Embedded Linux
Begriffsklärung
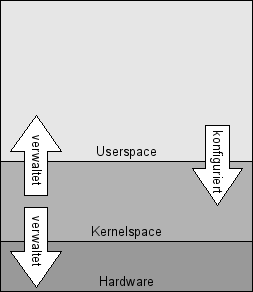
Im allgemeinen Sprachgebrauch ist meist vom „Betriebssystem Linux“ die Rede. Diese Formulierung ist jedoch nicht ganz korrekt, da der Begriff Linux eigentlich nur den Kernel bezeichnet. Ein vollständiges Betriebssystem besteht jedoch aus mindestens zwei, häufig in separaten Privilegienstufen laufenden Adressräumen:
- Kernelspace
-
Im Kernelspace läuft als einziger Prozess der Kernel. Dieser ist für die Verwaltung und Zuweisung von Ressourcen wie Arbeitsspeicher, Rechenzeit und Peripherie zuständig. Bei einem monolithischen Kernel wie Linux laufen die meisten Treiber ebenfalls im Kernelspace. Dies bedeutet jedoch nicht, dass es sich beim Kernel zwangsweise um ein einziges statisches Binary handeln muss: Treiber sind als Module realisiert und können damit dynamisch geladen werden.
- Userspace
-
Im Userspace laufen die Anwenderprogramme und Dienste als einzelne Prozesse mit jeweils eigenem Adressraum, bei vorhandener MMU sind diese vor gegenseitigem Zugriff geschützt. Das Gegenstück zu einem monolithischen Kernel ist der Mikrokernel, bei dem nur die notwendigsten Systemdienste im Kernelspace laufen und Treiber als Dienste im Userspace implementiert sind. Über die Vor- und Nachteile der beiden Technologien gibt es ausführliche Debatten und Auseinandersetzungen, die bekannteste ist wohl Andrew Tanenbaums Kritik Linux is obsolete. In der Praxis hat sich die dynamisch-monolithische Struktur des Linux Kernels jedoch bewährt. Durch Bibliotheken wie libusb, FUSE und UIO nehmen Implementationen von nicht-zeitkritischen Treibern im Userspace auch unter Linux zu.
Selbst wenn alle nötigen Treiber statisch in den Kernel eingebunden sind, fehlt in der Regel eine Funktion um diese sinnvoll zu konfigurieren und zu nutzen. Daher ist ein Kernel alleine nur in den seltensten Fällen sinnvoll einsetzbar und es wird mindestens ein sogenanntes Userland benötigt. Dieses stellt die nötigsten Befehle zur Verfügung um mit dem System zu arbeiten.
Historisch bedingt wird auf Linux-Systemen meist das Userland des GNU Projekts eingesetzt. Daher kommt es, dass manchmal von GNU/Linux die Rede ist. Diese Formulierung hat sich jedoch nicht durchgesetzt und unter dem Begriff Linux wird umgangssprachlich allgemein ein auf dem Linux-Kernel basierendes Betriebssystem verstanden.
Entwicklungsprozess
Der Linux-Kernel ist ein dezentrales, quelloffenes Projekt lizenziert unter der GPL 2.0. Er wurde im August 1991 vom damaligen Studenten Linus Torvalds als privates Experiment veröffentlicht. Zur Überraschung vieler, nicht zuletzt Torvalds selber, fand das Projekt schon bald Anhänger und die Geschichte nahm ihren Lauf. Heute umfasst der Kernel mehr als 10 Millionen Zeilen Code, täglich werden ca. 5000 Zeilen modifiziert.
Neben dem offiziellen, von Linus Torvalds gepflegten 2.6er-Zweig existieren weitere Varianten, z. B. linux-next als Aufnahmepunkt für neue Features in die nächste Version oder der von Willy Tarreau weitergepflegte 2.4er-Zweig. Prinzipiell kann jeder eine eigene Version erstellen; dies wird durch das eingesetzte Versionsverwaltungssystem Git gefördert. Speziell für Embedded Systems gibt es diverse weitere Zweige, z. B. die des uClinux-Projektssowie die der architekturspezifischen Projekte für ARM, AVR32, Blackfin, M32R, MIPS, m68k, PowerPC, SuperH und anderen Architekturen.
Lange Zeit folgte der Linux Kernel einem vorhersehbaren Versionierungsschema: Die Versionsnummer war aufgeteilt in drei Ziffern: Die erste repräsentiert die Major-Versionsnummer, die sich nur bei einschneidenden Veränderungen ändert. So war die Version 2.0 die erste, die mit SMP-Systemen umgehen konnte. Es folgt die Minor-Nummer, die ebenfalls nur für große Änderungen angepasst wurde. Die stabile Kernel-Version wurde durch gerade Ziffern an dieser Stelle markiert. Eine ungerade zweiten Ziffer repräsentierten experimentelle Zweige, aus denen nach einiger Zeit die nächste stabile Version hervor ging.Sowohl die stabilen als auch die experimentellen Zweige wurden gepflegt, was sich in der Erhöhung der dritten Ziffer wiederspiegelte.
Mit dem 2.6er-Zweig hatte der Kernel ein Maß an Komplexität erreicht, das es schwer bis unmöglich machte, Änderungen zu identifizieren, die die Erhöhung der Minor- oder gar der Major-Versionsnummer rechtfertigen würden. Daher wurde mit der Version 2.6.11.1 im März 2005 das Versionierungsschema erweitert und dem geänderten Entwicklungsprozess angepasst (der so später auch für den 2.4er-Zweig übernommen wurde): Die letzten ein bis zwei veröffentlichten Versionen werden als stabile Zweige mit einer inkrementierenden vierten Versionsnummer eine Zeit lang weitergepflegt, während auch experimentelle Funktionen während des Merge Window über die Verwalter der verschiedenen Subprojekte in die nächste Version gelangen. Da die ersten zwei Ziffern zunehmend an Bedeutung verlieren, taucht immer wieder mal die Diskussion auf, ob die Kernel-Versionsnummer nicht zu verkürzen sei. Als Vorschläge existieren ein Jahresbasiertes Schema (z. B. 2009.1.2 oder 2.9.2 statt 2.8.28.2) oder ein willkürlicher Sprung der Version auf 3.0.0 und damit dem Streichen einer Ziffer.
Auch wenn sich diese Ausführungen sehr theoretisch anhören, hat sie gerade für den Embedded Developer und die in diesem Bereich verbreiteten Entwicklungsprozesse große Relevanz. Oft wird ein Embedded System basierend auf einer festen Kernel-Version veröffentlicht und diese Version wird für alle folgenden Versionen beibehalten. Dies hat nicht nur zur Folge, dass Entwickler im Embedded-Bereich auch heute noch mit alten bis antiken Kernel-Version wie der 2.0.38 konfrontiert werden können. Immerhin 20% bis 40% der Antworten auf eine nicht-repräsentative Umfrage zum Einsatz der 2.4er-Reihe gaben Embedded Systems und systemkritische dedizierte Systeme als Grundlage an.
Diese Umfrage verdeutlichte auch wieder, dass gerade bei einem gepatchten Kernel die Gefahr groß ist, dass der offizielle Kernel, auch bedingt durch ein fehlendes stabiles API oder ABI, innerhalb kurzer Zeit von der ursprünglichen Version derart divergiert, dass bei einem späteren wichtigen Release (z. B. einem Sicherheitsupdate) umfangreiche Anpassungen der Patches erforderlich sind.
![[Anmerkung]](note.png) |
|
|
Es empfiehlt sich daher, beim Einsatz von Linux für Embedded Systems stets einen Zweig des Produkts mit dem aktuellsten Kernel und den dazugehörigen Tools zu pflegen. Das kontinuierliche Pflegen ist auf Dauer gesehen nicht nur weniger Aufwändig als ein einzelner großer Versionsschritt unter Zeitdruck, sondern hat auch den Nebeneffekt, dass der Code einem ständigen Audit unterliegt. Code sollte am Besten von Anfang an so geschrieben werden, als sei er für die Aufnahme in den Kernel vorgesehen. |
Gerade bei Embedded Systems ist die Laufzeit des Systems häufig wichtig und schwer zu wartende Modifikationen sind nicht nur umständlich zu portieren, sondern auch fehleranfällig. Wenn neue Funktionalität benötigt wird, ist es zudem ratsam, auf bereits existierenden Lösungen aufzubauen und nicht das Rad neu zu erfinden.
Betriebssystemaufbau
Auf Linux basierende Betriebssysteme bzw. Distributionen sind zumeist modular aufgebaut. Funktionalitäten können in der Form von Treibern und Diensten bzw. entsprechenden Paketen relativ problemlos hinzugefügt oder entfernt werden. Prinzipiell lässt sich auf einem Embedded System die selbe Software wie etwa auf einem Server-System einsetzen, solange es denn die verfügbare Hardware zulässt. Gerade der Einsatz von Standardsoftware auf ungewöhnlichen Prozessorarchitekturen schlägt jedoch häufig fehl, da diese häufig nicht ausreichend plattformunabhängig geschrieben ist. Für solche Fälle oder bei eingeschränkter Hardwareumgebung existieren oft alternative, speziell für Embedded Systems entwickelte Lösungen.
Zur Paketverwaltung kommt neben einigen proprietären Lösungen und abgespeckten Formen von RPM häufig das von Debians dpkg inspirierte ipkg und dessen Erweiterung opkg zum Einsatz. Das bedeutet, dass bei den meisten Distributionen die Pakete wie gewohnt nachinstalliert werden können und nicht aus den Quellen übersetzt (und ihre Abhängigkeiten zuvor aufgelöst) werden müssen.
Um die Software selbst portabel zu halten, wird eine Abstraktionsschicht zu den architekturspezifischen System Calls benötigt. Diese wird von der sogenannten libc bereitgestellt, die damit einen essentiellen Bestandteil eines jeden auf Linux basierenden Betriebssystem ausmacht. Da die GNU libc häufig zu umfangreich für Embedded Systems ist, gibt es mehrere Alternativen. Dazu gehören die aus dem uClinux-Projekt entstammende uClibc, die eher für statische Systeme gedachte diet libc, sowie, selten eingesetzt, die newlib.
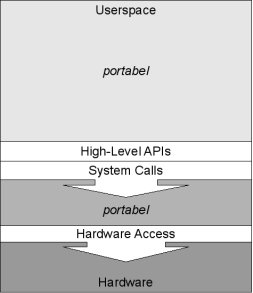
Neben den System Calls sowie procfs und sysfs gehören die Device Nodes zur Kernel-API. Diese bieten einen einfachen, dateibasierten Zugriff auf fast alle Geräte. Da jede Device Node eindeutig über die Major- und die Minor-Nummer identifiziert wird und es insgesamt mehr als zehntausend gültige Kombinationen gibt, gestaltet sich die statische Verwaltung dieser Dateien in dynamischen Systemen schwierig. Daher wurde der Dienst udev im Userspace eingeführt, der diese Dateien dynamisch generiert. In relativ statischen Systemen wie Embedded Systems, kann wenn der Speicher knapp wird auf diesen Dienst evtl. auch verzichtet werden.
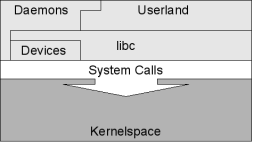
Schließlich gibt es auch zum GNU Userland Alternativen, am bekanntesten (und das nicht nur aufgrund des GPL-Violations Projekts) ist dort BusyBox.
Zusammen mit diversen anwendungsspezifischen Diensten (den Daemons) stellen diese Bestandteile das Basissystem eines Linux Betriebsystem.
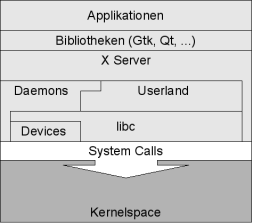
Bei einem Embedded System mit GUI wird zusätzlich eine API zur Abstraktion des darunterliegenden Systems sowie zur Verwaltung der Fenster benötigt. Hier kommt meist der X.Org X-Server oder sein kleiner Ableger KDrive zum Einsatz. Alternativ ist es durchaus möglich über Bibliotheken wie DirectFB, Qt Extended oder SDL spezielle Software zu schreiben die auf den X-Server verzichtet.
Bootvorgang
Beim Starten des Systems muss zuallererst der Kernel geladen werden. Dazu wird meistens ein Bootloader benötigt, da (mit wenigen Ausnahmen) die Firmware den Kernel nicht direkt laden kann. Zwar können auch hier manchmal durchaus die bekannten Loader GRUB, LILO oder Syslinux verwendet werden (und sei es in gepatchter Form), häufig werden jedoch speziell angepasste Alternativen benötigt. Häufig anzutreffen sind RedBoot und U-Boot, diese bieten auch eine Funktion, um das System via BOOTP/PXE zu starten oder zu flashen.
Der Bootloader übergibt die Kontrolle an den Kernel, der nach einigen grundlegenden Konfigurationen die Kontrolle an den init-Prozess des Userlands übergibt. Daraufhin folgt häufig eine an System V angelehnte, Script-gesteuerte Bootprozedur, die neben den benötigten Diensten in der Regel ein getty startet.