



Wenn mal einmal von der philosophischen Frage absieht, drehen sich die Unterschiede zwischen einem Cluster und einem "normalen" Netzwerk von Workstations im wesentlichen um folgende fünf Punkte: Sicherheitsaspekte, Applikationen, Administration, Boot-Vorgang, File-System.
Ausgeliefert und installiert haben die meisten Linux-Distributionen ein hohes Sicherheitsniveau, und das auch aus gutem Grund. Diese sehr hohe Sicherheit ist jedoch dem "normalen" Gebrauch eines Clusters im Weg. Auf die Details wird weiter unten noch eingegangen.
Anwendungen nutzen als Basis sogenannte Message Passing Systeme wie MPI oder PVM. Es gibt zwar viele Wege, um Parallelität umzusetzen, aber Message Passing ist sehr populär und passend für die meisten Fälle.
Generell ist aber folgendes zu sagen: Außer eine Anwendung wurde speziell für den Einsatz in einer Cluster Umgebung entwickelt, wird sie immer nur auf einer CPU laufen. Man kann keinen Apache- oder MySQL-Server nehmen und sie über mehrere CPUs in einem Cluster laufen lassen, außer es werden spezielle Parallele Source Code Versionen entwickelt und eingesetzt.
Glücklicherweise gibt es diverse Tools, um die Administration eines Clusters zu erleichtern. Zum Beispiel wird es nicht wirklich die Erfüllung sein, 32 Nodes in einem Cluster neu zu starten, falls dies nötig sein sollte. Jedoch bedeutet die Administration eines Clusters auch Abstriche in der Sicherheit zu machen. Zum Beispiel ist es sehr wertvoll in einem Cluster, sich auf jedem Node als root per rlogin anmleden zu können. In einem offenen Netzwerk wäre dies jedoch ein fatales Sicherheitsloch.
Es gibt diverse Möglichkeiten, ein einem Cluster die Nodes zu booten. Die einfachste ist natürlich der Boot von der lokalen Festplatte. Aber auch das Disk-Less Booting vom Host Node ist eine ansprechende Alternative, erfordert aber wesentlich mehr fortgeschrittene Konfigruation. Booten von einem BootProm wollen wir hier einmal außen vor lassen.
Zu guter Letzt das Dateisystem: Für die vernünftige Arbeit an einem Cluster ist zumindest der /home Pfad für den kompletten Cluster per NFS zu verteilen.
Exemplarisch betrachten wir einmal den Aufbau eines Clusters mit 4 Nodes. Dazu besorgt man sich 4 identische PC "von der Stange", jeweils eine schnelle Netzwerkkarte, die am besten auch Duplex-Fähigkeit besitzt, eine Netzwerkkarte extra und einen schnellen Switch. Für einen der Nodes wird man wohl auch noch Tastatur, Monitor und Maus benötigen.
|
|
|
|
|
|
|
|
|
|
|
|
|||
Diese Rechner werden in einem Netzwerk miteinander durch den Switch verbunden,
wobei einer der vier PCs mit den zwei NIC's als Gateway zum restlichen LAN dient:
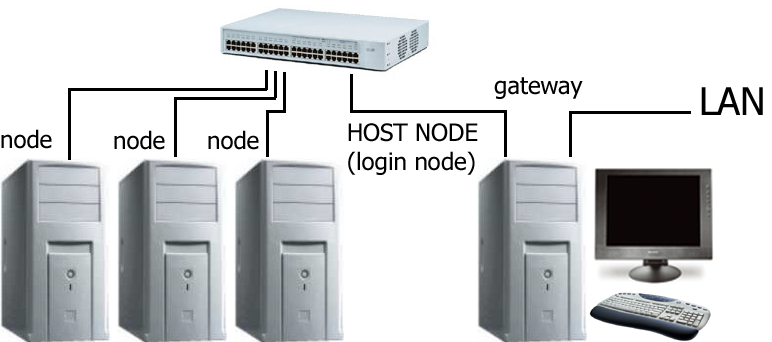
Als erstes wird der Host-Node als Gateway eingerichtet. Dazu bekommt eine Netzwerkkarte, die an das externe Netz angeschlossen ist, eine IP aus diesem Netz, die andere, die an den Switch des Cluster angeschlossen ist, eine IP des Clusters. Damit ist dem Cluster der Zugang nach außen und anderen der Zugang zum Cluster möglich. Die Gateway Konfigruation erfolgt in der Routing-Tabelle:
markus@mbs001:~ > /sbin/route Kernel IP routing table Destination Gateway Genmask ... Use Iface 10.0.0.0 * 255.255.255.0 ... 0 eth1 192.168.0.0 * 255.255.255.0 ... 0 eth0 127.0.0.0 * 255.0.0.0 ... 0 lo default 192.168.0.1 0.0.0.0 ... 0 eth0
Desweiteren müssen sich die Nodes im Cluster natürlich untereinander beim Namen kennen, d.h. man setzt im Cluster entweder einen DNS Server ein, oder man wählt die einfachere Variante von host-Dateien. Diese sehen dann so aus und müssen auf jedem Rechner im /etc Verzeichnis vorhanden sein:
markus@mbs001:~ > cat /etc/hosts 192.168.0.2 mbs001.m-bader.de mbs001 10.0.0.1 node1.m-bader.de node1 10.0.0.2 node2.m-bader.de node2 10.0.0.3 node3.m-bader.de node3 10.0.0.4 node4.m-bader.de node4
Die folgenden Sicherheitslöcher sind nur auf den Nodes im Cluster zu schaffen, die keine Verbindung zur Außenwelt (außer natürlich über das Gateway) haben. Auf dem Gateway ist höchste Sicherheit erforderlich.
Als erstes wird in der Datei /etc/hosts.deny erst einmal generell alles verboten:
markus@mbs001:~ > cat /etc/hosts.deny # See tcpd(8) and hosts_access(5) for a description. ALL: ALL: spawn ( \ echo -e "\n\ TCP Wrappers\: Connection Refused\n\ By\: $(uname -n)\n\ Process\: %d (pid %p)\n\ User\: %u\n\ Host\: %c\n\ Date\: $(date)\n\ " | /bin/mail -s "From tcpd@$(uname -n). %u@%h -> %d" root)
Um wieder etwas Lust zu bekommen, vertrauen wir allen Nodes im Cluster. Dies wird in der Datei /etc/hosts.allow eingetragen:
markus@mbs001:~ > cat /etc/hosts.allow # we fully trust ourself and all the other # nodes within the cluster ALL : localhost, 10.0.0. in.telnetd : scouter.m-bader.de
Um die Ausfürung von Programmen per rsh zu ermöglichen, passen wir die Datei /etc/hosts.equiv an:
markus@mbs001:~ > cat /etc/hosts.equiv # # hosts.equiv # This file describes the names of the # hosts which are to be considered # "equivalent", i.e. which are to be # trusted enought for allowing rsh(1) commands. # # must be read/writable by user only! node1 node2 node3 node4
Neben diesen Punkten sollte man noch den rlogin-, den telnet- und den ftp-Zugriff für root auf allen Nodes erlauben.
Für die Programmierung auf Clustern braucht man nicht unbedingt parallele Software. Aber einfach und zur Zeit weit verbreitet sind sogenannte Message Passing Systeme. Die beiden populärsten Vertreter zu Zeit sind MPI (Message Passing Interface) und PVM (Parallel Virtual Machine)
PVM ist älter und wurde seiner Zeit für Netzwerke von Workstations entwickelt. Bis heute wurde PVM auf viele parallele Supercomputer portiert. Die Kontrolle über PVM liegt allein bei den Autoren. PVM ist einfach zu installieren und mit wenig Aufwand zu konfigurieren. PVM bietet auf Grund seiner Virtuellen Maschine sehr gute Unterstützung für heterogene Netzwerke.
MPI ist ein Standard, der inzwischen von vielen Hardware Herstellern von paralleler Hardware unterstützt wird. Dieser Standard bietet mehr Funktionalität als PVM. Die Kontrolle über MPI liegt beim MPI-Standard Kommittee. MPI ist besser geeignet für homogene Cluster.
Für den exemplarischen Einsatz und die Beschreibung der Funktionsweise von Cluster werde ich mich hier auf PVM konzentrieren.
PVM3 liegt aktuell in der Version 3.4 vor und ist in den meisten aktuellen Linux-Distributionen (Suse 7.1, Mandrake 8.1) enthalten. Die Installation von PVM gestaltet sich als relativ einfach:
$HOME/pvm3/bin/LINUX$PVM_ROOT erzeugen:
PVM_ROOT="/usr/share/pvm3" export PVM_ROOT
[markus@HHCS015 markus]$ pvm pvm>
pvm> conf
conf
1 host, 1 data format
HOST DTID ARCH SPEED DSIG
HHCS015 40000 LINUX 1000 0x00408841
pvm>
pvm> halt halt Beendet [markus@HHCS015 markus]$
Damit ist die Virtuelle Maschine auf jedem Node des Clusters zumindest installiert.
Wie nun alle Nodes zu einer Virtuellen Maschine gemacht werden, wird später
noch deutlich.