modutils ist nicht mehr möglich.__module_kernel_version, das von insmod gegen die Versionsnummer des Kernels geprüft wird. Ist <linux/module.h> über ein Include eingebunden, wird das Symbol vom Compiler definiert.
#if LINUX_VERSION_CODE < KERNEL_VERSION(2,4,0)
alte Version
#else
neue Version
#endifinsmod, rmmod entlädt das Modul wieder.
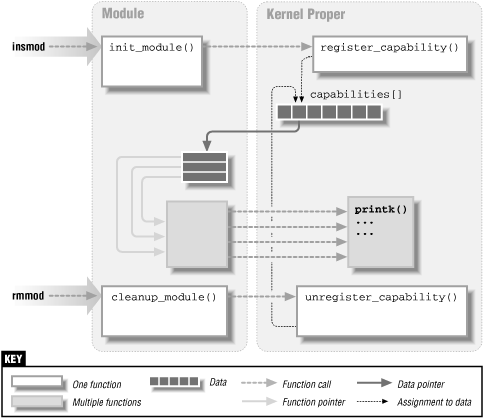
Beim Laden eines Moduls per insmod wird automatisch init_module() aufgerufen, eine vom Modul zur Verfügung gestellte Initialisierungsfunktion.
Das Modul kann sich jetzt als Treiber beim Betriebssystem registrieren.
Es ist auch möglich, Parameter zu übergeben, z.B. IO-Adressen, Interrupts oder eine bestimmte Betriebsart.
Beim Entladen per rmmod wird cleanup_module() aufgerufen. Danach sollte ein Treiber noch aufräumen und alloziierte Ressourcen freigeben.
Welche Module gerade im Kernel geladen sind, kann man sich über lsmod anzeigen lassen.
Folgender Code stellt ein einfaches Modul dar, das nichts spektakuläres macht:
#include <linux/fs.h>
#include <linux/version.h>
#include <linux/module.h>
static int init_module(void)
{
printk("<1>init_module called\n");
return 0;
}
static void cleanup_module(void)
{
printk("<1>cleanup_module called\n");
}
printk ist im Kernel definiert und verhält sich ähnlich wie printf. Der Kernel braucht eine eigene Funktion, weil er ohne die C-Library auskommen muß. Das Modul kann die Funktion aufrufen, weil es durch das Linken alle public symbols des Kernels benutzen kann.
<1> stellt die Prorität der Meldung dar. Je kleiner die Zahl, desto höher die Priorität. Der Default-Wert führt u.U. dazu, dass die Meldung nicht auf der Konsole angezeigt wird.
Speichert man diesen Code unter mod.c und kompiliert diesen mit gcc -O -DMODULE -D__KERNEL__ -Wall -I/usr/src/linux/include -c mod.c, kann man das Modul laden und entladen. Das sieht ungefähr so aus:
root#gcc -O -DMODULE -D__KERNEL__ -Wall -I/usr/src/linux/include -c mod.c
root#insmod mod.o
init_module called
root#rmmod mod.o
cleanup_module called
root#
printk sieht man nur auf einer Textkonsole, benutzt man z.B. ein xterm, geht die Ausgabe je nach Konfiguration von syslogd in die System-Logfiles wie /var/log/messages.
Damit man diesen Code auch für einen Kerneltreiber benutzen kann, braucht man ein paar Änderungen.
#include <linux/fs.h>
#include <linux/version.h>
#include <linux/module.h>
#include <linux/init.h>
static int __init ModInit(void)
{
printk(''init_module called\n'');
return 0;
}
static void __exit ModExit(void)
{
printk(''cleanup_module called\n'');
}
module_init( ModInit );
module_exit( ModExit );module_init und module_exit sind in linux/init.h definiert. Wird der Code als Modul kompiliert, expandieren die Makros zu init_module. Ansonsten expandieren ModInit und ModExit so, dass sie beim Hoch- bzw. Runterfahren des Kernels aufgerufen werden.
Das Attribut __init sorgt dafür, dass die Initialisierungsfunktion 'weggeworfen' wird und ihr Speicherplatz wieder freigegeben wird, wenn die Initialisierung abgeschlossen ist.
__exit bewirkt, dass die so markierte Funktion ausgelassen wird.
Beide haben in Modulen keine Auswirkungen.
Das Generieren eines Moduls mit Hilfe eines Makefiles könnte so aussehen:
CFLAGS=-O -DMODULE -D__KERNEL__ -Wall -I/usr/src/linux/include
all: mod.o
mod.o: mod.c
$(CC) $(CFLAGS) -c mod.c
clean: rm -f *~ mod.o
Noch ein Wort um Kernel Symbol Table. Die Tabelle enthält die Adresse globaler Kernel Items - Funktionen und Variablen -, die man zur Implementation von Treibermodulen braucht. Man kann die Tabelle in /proc/ksyms anschauen. Beim Laden eines Moduls wird jedes exportierte Symbol Teil dieser Tabelle.
asm/io.h definierten Makros readb, readw, readl, writeb, writew und writel.
Um z.B. ein einzelnes Byte zu lesen, benutzt man readb. Auf einer PC-Plattform wird der Zugriff zu einer normalen Zuweisung expandiert. memset_io,
memcpy_fromio, memcpy_toio, die letzlich auf memcpy und memset abgebildet werden.
inb, inw, inl, outb, outw, outl), Makros für einen verlangsamten Zugriff, die nach dem Zugriff eine Pause einfügen (inb_p, inw_p, inl_p, outb_p, outw_p, outl_p) und Makros für den wiederholten Zugriff auf IO-Ports (String-Funktionen) (insb, insw, insl, outsb, outsw, outsl).
check_region: überprüft einen IO-Bereich, ob er noch zur Verfügung stehtrequest_region: reserviert einen IO-Bereichrelease_region: gibt den Bereich freicheck_mem_region: prüft einen Speicherbereich auf Verfügbarkeitrequest_mem_region: reserviert einen Speicherbereichrelease_mem_region: gibt Speicherbereich frei
request_irq: fordert einen Interrupt anfree_irq: gibt die durch die Parameter spezifizierte Ressource frei
#include <linux/ioport.h>
#include <linux/errno.h>
static int my_detect(unsigned int port,unsigned int range){
int err;
if ((err=check_region(port,range))<0)return err;/*busy */
if (my_probe_hw(port,range)!=0)return -ENODEV;/*not found */
request_region(port,range,"skull");/*"Can ’t fail"*/
return 0;
}
static void my_release(unsigned int port,unsigned int range){
release_region(port,range);
}my_probe_hw wird hier nicht angegeben, da diese Funktion geräteabhängig ist. Die Reservierung sollte niemals scheitern, weil der Kernel nur ein Modul zur Zeit lädt. Es ist daher eigentlich unmöglich, dass andere Module zwischenzeitlich die angeforderten Ports belegen.
Außerdem existieren diverse Makros wie das bereits erwähnte __init und __exit.
copy_from_user( unsigned long to, unsigned long from, unsigned long len) und copy_to_user( unsigned long to, unsigned long from, unsigned long len) zur Verfügung. Die Funktionen überprüfen, ob der Zugriff auf die jeweiligen Speicheradressen erlaubt ist. Sie liefern als Resultat die Anzahl der Bytes, die NICHT kopiert wurden. Kommt also ein Wert grösser Null zurück, gab es einen Fehler. Der Treiber sollte dann -EFAULT zurückliefern.