Profiling von Java-Code
... [ Top : Thema Performance-Analyse-Werkzeuge für Java ] ...
[ Vorheriges Kapitel : JMeter ] ...
[ Nächstes Kapitel : Fazit ] ...
Übersicht: Profiling von Java-Code
Das JVMPI wurde mit dem JAVA 2 SDK eingeführt und bietet die Möglichkeit zur Performance-Messung
bei Java-Anwendungen. JVMPI ist eine Schnittstelle, die es einem Profiler Agent ermöglicht, die
Java Virtual Machine (VM) zu steuern und umgekehrt der VM ermöglicht, Ereignisse an den
Profiler Agent zu senden. Die VM und der Profiler Agent laufen im selben Prozess.
Durch ein Profiler-Front-End, welcher in einem eigenem Prozess läuft, werden die
Messungsdaten dem Benutzer zur Verfügung gestellt. Die Kommunikation zwischen dem Profiler-Agent
und dem Profiler-Front-End erfolgt auf Basis eines Protokolls, welches zwischen den beiden Teilen
individuell festgelegt werden kann.
Bis zum JDK 1.4 ist die Schnittstelle allerdings noch als experimentell gekennzeichnet.
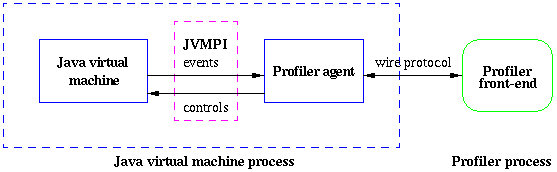
Die Steuerungsmöglichkeiten des Profiler Agent in Hinblick auf die VM beziehen sich dabei
auf die Ereignisse in der VM. So kann der Profiler Agent zur Laufzeit steuern, über welche
Ereignisse er informiert werden will. Dies bietet den Entwicklern von Profiler Agents die Möglichkeit,
nur die für das Problem relevanten Informationen zu erhalten und einen Overhead an Information zu
vermeiden. Weitere Steuerungsmöglichkeiten sind :
- die Steuerung des Garage Collecting (starten, verhindern)
- Threads suspendieren, deren Status und CPU-Zeit ermitteln
- Aufrumbaum eines Threads ermitteln
- Beenden des Profiling
Der Profiler-Agent stellt der VM nur eine Methode zur Verfügung. Diese Methode ermöglicht es der VM
den Profiler-Agent über ein Ereignis zu benachrichtigen.
Die folgenden Ereignisse können unter anderem an den Profiler Agent gesendet werden :
- VM wird initialisiert oder heruntergefahren
- Objekte allokiert, disallokiert, verschoben oder angezeigt werden
- Methoden aufgerufen oder verlassen werden
- Threads gestartet oder beendet werden
- Klassen geladen oder entladen werden
- Garbage Collecting gestartet oder beendet
- Monitorbereich betreten oder verlassen
- Warten auf Eintritt in Monitorbereich
Das Profiler-Front-End erhält vom Profiler-Agent relevante Informationen und verarbeitet sie so,
dass die Benutzer damit weiterarbeiten können (z.B. in Datei ablegen). Das Profiler-Front-End muss
nicht auf dem gleichem Rechner wie die VM laufen, sonder kann aufgrund des unabhängigen Protokolls
auf einem remote-Rechner laufen.
Die Profiler-Agents sind austauschbar bei jedem Programmstart, allerdings kann nur ein Profiler-Agent
pro VM geladen werden, und können nach Schema des folgenden Aufrufes
einer Java-Anwendung festgelegt werden :
java -Xrunmyprofiler ToBeProfiledClass
myprofiler ist dabei, der Name des Profiler-Agents, dessen Library im
vorgesehenen Verzeichnis vorhanden sein muss, bei Windows z.B. müsste es für diesen Fall die Datei
myprofiler.dll im \bin-Verzeichnis des JAVA SDK's geben.
Durch den Aufruf lädt die VM die Profiler-Agent-Library und holt sich durch eine Methode aus der Library
einen Zeiger auf den Profiler-Agent.
Nach oben
hprof ist ein Profiler, der mit dem JDK 2 ausgeliefert wird und die JVMPI zum Zwecke des Profiling von
Java-Anwendungen implementiert. Mit hprof ist es z.B. möglich zu ermitteln, welche Methoden wieviel CPU-Zeit
verbrauchen oder wieviele Instanzen von einer Klasse während eines Programmablaufes instanziert
werden.
Die Steuerung des Programmes kann unter anderem über die folgenden Paramter erfolgen:
- heap=dump|sites|all - default: all - steuert die Art des Speicher-Profiling
- cpu=samples|times|old - default: off - steuert die Art des CPU-Profiling
- format=a|b - default: a - Ausgabeformat der Datei (ascii oder binary)
- file="file" - default: java.hprof(.txt for ascii)
- cutoff="value" - default: 0.001 - Mindestmaß an CPU-Zeit für eine Methode um berücksichtigt zu werden
- depth="size" - default: 4 - Aufzeichnung der Methodenaufrufe bis zur angegebenen Verschachtelungsebene
- doe=y|n - default:y - Dump bei Programmende
Um Zwischenergebnisse, wie z.B. aktuelle Speicherallokation, ausgeben zu lassen, kann dies während des Profiling-Vorgangs mit der
Tastenkombination Ctrl-Pause erzwungen werden.
Beispiel für Ermittlung von CPU-Zeit
Im folgendem Beispiel sollen verschiedene Methoden zur Erzeugung von einem konkatenierten String aus
5000 "more" verglichen werden. Der String wird durch 5000faches iterieren erstellt.
Alle Methoden liefern das gleiche Ergebnis, gelangen aber auf unterschiedlichen
Wegen dort hin.
Eine Möglichkeit besteht darin eine den String durch einen wiederholten Funktionsaufruf
zu erstellen, bei dem zwei String-Objekte konkateniert werden und ein neues String-Objekt als
Ergebnis zugewiesen wird (makeString).
Die zweite Möglichkeit arbeitet wie die erste aber ohne Funktionssaufruf (makeStringInline).
Als dritte möglichkeit wird der String wie bei der zweiten Möglichkeit erstellt, wird aber nicht
jedesmal der globalen Variable zugewiesen sonder erst in einer lokalen Variable gespeichert und
am Schluss erst der globalen Variablen zugewiesen (makeStringWithLocal).
Die vierte Möglichkeit arbeitet mit Objekten vom Typ StringBuffer und nutzt zum Konkatenieren die
append()-Methode (makeStringWithBuffer, um diese Methode messen zu können iteriert sie 10mal mehr
als die anderen drei Möglichkeiten). (Quellcode von TestHprof.java)
Um die CPU-Zeit der einzelnen Methoden oder Programmteile zu ermitteln, ruft man die
Java-Anwendung wie folgt auf:
java -Xrunhprof:cpu=samples,format=a,file=log.txt,cutoff=0 TestHprof
Entscheidend ist hier bei der Parameter "cpu=samples" der den hprof-Profiler veranlasst,
die CPU-Zeit der Methoden zu messen.
Nach Beendigung des Programmes werden die Ergebnisse in die Datei "log.txt" geschrieben.
Folgende wichtige Informationen sind darin enthalten:
Die gestarteten und beendet Threads
...
THREAD START (obj=724b00, id = 3, name="main", group="main")
THREAD START (obj=725040, id = 4, name="HPROF CPU profiler", group="system")
...
THREAD END (id = 3)
Alle vorgekommenen Aufrufbäume von Methoden, die dem cutoff-Paramter nicht widerpsrechen,
werden als Stack-Trace ausgebenen
TRACE 1:
sun.misc.URLClassPath$JarLoader.getJarFile(URLClassPath.java:494)
sun.misc.URLClassPath$JarLoader.(URLClassPath.java:459)
sun.misc.URLClassPath$2.run(URLClassPath.java:255)
java.security.AccessController.doPrivileged(AccessController.java:Native method)
...
TRACE 19:
java.lang.StringBuffer.(StringBuffer.java:115)
java.lang.StringBuffer.(StringBuffer.java:103)
TestHprof.makeStringWithLocal(TestHprof.java:30)
TestHprof.main(TestHprof.java:58)
Die CPU-Zeiten der einzelnen Methoden
CPU SAMPLES BEGIN (total = 266) Sat Oct 12 14:01:33 2002
rank self accum count trace method
1 36.09% 36.09% 96 14 java.lang.StringBuffer.expandCapacity
2 27.07% 63.16% 72 9 java.lang.StringBuffer.expandCapacity
3 26.69% 89.85% 71 11 java.lang.StringBuffer.expandCapacity
4 2.63% 92.48% 7 16 java.lang.StringBuffer.toString
5 2.26% 94.74% 6 10 java.lang.StringBuffer.toString
6 0.75% 95.49% 2 17 TestHprof.makeStringWithLocal
7 0.75% 96.24% 2 13 java.lang.StringBuffer.expandCapacity
8 0.75% 96.99% 2 15 java.lang.StringBuffer.
9 0.38% 97.37% 1 3 sun.misc.URLClassPath$JarLoader.
10 0.38% 97.74% 1 1 sun.misc.URLClassPath$2.run
11 0.38% 98.12% 1 4 java.util.zip.ZipFile.getInputStream
12 0.38% 98.50% 1 6 java.security.AccessController.doPrivileged
13 0.38% 98.87% 1 12 java.lang.StringBuffer.toString
14 0.38% 99.25% 1 2 sun.misc.URLClassPath$JarLoader.getJarFile
15 0.38% 99.62% 1 5 java.util.jar.Manifest.read
16 0.38% 100.00% 1 7 java.security.SecureClassLoader.getPermissions
17 0.00% 100.00% 0 8
CPU SAMPLES END
Leider lässt sich so noch nicht erkennen, welche Methode die effizienteste ist, um einen
langen String durch Konkatenation zu erstellen. CPU-Zeiten von aufgerufenen Methoden wie z.B
"java.lang.StringBuffer.toString" kommen in der Liste mehrfach vor und sind noch keiner der vier
zu testenden Methoden zurechenbar. Dies Zuordnung ist aber möglich über die Stack-Traces, die jedem
einzelnem Eintrag zugeordnet werden können. Zur besseren Visualisiereung gibt es aber das Tool "PerfAnal",
welches die Aufrufbäume mitberücksichtigt.
PerfAnal
PerfAnal analysiert die Ausgabe-Datei von hprof und zeigt die Aufrufbäume mit ihren zugehörigen
CPU-Zeiten. Die Oberfläche von PerfAnal ist in vier Teile gegliedert. Oben links befindet sich
eine aufruferorientierte Sicht in Bezug auf die Methoden wieder, unten links ist die Sicht
des Aufgerufenen, oben rechts ist eine aufruferorientierte Sicht in Bezug auf die Zeilennummer.
In allen drei Teilen wird der Zeitverbrauch der aufgerufenen Methoden den aufrufenden
zugerechnet. Unten links ist eine Auflistung ohne Berücksichtigung von Aufrufern und Aufgerufenen.
Hier ist der reine Zeitverbrauch jeder Methode ersichtlich.
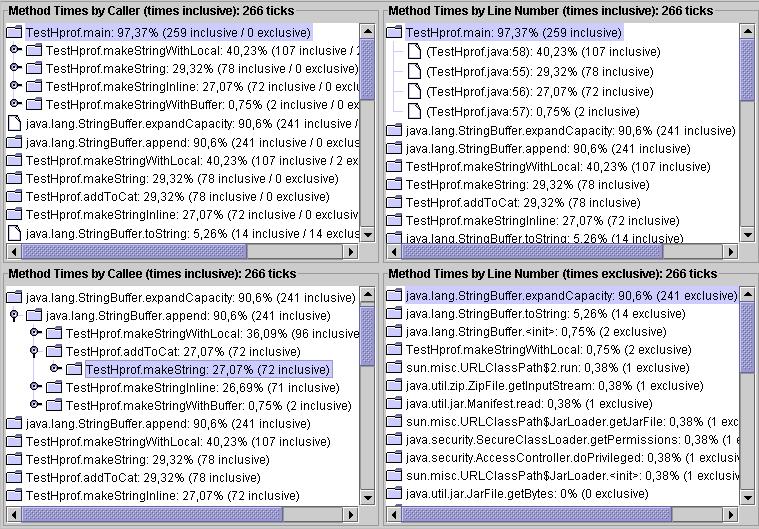
Das obere linke Fenster zeigt deutlich, welche Methode am effizientesten ist. Die Methode
makeStringWithBuffer() ist im Verhältnis etwa 1:100 schneller als die anderen drei Methoden,
wenn man noch berücksichtigt, dass sie das 10fache leistet, um sie überhaupt messbar
zu machen.
Beispiel für Ermittlung von Speicherallokation
Auch zur Ermittlung der Speicherallokation kann hprof als Profiler verwendet werden. Diese Option ist
die Default-Einstellung beim Aufruf. Bei einer expliziten Angabe würde ein Aufruf wie folgt aussehen :
java -Xrunhprof:heap=dump,format=b,file=log TestHprof
Das Format der Ausgabedatei wurde auf binary gesetzt um sie mit dem "Heap Analysis Tool" analysieren zu können.
Die Datei kann aber von dem Tool nur verarbeitet werden, wenn zum Programmlauf das JDK 1.2 benutzt wird. Unter
1.3 und 1.4 trat bei der Analyse eine IO-Exception auf.
Heap Analysis Tool
Das Heap Analysis Tool verarbeitet die Informationen aus der Datei "log" und stellt sie mittels eines Web-Servers
(Default-Port ist 7000) zur Verfügung.
Neben der Anzahl, wie oft eine Instanz einer Klasse erzeugt wurde, lässt sich auch für jede Instanz ersehen,
von welcher Methode sie allokiert wurde und auf welche Objekte sie Referenzen hat, von welchem
Objekt sie referenziert wird und welche Werte die Instanz enthält. Bei Speicheranalysen ist aber stets
das Garbage Collecting zu beachten. Dies kann die Aussagekraft einer Speicheranalyse deutlich verzerren.
Beispiel für Instanzenzählung
852 instances of class [C
851 instances of class java.lang.String
528 instances of class java.util.Hashtable$Entry
220 instances of class java.lang.Class
22 instances of class java.util.Locale
...
Beispiel für Instanz
Class:
class java.lang.String
Instance data members:
count (I) : 20000
offset (I) : 0
value (L) : "moremore...moremore"@0xa0288800 (79988 bytes)
Object allocated from:
java.lang.StringBuffer.toString(()Ljava/lang/String;) : StringBuffer.java line (compiled method)
TestHprof.makeStringWithLocal(()V) : TestHprof.java line (compiled method)
TestHprof.main(([Ljava/lang/String;)V) : TestHprof.java line 63
References to this object:
class TestHprof@0xf02b8700 (0 bytes) : static field cat
Nach oben
>Optimizeit
Die Optimizeit Suite wird von der Firma Borland vertrieben und besteht aus 3 Bestandteilen:
- Optimizeit Profiler
- Optimizeit Code Coverage
- Optimizeit Thread Debugger
Optimizeit Profiler
Der Profiler besteht dabei aus einem Profiler-Agent, der mit dem JVMPI arbeitet, und einer Profiler-Front-End.
Neben einer CPU-Messung für die einzelnen Methoden und einer kontinuierlichen Speicheransicht bietet das Front-End
auch nähere Informationen zur VM.
Die CPU-Messung kann während des Programmlaufes gestartet und gestoppt werden. Nach Beendigung der Messung kann man
an Hand eines Aufrufbaumes erkennen, wie viel Zeit absolut und relativ in den einzelnen Methoden verbraucht wurde.
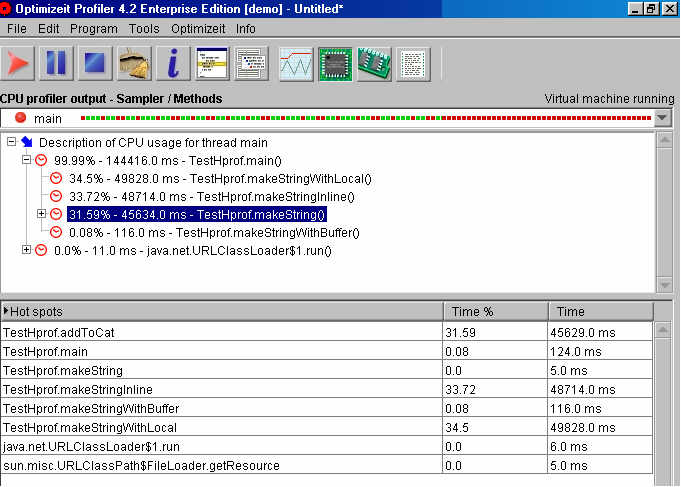
Während des Testlaufes wird in der Speicheransicht eine ständig aktualisierte Liste der allokierten Objekte zur
Verfügung gestellt. Diese Ansicht bietet auch die Möglichkeit den Garbage Collector auszuschalten, um so die
Anzahl aller jemals allokierten Objekte zu ermitteln. Auch ist es möglich die Differenzen an Instanzen zu einem
Zeitpunkt während des Testlaufes anzuzeigen.
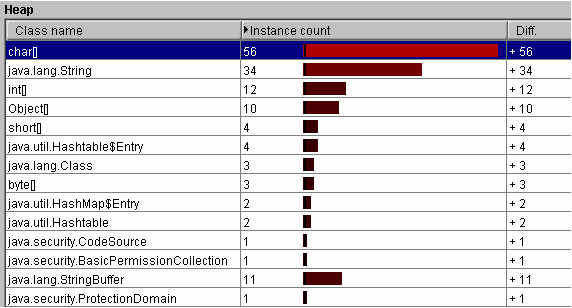
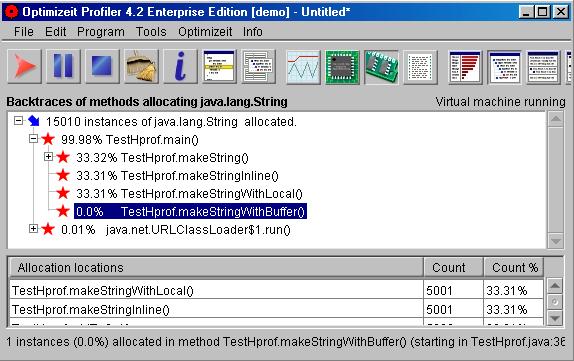
Optimizeit Profiler bietet auch die Möglichkeit, eine Auflistung, welche Methoden wieviel Instanzen von einer Klasse
erzeugen, zu machen.
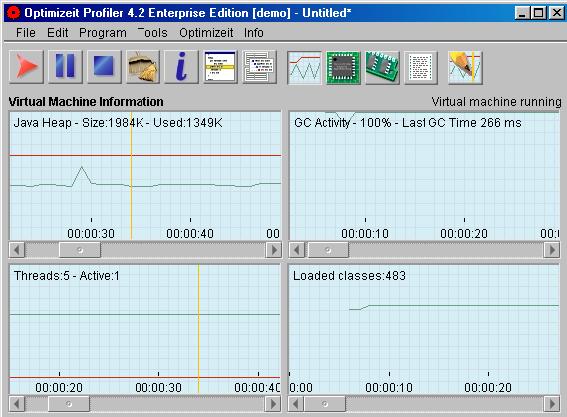
An Informationen zur VM bietet Optimizeit an, wieviel Speicher im Verlauf des Testes belegt wurden ist,
wann der Garbage Collector aktiv gewesen ist, wieviele Threads gelaufen sind und wieviele Klassen geladen wurden sind.
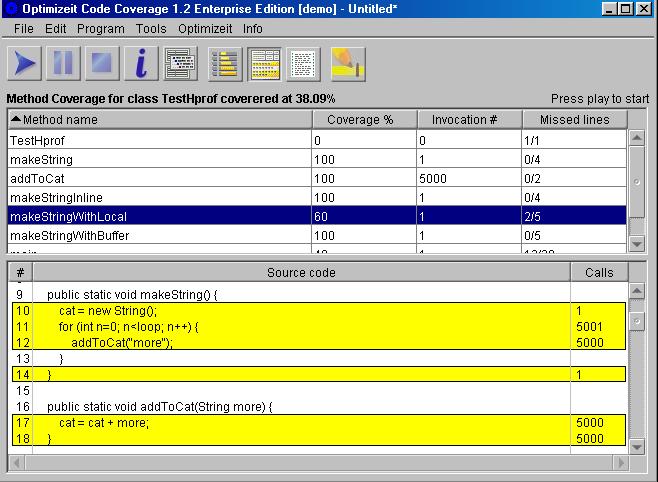
Optimizeit Code Coverage
Code Coverage ist ein Tool um sehen, welche Statements im Java-Code wie oft durchlaufen werden. Dies bietet die
Möglichkeit, zu erkennen, wo eventuell Funktionen zu oft aufgerufen werden oder Code liegt, der nicht mehr benötigt wird.
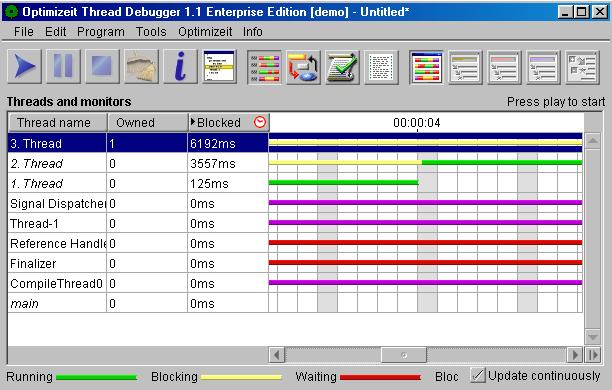
Optimizeit Thread Debugger
Der Thread Debugger bietet die Möglichkeit die Abhängigkeiten von Threads zu analysieren. Durch Testläufe kann aufgezeigt,
wie oft und von wem ein Thread blockiert wird. Der Thread-Debugger ist auch in der Lage Deadlock-Situationen zu erkennen.
... [ Top : Thema Performance-Analyse-Werkzeuge für Java ] ...
[ Vorheriges Kapitel : JMeter ] ...
[ Nächstes Kapitel : Fazit ] ...