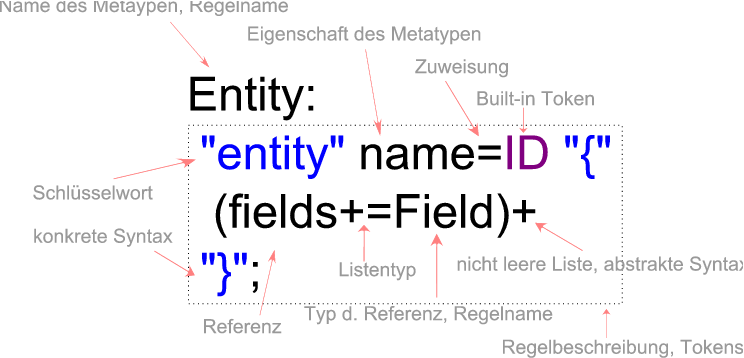
In Listing 22 ist ein Ausschnitt aus einer Grammatik zu sehen. Es wird eine Regel mit dem Namen Entity de&64257;niert. Die Regelbeschreibung folgt dem Namen in Form von Tokens und wird mit einem ; abgeschlossen. In der Regelbeschreibung lässt sich die konkrete Syntax erkennen. Es gibt ein Schlüsselwort entity, nach dem ein Identi&64257;er stehen muss. In Klammern eingebettet folgt dann die De&64257;nition der Entität. Für das Metamodell bedeutet diese Regel, dass es einen Metatypen mit dem Namen Entity gibt und dieser zwei Felder besitzt. Ein einfaches Attribut name mit dem Typen ID und eine Referenz &64257;elds auf einen anderen Metatypen Field. Das += weist der Referenz den Typen Liste von Field zu und das + sorgt dafür, dass die Liste nicht leer sein kann (Vgl. auch Abbildung 10). In dem Beispiel wird ein von Xtext vorgegebener built-in Token ID genutzt. ID ist eine vorde&64257;nierte Regel der Form (’a-zA-Z_’(’a-zA-Z_0-9’)*) (vgl. [EFH+08, S. 104]).
Die Notation einer Entity ist in Listing 23 dargestellt.
| Listing 23: | Notation einer Entität |
Zuweisungen Bei der Erstellung des Metamodells spielen die Zuweisungen in der Grammatik eine große Rolle. Sowohl die Art der Zuweisung, als auch die rechte Seite haben Ein&64258;uss auf den Typen, der letztendlich dem Feld im Metamodell zugewiesen wird. Es gibt folgende Arten von Zuweisungen:
Der Editor Das Xtext-Framework kann aus der Grammatik einen Editor für die Eclipse Entwicklungsumgebung generieren (siehe Abbildung 11). Dieser Editor beherrscht dabei schon die Funktionen aus der unten stehenden Liste (vgl. [Völ07, S. 3]). Die Validierung erfolgt hierbei mit den openArchitectureWare eigenen Mitteln über die Validierungs-Sprache Check (siehe Abschnitt 3.6).
[Seminarthemen WS08/09] [ < ] [ > ] [Übersicht]