Schlüssel Elemente
... [ Seminar Programmiersprachen und virtuelle Maschinen ] ... [ Google's V8 ] ...
[ << Einführung ] ... [ Kürzliche Entwicklungen >> ] ...
Übersicht: Schlüssel Elemente
Speicher Modell der V8
Das Speicher Modell der V8 arbeitet mit 32 Bit tagged Pointer. Tagged Pointer werden in VMs häufig benutzt, um Zeiger zu kennzeichnen. In der V8 erfolgt dies direkt im Datenwort.
Außerdem bestehen die Datenworte 4 aligned Byte. Dadurch werden nur Vielfache von 4 als Adresse genutzt und somit sind die letzten 2 Bits frei zum taggen. 31 Bit vorzeichenbehaftete Integer
werden in der V8 durch die Tags von Zeigern unterschieden.
Ein Integer sieht wie folgt aus: XXXX...XXX0. (X ist hierbei beliebig)
Ein Zeiger sieht dann so aus: XXXX....XX01.
Damit sind gerade Datenworte automatisch Integer und müssen nur noch um 1 Bit nach rechts geshiftet werden. Zeiger sind ungerade und werden noch mit 1 subtrahiert, um die tatsächliche
Adresse zu erhalten. Dies bringt einen enormen Geschwindigkeitsvorteil.
In der V8 gibt es für jedes Objekt 3 Datenworte. Zunächst ein Zeiger auf eine Hidden Class, ein Zeiger auf Attribute die durch Namen wie
'x', 'y' und 'z' gekennzeichnet sind, sowie einen Zeiger auf Elemente, die durch Zahlen benannt sind. Für die letzten Beiden gibt es 2 Zustände. Im schnellen Fall zeigt der Zeiger auf
ein Array, im Langsamen auf ein Dictionary bzw. eine Hashmap.
Hidden Classes und Hidden Class Transitions
Das Ziel von Hidden Classes ist es JavaScript statisch und klassenbasiert, wie Java oder C++, zu realisieren. In Java oder C++ ist das Layout der Objekte zur Kompilezeit bekannt, Eigenschaften
und Methoden können einfach referenziert werden, da sie immer an der gleichen Stelle gespeichert sind. Bei JavaScript gibt es keine Klassen und es muss immer ein dynamischer Lookup gemacht werden, der
im Objekt und dessen Prototypen-Kette nach dem Attribut oder der Methode sucht.
Die Hidden Classes sollen nun die Möglichkeit geben, bekannte Techniken aus statisch, klassenbasierten Sprachen zu nutzen und Objekte mit gleicher Struktur zu gruppieren. Der Benutzer soll
davon allerdings nichts merken.
Wie funktionieren Hidden Classes?
Zunächst einmal ein kleines Codestück:
1 function Punkt(x, y){
2 this.x = x;
3 this.y = y;
4 }
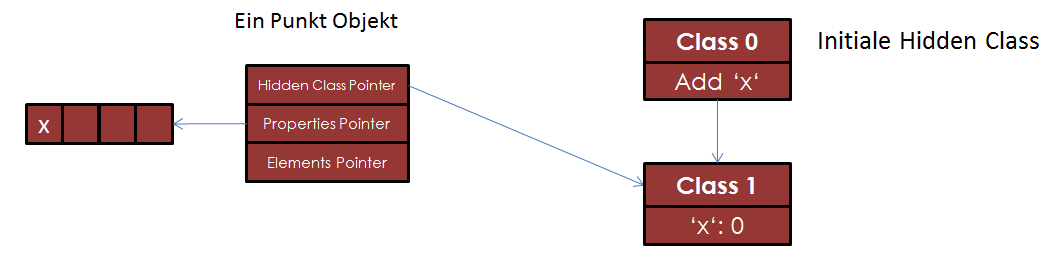
Für ein Punktobjekt gibt es nun immer 3 Datenworte. Zunächst ein Zeiger auf die initiale Klasse Class 0. Und 2 Zeiger für die Attribute des Objekts, die auf zwei
kleine Speicherbereiche verweisen. (In diesem Fall nur der für die Attribute eingezeichnet)

Nach dem Ausführen von this.x = x entsteht eine Kopie der Class 0. Der Hidden Class Zeiger des Punktobjekts wird zudem auf diese Kopie Class 1
geändert. In dieser Class 1 wird der Offset für das x und im Speicherbereich des Punktobjekts an entsprechender Stelle gespeichert. Als letztes wird noch
eine sogenannte "Hidden Class Transition" erzeugt, die von der Class 0 auf die Class 1 zeigt. Dieser Übergang wird benutzt, wenn ein Objekt auf die initiale
Klasse zeigt und ein x-Attribut zum Objekt hinzugefügt wird.
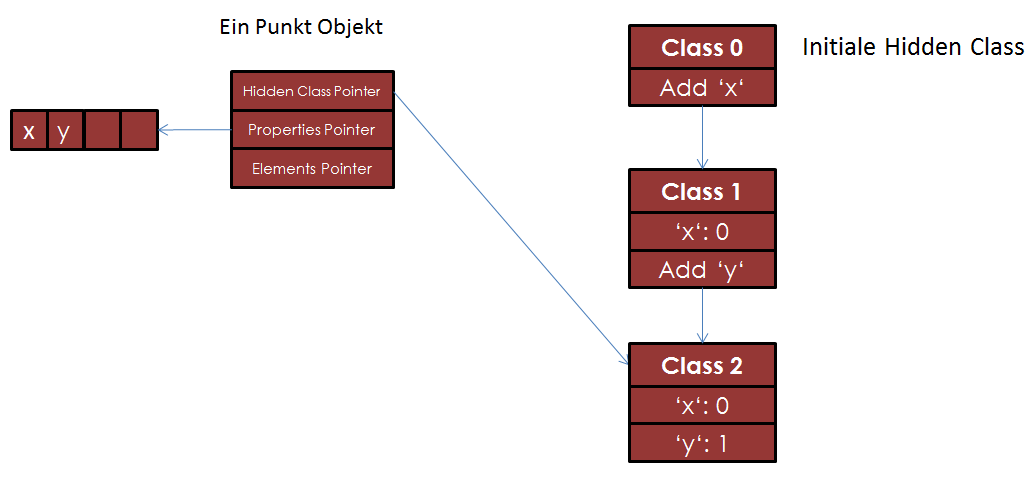
Nun wird noch this.y = y ausgeführt. Hierdurch entsteht eine Kopie von Class 1. Auch der Hidden Class Zeiger wird auf diese Kopie Class 2
geändert. Der Offset in diesem Fall für y ist 1 und wird in der Hidden Class, sowie der enstprechende Wert im Speicherbereich des Objekts, gespeichert. Genau wie beim
ersten Attribut wird wieder eine "Hidden Class Transition" auf die Class 2 erzeugt. In diesem Fall ist der Übergang von Class 1 nach Class 2, wenn
dem Objekt ein y-Attribut hinzugefügt wird.
Abschließend
Würde ein zweites Objekt zunächst ein y-Attribut und dann ein x-Attribut hinzugefügt bekommen, entstehen 2 neue Hidden Classes, da die Zwischenstationen
und Übergänge nicht denen des anderen Objekts ähneln.
Diese Technik bringt einen großen Geschwindigkeitsschub, da der Zugriff auf Attribute deutlich höher ist und nicht soviele Hidden Classes für gleiche Objekte erzeugt werden müssen.
Gerade in einem Codeblock sind meißt Objekte mit identischer Struktur. Dadurch können nun Techniken aus statisch, klassenbasierten Sprachen genutzt werden.
Generierung von nativem Maschinencode mit Inline Caching
In der V8 wird zunächst der komplette Code in nativen Maschinencode übersetzt. Zur Laufzeit werden dann die Zugriffe auf Attribute und Funktionsaufrufe durch Inline-Caching beschleunigt.
Hierbei wird erstmal ein vollständiger Suchvorgang durchgeführt. Danach sind die Hidden Class und Ort von Attribut bzw. Methode bekannt. Darauf aufbauend generiert die V8 Maschinencode,
der für zukünftige Objekte an gleicher Stelle im Code annimmt, dass sie dieselbe Hidden Class besitzen wie zuvor. Wenn dies der Fall ist, können die Eigenschaften direkt geladen werden,
ohne einen langen Suchvorgang durchzuführen. Wenn die Annahme nicht zutrifft, wird der generierte Code entfernt und nach einem erneuten Suchvorgang durch ein neues Stück generierten
Code ersetzt.
Dieser Vorgang erfolgt im monomorphen Zustand. Im megamorphen Zustand werden mehrere generierte Codestücke zur Hilfe genommen, mit dessen Hilfe die V8 schnell entscheiden kann, wo die Attribute
und Methoden liegen.
Inline-Caching Zustände
- Uninitialisiert: In diesem Zustand beginnt jede Anwendung. Es wurden bisher keine Objekte gesehen.
- Monomorph: Es wurde bereits ein Objekt bzw. eine Hidden Class gesehen. Außerdem existiert ein Übergang von Uninitialisiert nach Monomorph.
- Megamorph: Es wurden bereits mehrere Objekte und Hidden Classes gesehen. Dafür wird nun ein Cache von generierten Codestücken genutzt, um die Attribute und Methoden zu finden
Speichermanagement System
Durch die Hidden Classes und das Inline Caching mit Generierung von Maschinencode ist die V8 bereits in der Lage schnellen Zugriff auf
Attribute und Methoden zu gewähren. Sie soll aber auch in der Lage sein, von dem megamorphen Zustand wieder in den monomorphen Zustand zu gelangen. Dazu muss es möglich sein, generierte
Codestücke wieder wegzuwerfen. Hier kommt der Garbage Collector der V8 zum Einsatz.
Der Garbage Collector (kurz GC) ist ein
- Stop-the-world
Der Prozess wird angehalten, damit Speicher bereinigt werden kann.
- exakter
Er weiß jederzeit, wo alle Objekte liegen.
- und Generationeller
Garbage Collector.
2 Generationen
- Junge Generation
In diesem kleinen, zusammenhängenden Speicher werden alle Objekte erzeugt. Wenn diese Generation voll ist, wird diese Generation bereinigt. Dies geschieht sehr oft. Da die meißten
Objekte sehr kurzlebig sind, werden fast alle Objekte in der jungen Generation nach einer Garbage Collection gelöscht. Die Objekte die noch benötigt werden, werden in die alte Generation
verschoben. Nur wenn die Bereinigung der jungen Generation nicht genügend Speicher liefert, wird auch die alte Generation angeschaut.
- Alte Generation
Für diese Generationen werden mehrere Stücke Speicher bereitgestellt. Unter anderem für den ausführbaren Maschinencode, einen Map Bereich für Hidden Classes und für
große Objekte. Die alte Generation wird nur sehr selten angeschaut.
Garbage-Collection-Typen
- Scavenge
Bei diesem Typen wird nur die junge Generation angeschaut und ist damit der Typ, der die ganze Zeit ausgeführt wird. Die durchschnittliche Unterbrechungsdauer liegt bei 2ms.
- Full non-compacting collection
Bei diesem Typ wird der sogenannte Mark-Sweep-Algorithmus ausgeführt. Dieser Algorithmus schaut sowohl in der alten, als auch der jungen, Generation alle Objekte an und markiert diejenigen, die
entfernt werden sollen. Danach werden dann alle markierten Objekte entfernt. Allerdings verursacht dieser Algorithmus Fragmentierung, da Lücken zwischen den Objekten entstehen. Auch ist ein
aufwändiger Algorithmus zum Finden von freien, passenden Speicherstücken notwendig. Daher wird in der Regel der folgende 'Full compacting collection'-Typ genutzt. Die durchschnittliche
Unterbrechungsdauer bei der 'Full non-compacting collection' liegt bei 50ms.
- Full compacting collection
Hier wrd der Mark-Sweep-Compact-Algorithmus genutzt. Dieser macht dasselbe wie der Mark-Sweep-Algorithmus, kopiert danach aber die Objekte so um, dass sie in einem zusammenhängenden Bereich liegen.
Deshalb muss die V8 auch einen exakten GC haben, damit sie alle Zeiger entsprechend verschieben kann, während das Kompaktieren vorgenommen wird. Dies kostet mehr Zeit, erspart aber die
Entwicklung und das Ausführen eines komplexen Suchalgorithmus für freie Speicherstücke. Die durchschnittliche Unterbrechungsdauer liegt bei 100ms.
... [ Seminar Programmiersprachen und virtuelle Maschinen ] ... [ Google's V8 ] ...
[ << Einführung ] ... [ Kürzliche Entwicklungen >> ] ... [ nach oben ] ...