Die Komplexität von Algorithmen wird in der O-Notation angegeben, als
mathematische Beschreibung der Laufzeit eines Algorithmus. Eine Komplexität
von O(n) bezeichnet Algorithmen, deren Laufzeit linear von der Menge der Eingabedaten
abhängt. Ein Algorithmus der Komplexität O(1) läuft in konstanter
Laufzeit unabhängig von der Eingabemenge.
Beim Scheduler im Linux Kernel 2.4 war die Laufzeit des Schedulers abhängig
von der Anzahl der wartenden Prozesse. So ist der Scheduler gerade dann langsamer
geworden, wenn mehr Prozesse etwas von der kostbaren Rechenzeit benutzen wollten.
Der Scheduler im Linux Kernel 2.6 läuft dagegen nicht nur immer gleich
lang, sondern auch noch schneller und effizienter.
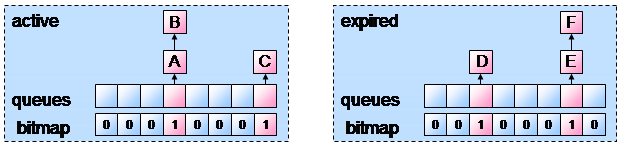
Der Scheduler verwaltet für jeden Prozessor im System eine Warteschlange.
In dieser Runqueue sind die Prozesse verlinkt, die auf Rechenzeit warten.
Eine Runqueue wiederum besteht aus zwei Prioritäts-Arrays, den wichtigsten
Elementen einer Runqueue. In den Arrays sind für jede Priorität Zeiger
auf verkettete Listen gespeichert. Jede dieser Listen wiederum enthält
die laufwilligen Prozesse.
Zusätzlich sind in den Arrays noch Informationen über die Anzahl der
wartenden Prozesse und eine Bitmap enthalten, die signalisiert welche der verketteten
Listen Einträge enthält.
Die beiden Prioritäts-Arrays einer Runqueue sind deklariert als Active
und Expired.
Der Scheduler sucht nun die nicht-leere Liste mit der höchsten Priorität im Active-Array und startet den Prozess am Anfang der entsprechenden verketteten Liste. Diese Auswahl und der Wechsel erfolgt,
Im letztgenannten Fall wird der Prozess in das expired-Array verschoben und
dabei eine neue Zeitscheibe für seinen nächsten Durchlauf berechnet.
Eine Ausnahme bilden hier interaktive Prozesse, die solange im active-Array
neu einsortiert werden, bis alle CPU-Fresser abgearbeitet sind (siehe Latenz
und Prioritäten).
Sobald alle vordefinierten Zeiten im active-Array verbraucht, werden die Zeiger
von active und expired vertauscht und der Zyklus beginnt von Neuem.
Bei Programmstart erhält jeder Prozess eine statische Prioriät auf
einer negativen Skale von -19 bis 20. Default ist 0. Je niedriger der Wert,
desto höher die statische Priorität.
Der Scheduler berechnet während der Laufzeit für jeden Prozess eine
dynamische Priorität im Bereich von -5 bis 5, die zur statischen dazu addiert
wird.
So können interaktive Prozesse (E/A-lastige) belohnt und CPU-Fresser bestraft
werden.
Die Einordnung in diese beiden Kategorien erfolgt durch die mittlere Schlafzeit
eines Prozesses. Die Zeit, die ein Prozess schlafend und wartend verbringt,
wird als Indikator für die dynamische Priorität verwendet. Wartezeit
wird bis zur maximalen mittleren Schlafzeit auf dieselbe addiert und Rechenzeit
von ihr abgezogen. So ergibt sich eine Skala, die linear auf Bereich der dynamischen
Priorität interpoliert werden kann.
Für jeden Prozess wird individuell bestimmt, wieviel Rechenzeit er am
Stück benutzen darf. Dieses Zeitkontigent oder Zeitscheibe wird nach jeden
Ablauf neu berechnet und ist abhängig von der dynamischen Priorität.
Die Zeitscheibe kann zwischen 10 und 200ms lang sein und dauert im Mittel 100ms.
Prozesse mit hoher Priorität bekommen mehr Zeit und Prozesse mit niedriger
Priorität weniger.
Wie bereits erwähnt, erhöhen längere Zeitscheiben die Effizienz
des Gesamtsystems, weil der Scheduler weniger oft laufen muss und weniger Kontext-Wechsel
durchgeführt werden müssen. Generell kürzere Zeiten würden
die Latenz und Interaktivität verbessern, erzeugen aber mehr Overhead.
Die individuelle Berechnung ermöglicht einen guten Kompromiss zwischen
diesen beiden Anforderungen.
Prozesse laufen nicht immer. Besonders interaktive Prozesse verbringen sehr
viel Zeit mit Warten. Während sie auf ein Ereignis warten, dürfen
sie nicht laufen oder verplant werden. Andernfalls müssten sie in einer
Schleife prüfen, ob das Ereignis, auf das sie warten, eingetreten ist.
Stattdessen werden sie in besonderen Warteschlangen geparkt, die einer Ereignisroutine
zugeordnet sind.
Solche Ereignisse können in der Regel Antworten von externen Kanälen
sein (ein Device sendet Interrupt und meldet so neue Daten), Nachrichten von
anderen Prozessen oder die Systemclock sein.
Die entsprechende Ereignisroutine weckt dann die schlafenden Prozesse wieder
auf und schiebt sie zurück in das Active-Array.
Durch diese Interrupts - Unterbrechungen - kann der Scheduler laufende Prozesse
anhalten und die Prioritäten neu prüfen.
Per Interrupt von der uhr wird alle 10ms eine Funktion scheduler_tick() ausgeführt,
die hauptsächlich das Zeitkontingent des aktuell laufenden Prozesse dekrementiert.
Sollte die Zeitscheibe dadurch verbraucht worden sein, wird
Die Hauptroutine schedule() wird ausgeführt,
Zu Beginn wird die preemption deaktiviert, also die Unterbrechbarkeit durch
Interrupts. Dann werden Statistiken des abgelaufenen Prozesses berechnet (Laufzeit,
schlafzeit, ...) und führt andere Aufräumarbeiten in den Listen aus.
Falls das Active-Array leer ist, wird jetzt auf das expired-Array umgeschaltet.
Sollte dadurch kein wartender Prozess gefunden werden, kann in den Runqueues
anderer Prozessoren nachgesehen werden, ob einzelne Prozesse von dort übernommen
werden können
Ist jetzt immer noch kein Prozess zur Ausführung bereit, wird der spezielle
idle() Prozess ausgeführt bis zum nächsten Aufruf von schedule()
Es erfolgt ein Kontext-Wechsel zum neuen Prozess und die preemption wird wieder
aktiviert.
Normalerweise bleiben Prozesse auf ihrem Prozessor um Cache- und Speicherzugriffe zu optimieren. Sollte ein Prozessor jedoch sehr viel mehr zu tun haben, als andere Prozessoren im System, können diese einzelne Prozesse übernehmen. Ein Prozessor mit geringer Auslastung wird dabei immer versuchen Prozessoren mit höherer Auslastung zu entlasten, so können die Prozesse gleichmäßig verteilt werden.