1. Grundlagen
b. Prozesse
Für den Begriff „Prozess“ selber gibt es
verschiedene Definitionen. Generell spricht man bei einem Prozess von einem
Programm in Ausführung. Der Unterschied zu einem Programm liegt unter anderem
im Status, so ist ein Programm statisch, da festgelegt durch den Programmierer,
ein Prozess hingegen ist dynamisch, er kann auch als Abfolge von Aktionen aufgefasst
werden, die zur Laufzeit des Programms festgelegt wird.
Prozessen werden bei der Initialisierung eigene Ressourcen zugewiesen, hierzu
gehören ein Adressraum, also Arbeitsspeicher, sowie der Kontext. Unter
diesem Begriff werden drei verschiedene Ebenen unterschieden:
Der Benutzerkontext umfasst die Daten des Prozesses im zugewiesenen Adressraum,
der Hardwarekontext enthält die Inhalte der Prozessorregister zum Zeitpunkt
der Ausführung. Beim Umschalten zwischen den einzelnen Prozessen im Prozessor
muss dieser Inhalt des Hardwarekontexts zwischengespeichert werden. Als dritte
Ebene wird der Systemkontext genannt. Dieser beinhaltet Informationen, die das
Betriebssystem über den Prozess speichert, so etwa eine Identifikationsnummer,
geöffnete Dateien, Prioritäten, oder statische Daten, wie etwa die
in Anspruch genommene Rechenzeit oder die Leerlaufzeit.
Bedingt durch den Umfang der Verwaltung spricht man auch von schwergewichtigen
Prozessen.
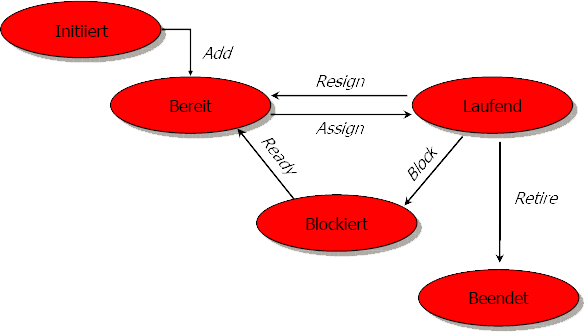
Prozesse befinden sich jeweils in einem bestimmten Status. Eine Übersicht ist im folgenden Bild dargestellt:
Anhand dieser Grafik erkennt man, dass ein Prozess aus einer Menge „Initiiert“ der „Bereitmenge“ hinzugefügt wird. Dieser Prozess wartet dann auf Zuteilung zum Prozessor / Betriebsmittel, diese Zuteilung erfolgt durch die Operation „Assign“. Der Prozess kann das Betriebsmittel über „Resign“ wieder aufgeben und wird wieder der Bereitmenge hinzugefügt. Prozesse können blockiert werden und dadurch einer Wartemenge „Blockiert“ hinzugefügt werden (Operation „Blockiert“). Wenn ein Prozess seine Arbeit beendet hat, wird er durch „Retire“ aus dem aktiven System entfernt.
Eine weitere Unterscheidung auf der Hardwareebene wird vorgenommen
bei der Frage nach der Organisation des Arbeitsspeichers. So gibt es Systeme
mit gemeinsamem Speicher (shared memory system), bei denen ein zentraler Speicher
von mehreren Prozessoren genutzt wird. Wenn jeder Prozessor seinen eigenen,
unabhängigen Speicher benutzt, dann spricht man von einem System mit verteiltem
Speicher (distributed memory system).
In Programmiersprachen findet man sowohl reine Lösungen der ersten Variante,
als auch reine Lösungen der Zweiten, einige Sprachen wie Java unterstützen
auch beide Möglichkeiten.
Bei der Parallelität auf Hardwareebene, als auch bei
paralleler Programmierung ergeben sich zwei Hauptprobleme. Zum einen ist hier
die Synchronisierung der unterschiedlichen Prozessoren, bzw. Prozesse zu nennen.
Dieses Problem tritt auf bei dem Modell des gemeinsam genutzten Speichers, da
die Prozessoren den zentralen Speicher dazu benutzen, ihre Aktivitäten
zu synchronisieren. Dabei muss sichergestellt werden, dass jeder Prozessor exklusiven
Zugriff hat auf den Teil des Speichers, den er verändern will (Problem
des wechselseitigen Ausschlusses / mutual exclusion).
Falls kein gemeinsam genutzter Speicher existiert, besteht das Problem der Prozesskommunikation,
oder auch kurz IPC („interprocess communication“) genannt. Die parallel
bzw. nebenläufig ausgeführten Prozesse müssen sich untereinander
abstimmen oder benötigen Ergebnisse eines anderen Prozesses. Zu diesem
Zweck wurde das Konzept des Nachrichtenaustauschs („message passing“)
eingeführt.
Für den weiteren Verlauf dieser Ausarbeitung
soll der Begriff der Parallelität gleichzusetzen sein mit dem Begriff „nebenläufig“.