Abbildung 5: XML Seite ist XSP Seite
Im folgenden werden die Techniken, die Cocoon nutzt, kurz erklärt.
XML
Eine Syntax für hierarchische Dokumente und zum Strukturieren von Informationen bzw. Dokumenten (im Gegensatz
zu HTML, welches für die Präsentation von Informationen konzipiert wurde).
XSLT
Eine Sprache – also eine XML Document Type Definition (DTD) – zum transformieren von XML in ein beliebiges Zielformat.
XSL:FO
XSL:Formating Objects ist ebenfalls eine Sprache, um 2D Layout von Text zu beschreiben. Dabei ist es egal,
ob es sich um Printmedien wie z.B. einen Drucker oder Digitalmedien wie PDF’s handelt.
XSP – eXtensible Server Pages
XSP ist eine DTD zur Trennung von Inhalt & Logik und hat somit eine ähnliche Aufgabe wie XSL, dass zur Trennung
von Inhalt & Layout verwendet wird.
Eine XSP Seite ist kompilierter Code und somit entsteht bei der Anfrage eines Clients kein zusätzlicher Aufwand
in Form von parsen oder interpretieren.
Eine XSP Seite ist ein XML Dokument mit dynamischem Inhalt. Diese Dynamik wird durch Direktiven erzielt, die in Tags gesetzt werden. Direktiven, also Anweisungen, werden entweder aus vor- oder aus anwenderdefinierten Bibliotheken entnommen.
Wichtige XSP Tags:
<xsp:page language=“java“ xmlns=http://www.apache.org/1999/XSP/Core/ >
<xsp:logic>
String formatDate(Date d, String muster) {
return (new SimpleDateFormat(muster)).format(d);
}
</xsp:logic>
In diesem Beispiel wird eine Funktion formatDate definiert, die als Parameter ein Datumsobjekt d
und einen String muster erwartet und dann mittels der java.text Funktion SimpleDateFormat
das aktuelle Datum nach dem gewünschten Muster transformiert.Aktuelle Zeit und Datum: <xsp:expr> formatDate(new Date(), “HH:mm dd.MM.yyyy”) </xsp:expr>Die Funktion formatDate liefert einen String der Form 11:00 01.12.2000 zurück und dieser String wird ein neues Blatt im XML Baum.
Kombination XML & XSP
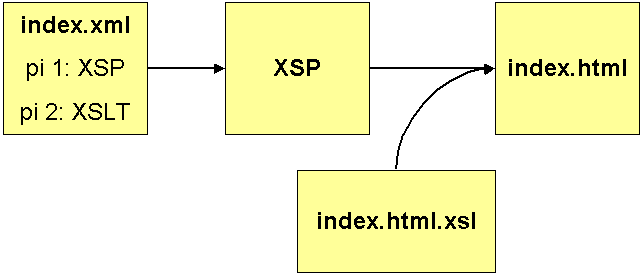
Es gibt zwei Möglichkeiten, XSP Seiten zu erstellen. Die erste ist, den XSP Code in ein normales XML
Dokument einzufügen (in Abbildung 5 das index.xml Dokument).
Abbildung 5: XML Seite ist XSP Seite
Diese index.xml beinhaltet nun zwei Processing Instructions (pi): Instruktion Nr.1 ist die geforderte Verarbeitung als XSP Seite („XSP“ Kasten). Der von der XSP Seite gelieferte Output soll dann – gefordert durch die 2. Instruktion – von einem Stylesheet bearbeitet werden, nämlich von index.html.xsl. Das Resultat ist dann ein Dokument index.html, welches an den Client geschickt wird.
Dem aufmerksamen Leser fällt auf, dass in dieser Verarbeitungskette nicht die Vorteile genutzt werden, die XSP mit sich bringt: es wird nicht der Inhalt von der Programmierlogik getrennt. Beides ist in dem index.xml Dokument hinterlegt.
Um sinnvoll mit XSP zu arbeiten, sollte man die zweite Möglichkeit der Implementierung nutzen. Bei dem Ansatz, der in Abbildung 6 zu erkennen ist, wird der Inhalt strikt von Logik und Layout getrennt.
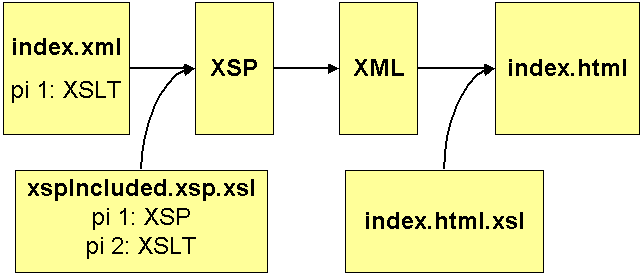
Abbildung 6: XSP Seite wird aus XML Seite erstellt
In der index.xml ist nun neben dem (redaktionellen) Inhalt nur noch eine pi vorhanden, nämlich die Instruktion, dieses XML Dokument mit einem XSL Stylesheet zu bearbeiten. In diesem Stylesheet – hier xspIncluded.xsp.xsl – ist nur XSP Code vorhanden, der in den Dokumentenkopf von index.xml (bzw. dessen DOM’s) eingesetzt wird. Des weiteren hat dieses Stylesheet zwei pi’s: die erste pi zur Erstellung einer XSP Seite und die zweite pi zum Anwenden eines zweiten XSL Stylesheets.
Die Kombination aus index.xml und xspIncluded.xsp.xsl ergibt also eine XSP Seite, die wie ein XML Dokument behandelt wird und auf welches dann ein zweites Stylesheet – index.html.xsl – angewendet wird, um den Output als XHTML zu formatieren.
In dieser Verarbeitungskette kann XSP seine Stärke demonstrieren, nämlich die Trennung von Inhalt und Logik.
Cocoon ist ein Servlet aus mehreren Komponenten, bzw. „Unter-Servlets“. Diese Architektur wird von den Autoren als Reactor Pattern, einem Reaktor Konzept betitelt.
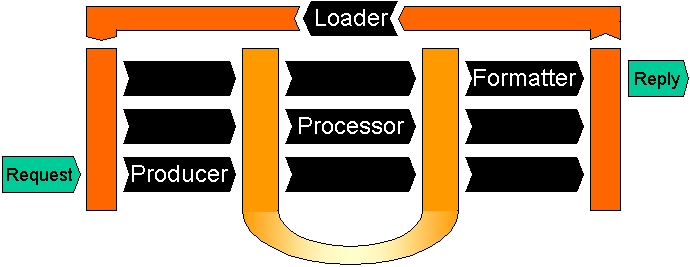
Abbildung 7: Architektur des Cocoon Servlets
Das Framework, dass Cocoon zur Verfügung stellt, wird in Abbildung 7 beschrieben. Alle orange/gelben Bereiche sind eben dieses Framework und die Blackboxen sind Komponenten, die in Cocoon standardmäßig implementiert sind und vom Anwender mit minimalem Aufwand durch eigene Komponenten ersetzt werden können.
Um die Architektur besser zu verstehen, wird nun der Weg eines Dokumentes (oder besser: dessen DOM Abbild) durch
das Cocoon Servlet von der Anfrage bis zur Antwort an den Client im Detail beschrieben.
Nach diesem Einblick in die Architektur des Cocoon Servlets stellt sich die Frage, warum sich der Hauptautor Stefano Mazzocchi für Java als Programmiersprache entschieden hat.
Wichtig war für ihn der Portabilitätsaspekt, den Java mit sich bringt und die mächtigen objektorientierten Eigenschaften dieser Sprache. Sicherlich spielte auch der Fakt, dass alle Tools die Cocoon nutzt, ebenfalls in Java geschrieben sind (z.B. der XML Parser Xerces-J).
Neben der Frage „Warum Java“ soll auch geklärt werden, warum Cocoon als ein Servlet und nicht beispielsweise einfach als mod_cocoon für den Apache httpd direkt vorliegt.
Auch hier war natürlich die Portabilität von Servlets wichtig. Cocoon läuft derzeit (Dezember 2000) auf ca. 60 verschiedenen Umgebungen aus Betriebssystem, Webserver und Servletengine und natürlich ist ein Servlet die naheliegende Lösung, wenn Java als Programmiersprache verwendet wird.
Wie man sich leicht vorstellen kann, ist der Weg des DOM’s durch das Servlet (siehe „Das Cocoon Servlet: Abbildung 7“) resourcenintensiv und daher wird ein effektiver Cache benötigt.
Wenn ein Request von einem Client Cocoon erreicht, wird geprüft, ob der Output des verlangten XML Dokumentes im Cache liegt. Ist dies der Fall, und die Quelldateien (XML Dokumente, XSL Stylesheets) sind unverändert, so wird die gecachte Datei an den Client geschickt.
Wurde allerdings an einer Quelldatei ein Änderung vorgenommen, wird weiter vorgegangen, als wenn der Output nicht im Cache liegen würde, d.h.: das XML Dokument wird normal verarbeitet, dann an den Client geschickt und schließlich wird es im Cache gespeichert.