Aufbau
Die Cloud Haskell Architektur ist wie in der folgenden Darstellung zu sehen aufgebaut:
Ein Cloud Haskell Prozess kommuniziert mit anderen Prozessen über das "network transport interface", welches die Schnittstelle zwischen der Netzwerkschicht und dem Prozess Layer repräsentiert. Durch diese Abstraktion ist eine einfache Integration von unterschiedlichen Netzwerkarten möglich.
Network transport layer
Zum jetzigen Zeitpunkt existiert lediglich eine Implementation für einfache TCP/IP Kommunikation. Weitere Arten befinden sich jedoch bereits in Arbeit. Aufbauend auf den "network transport interface" Implementationen bestehen sogenannte generische "Cloud Haskell backends", über welche sich vereinfacht Backends erstellen lassen. Momentan existieren zwei solcher Backends, das SimpleLocalNet, das ohne größere Konfiguration ein Cluster auf der lokalen Maschine oder dem lokalen Netzwerk bereitstellt und das Azure Backend, welches es ermöglicht Cloud Haskell Applikationen auf virtuellen Maschinen von Microsoft Azure Infrastruktur auszuführen.
Process Layer
Betrachtet man den Prozess Layer, so verwaltet jede Node eine Menge von Prozessen, wobei jeder Prozess wiederum in einem Haskell Thread abläuft und über die zu jedem Prozess zugehörige Message Queue entkoppelt kommuniziert. Pro Node werden zusätzlich noch ein Thread für eintreffende Events und ein Thread für den Node Controller erstellt. Der Thread für eintreffende Events ist dabei z. B. dafür zuständig, die eingehenden Nachrichten an die zugehörigen Prozesse weiterzuleiten oder um sich etwa auf Fehler auf Netzwerkebene wie Node disconnects zu kümmern. Der Node Controller ist z. B. für das spawnen, linken und monitoring von Prozessen zuständig und verwaltet eine Prozess Registratur, über welche Zuordnungen von symbolischen Namen zu tatsächlichen PID's erfolgt. Es bestehen aber auch noch weitere Prozesse per Node, wie etwa einem Logging Prozess.
Backend Implementation - SimpleLocalNet
Im weiteren Verlauf dieser Ausarbeitung wird sich dabei auf das SimpleLocalNet bezogen, um sich bei den Beispielen auf die wesentliche Funktionalität zu konzentrieren.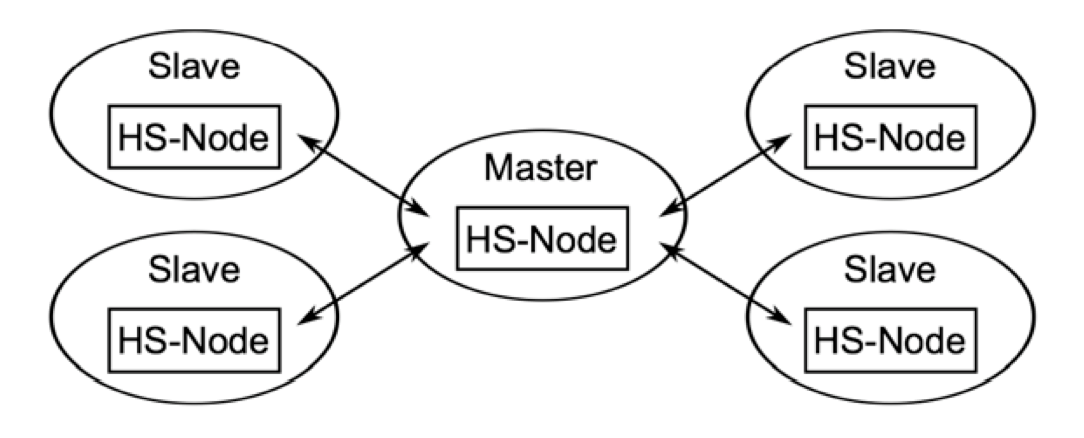
Die einfachste mögliche Konfiguration stellt dabei die Master/Slave Variante dar. Es lassen sich hierfür z. B. mehrere Slaves mit unterschiedlichen Ports auf der lokalen Maschine starten. Diese gestarteten Slaves können dann automatisch durch einen lokalen UPD Multicast entdeckt und anschließend vom Master aus gesteuert werden.